-
InfoPilot von SHI GmbH präsentiert sich in neuem Gewand
Augsburg, Juli 2025 – Die SHI GmbH hat den Webauftritt ihrer Fachverlagsplattform InfoPilot vollständig neu gestaltet und präsentiert sich ab sofort unter www.infopilot.de mit frischem Design und klar strukturierter Benutzerführung. Ziel der Überarbeitung war es, die Seite noch besser an die Anforderungen und Arbeitsweisen von Fachverlagen anzupassen und den Mehrwert der Plattform noch schneller und deutlicher zu vermitteln. Mit der neu gestalteten Webseite stellt SHI alle Funktionen und Vorteile der Fachverlagsplattform InfoPilot in den Mittelpunkt: Von durchgängigem Content Management, der Steuerung und Optimierung von Workflows bis hin zur Sicherung von Datenqualität. Sämtliche Inhalte wurden aktualisiert, überarbeitet und neu geordnet, damit Verlage direkt erkennen, wie sie durch den Einsatz von InfoPilot…
-
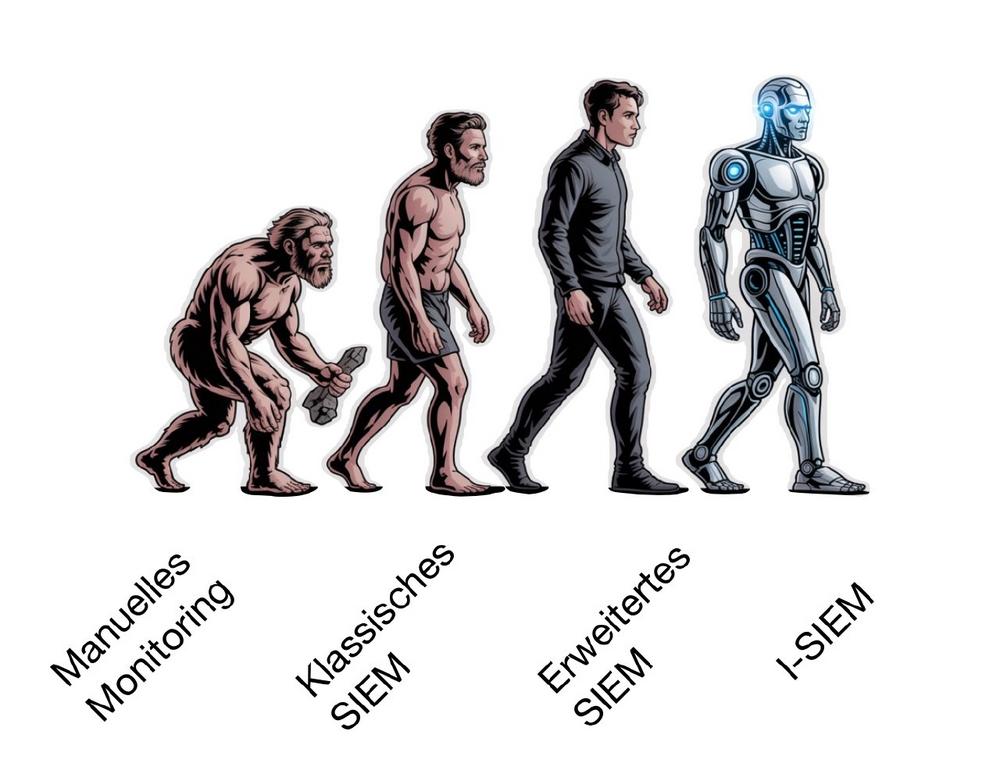
Die Evolution vom Monitoring zum I-SIEM
In den Anfängen der IT-Sicherheit war alles Handarbeit: Administratoren sichteten einzelne Log-Dateien, suchten nach verdächtigen Einträgen und versuchten, Bedrohungen rechtzeitig zu erkennen. Diese Phase des klassischen Monitorings war zeitaufwändig, fehleranfällig und kaum skalierbar. Mit dem exponentiellen Anstieg von Systemen, Anwendungen und Datenmengen wurde schnell klar, dass manuelle Verfahren nicht mehr genügten. Der nächste logische Schritt war das klassische SIEM (Security Information and Event Management). Es sammelte Log- und Event-Daten aus verschiedensten Quellen, korrelierte diese anhand definierter Regeln und gab bei Abweichungen automatisch Alarme aus. Ein gewaltiger Fortschritt gegenüber der reinen Handarbeit – doch mit Nachteilen: Die Pflege der Regeln war aufwendig, die Alarmflut oft hoch, und viele Zusammenhänge blieben trotzdem…
-
Elastic SIEM: Kostenvorteil durch innovatives Lizenzmodell
In der Welt moderner Cybersicherheit gilt meist: je mehr Daten erfasst, korreliert und analysiert werden, desto höher die Kosten. Führende Sicherheitslösungen wie Splunk oder Microsoft Sentinel setzen traditionell auf eine volumenbasierte Lizenzierung – sie rechnen ab nach der Anzahl der Events, prozentual nach Events per Second (EPS) oder direkt nach dem Gesamtvolumen in Gigabyte pro Tag. Was zunächst einfach klingt, wird für Unternehmen jedoch schnell zum Kostenproblem: Sobald Log-Datenmengen, Telemetrie oder zusätzliche Datenquellen wachsen, steigen auch die Lizenzgebühren ungebremst. Elastic Security verfolgt einen grundlegend anderen Ansatz – und verschafft Unternehmen damit deutliche Kostenvorteile. Statt Datenvolumen oder Eventzahlen in Rechnung zu stellen, basiert das Lizenzmodell von Elastic Security auf Ressourcenverbrauch, konkret…
-
Cloudera im technischen Großhandel
Der technische Großhandel steht vor der Herausforderung, ein komplexes Sortiment mit stark schwankender Nachfrage effizient vorzuhalten, um gleichzeitig Lieferfähigkeit und Lagerkosten im Gleichgewicht zu halten. Cloudera unterstützt dabei durch seine Datenplattform, die speziell auf Echtzeitverarbeitung und Advanced Analytics ausgerichtet ist. 1. Bestandsoptimierung in Echtzeit Cloudera ermöglicht es, Lagerbestände kontinuierlich mit Echtzeitdaten aus ERP-Systemen, Wareneingängen, Bestellungen, IoT-Sensoren oder Lieferkettenpartnern abzugleichen.So können Algorithmen laufend den optimalen Lagerbestand berechnen: * Überwachung von Abverkaufsraten, Saisonalitäten und Kundentrends * Automatisierte Nachbestellungen, sobald definierte Schwellenwerte unterschritten werden * Frühzeitige Identifikation von Ladenhütern oder Überbeständen zur Vermeidung von Kapitalbindung 2. Lageroptimierung durch integrierte Analysen Die Cloudera Data Platform (CDP) erlaubt die Zusammenführung und Analyse von Daten aus…
-
SHI GmbH – Softwareentwicklung aus Augsburg
Mit ihrer langjährigen Erfahrung als Fullstack-Entwickler präsentiert SHI GmbH aus Augsburg einen umfassenden Service im Bereich der Web‑App Programmierung. Die erfahrene 360‑Grad-IT‑Schmiede aus der Fuggerstadt vereint Beratung, Konzeption und technische Umsetzung in einem transparenten, agilen Prozess. Digitale Transformation – einfach gemacht Web‑Applikationen, entwickelt von SHI, ermöglichen Mitarbeitenden und Unternehmen maximale Flexibilität: Sie sind browserbasiert, plattformunabhängig und barrierefrei zugänglich – im Büro, Homeoffice oder unterwegs mit Smartphone, Tablet oder Laptop. Einfache Bedienung trifft auf modernste Technologien (Java, Angular, React, JSF, PHP, HTML, CSS, JavaScript), um intuitive Nutzererfahrungen zu realisieren. Der SHI‑Vorteil: Prozess und Leistung aus einer Hand SHI begleitet Kunden durch fünf präzise abgestimmte Projektphasen: Beratung – ganzheitliche Analyse und ehrliche…
-
Wie Pharmaunternehmen mit OpenSearch ihre Daten zurückerobern
Pharmaunternehmen stehen heute vor der Herausforderung, eine wachsende Menge heterogener Datenquellen effizient auszuwerten – von klinischen Studien über Forschungsberichte bis hin zu Produktions-, Lieferketten- und Qualitätsdaten. Gerade in einer Branche, in der regulatorische Anforderungen hoch sind und Entscheidungen oft schnell auf verlässlichen Daten basieren müssen, ist der Aufbau einer flexiblen und leistungsfähigen Such- und Analyseplattform entscheidend. Immer mehr Unternehmen setzen dafür auf OpenSearch, eine offene Such- und Analytics-Engine, die sich durch Skalierbarkeit, Anpassungsfähigkeit und Kosteneffizienz auszeichnet. OpenSearch ermöglicht es, strukturierte und unstrukturierte Daten in Echtzeit zu indexieren und auszuwerten. Pharmaunternehmen nutzen diese Fähigkeit beispielsweise, um große Textsammlungen aus Forschungsprojekten oder klinischen Studien schnell durchsuchen und miteinander in Beziehung setzen zu…
-
Einsatz von Elasticsearch im mittelständischen Maschinenbau
Mittelständische Maschinenbauunternehmen stehen täglich vor der Herausforderung, große Mengen technischer Daten, Dokumentationen, CAD-Zeichnungen und Servicedokumente effizient zu durchsuchen und nutzbar zu machen. Konstrukteure, Servicetechniker und Projektleiter müssen schnell auf spezifische Informationen zugreifen können, um Entscheidungen zu treffen, Ersatzteile zu identifizieren oder Kundenanfragen zu beantworten. Klassische Datenbanksuchen stoßen dabei häufig an Grenzen, da sie meist nur exakte Treffer liefern und keinen inhaltlichen Zusammenhang erkennen. Genau hier setzt der Einsatz von Elasticsearch an: Als leistungsfähige Such- und Analyse-Engine erlaubt sie nicht nur eine schnelle Volltextsuche über Millionen Dokumente, sondern auch die Nutzung moderner Funktionen wie semantischer Suche, Autovervollständigung und Relevanzbewertung. Im Kern ist Elasticsearch eine verteilte, auf JSON-Dokumenten basierende Suchmaschine, die Daten…
-
Einsatz eines RAG-Systems für interne Wikis
Verlage verfügen über eine immense Menge an internem Wissen: Stilrichtlinien, Autorenprofile, Vertriebsstrategien, rechtliche Hinweise und viele weitere Dokumentationen sind meist in einem umfangreichen internen Wiki abgelegt. Die größte Herausforderung liegt darin, dieses Wissen für Mitarbeiter schnell und präzise zugänglich zu machen. Herkömmliche Schlagwortsuchen stoßen dabei oft an ihre Grenzen, da sie keine vollständigen, kontextbasierten Antworten liefern können. Genau hier setzt die Integration eines Retrieval-Augmented-Generation-Systems, kurz RAG-System, an. Es kombiniert die Leistungsfähigkeit einer semantischen Suche mit einem generativen Sprachmodell und kann so aus großen Wissensbeständen passgenaue Antworten in natürlicher Sprache generieren. Ein RAG-System arbeitet dabei in zwei Schritten: Zunächst sucht ein sogenannter Retriever in der gesamten Dokumentenbasis – in diesem Fall…
-
Innovative Suchlösungen & KI-Kompetenz: Maßgeschneiderte Services für die digitale Zukunft
Als langjähriger Elastic-Partner unterstützt die SHI GmbH Unternehmen bei der Umsetzung leistungsstarker Such- und Analyseplattformen – individuell zugeschnitten auf Business-, Security- oder Observability-Anforderungen. Das Angebot reicht von der Beratung über die Architektur und Implementierung bis hin zum laufenden Betrieb und zur Wartung. Im Fokus stehen moderne Suchtechnologien: Ob klassische Volltext- und Facettensuche, KI-basierte Vektorensuche oder Natural Language Processing – SHI entwickelt hochverfügbare, fehlertolerante und skalierbare Lösungen auf Basis der Elastic Stack. Auch bei der Datenmodellierung und Indexierung unterstützt SHI gezielt, um die Grundlage für schnelle und relevante Suchergebnisse zu schaffen. Darüber hinaus bietet SHI umfassende Services für Performance-Optimierung, Cluster-Analyse, Query-Tuning und Sharding-Strategien. Individuelle Dashboards in Kibana, inklusive Visualisierung von Angriffsmustern…
-
Ein Blick in die Zukunft der KI: Einführung in Retrieval-Augmented Generation (RAG)
In der rasanten Welt der Technologie und künstlichen Intelligenz (KI) haben Large Language Models (LLMs) bereits viele beeindruckende Fortschritte erzielt. Diese Modelle, die mit riesigen Datenmengen trainiert wurden, sind in der Lage, eine Vielzahl von Aufgaben zu bewältigen, darunter das Beantworten von Fragen, das Erstellen von Dokumentensummen (Textzusammenfassungen), das Übersetzen von Texten in verschiedene Sprachen und natürlich die Generierung von Text. Doch trotz ihrer Vielseitigkeit und Leistungsfähigkeit stoßen LLMs auf gewisse Einschränkungen, die ihre Zuverlässigkeit und Aktualität beeinträchtigen. Hier kommt Retrieval-Augmented Generation (RAG) ins Spiel – eine innovative Methode, die einige dieser Herausforderungen elegant löst. Inhaltsverzeichnis 1. Eigenschaften und Einschränkungen von Large Language Models (LLMs) Eigenschaften von LLMs Einschränkungen von…