-
❌ CMMC 2.0 sicher umsetzen ❌ Wie moderne Datenmaskierung den Schutz von CUI unterstützt ❗
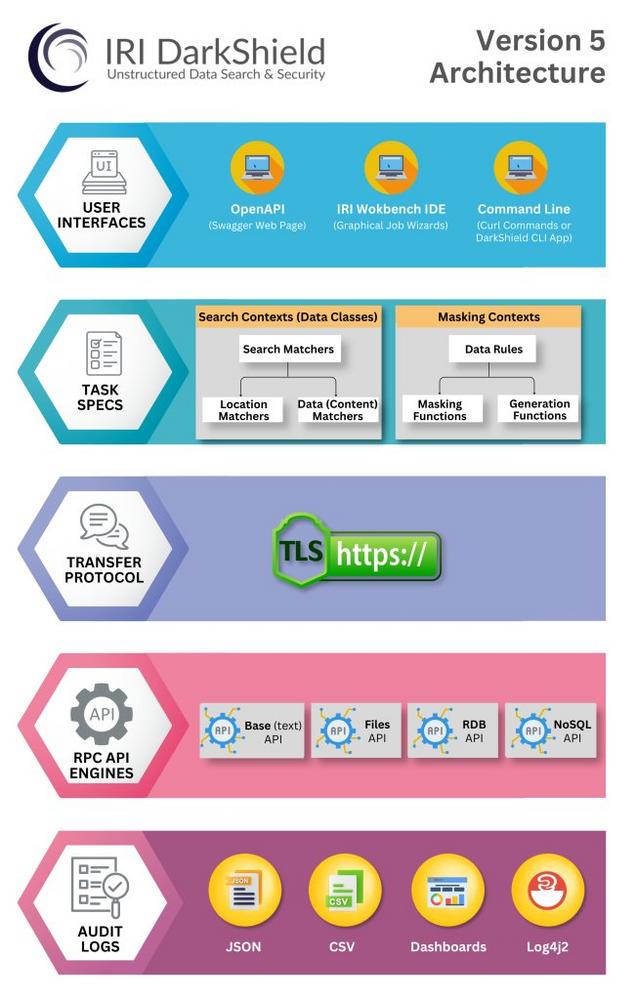
Warum Datenerkennung und Datenmaskierung für CMMC wichtig sind Viele CMMC-Kontrollen setzen voraus, dass Unternehmen: FCI und CUI zuverlässig identifizieren können – auch in strukturierten, semi-strukturierten und unstrukturierten Daten, sensible Daten in Test-, Analyse- oder Entwicklungsumgebungen minimieren, das Prinzip Least Privilege durchsetzen, nachvollziehbare und auditierbare Schutzmaßnahmen bereitstellen. Manuelle Prozesse oder isolierte Tools sind dafür meist nicht ausreichend – besonders in hybriden, Cloud- oder Legacy-Umgebungen, wie sie in der Verteidigungsindustrie häufig vorkommen. Überblick über IRI-Funktionen für Datenerkennung und Maskierung IRI bietet einen integrierten Ansatz zum Schutz sensibler Daten: IRI DarkShield automatische Suche, Klassifizierung und Maskierung sensibler Daten unterstützt CUI, PII, PHI, PCI und geistiges Eigentum arbeitet mit Dateien, Dokumenten, Bildern, Datenbanken und…
-
❌ Gesundheitsdaten finden und schützen ❌ Der sichere Umgang mit HL7, DICOM und X12-EDI-Dateien ❗
Mehrschichtige Herausforderung für Datenschutz und Compliance: Gesundheitsdaten gehören zu den sensibelsten Informationen überhaupt. Entsprechend hoch sind die Anforderungen an Sicherheit, Governance und Compliance – insbesondere im Rahmen der Datenschutz-Grundverordnung (DSGVO). Doch die Herausforderung ist mehrschichtig: 1. Identifikation sensibler Daten: Personenbezogene Gesundheitsinformationen müssen zuverlässig erkannt werden – auch in komplexen Formaten und großen Datenbeständen. 2. Klassifizierung kritischer Inhalte: Nach der Identifikation folgt die korrekte Einstufung, welche Daten sind personenbezogen und welche fallen unter besondere Kategorien der DSGVO? 3. Maskierung und Schutz: Sensible Daten müssen datenschutzkonform anonymisiert, pseudonymisiert oder maskiert werden – ohne die Nutzbarkeit für Tests, Analysen oder Entwicklung zu verlieren. Branchenformate im Gesundheitswesen: Sensible Informationen sind häufig tief in spezialisierten…
-
❌ Daten in Excel schützen ❌ Datenschutz in Excel neu gedacht – ohne unsichere Passwortlösungen ❗
Datenschutz in Excel neu gedacht: Verlassen Sie sich nicht länger auf Tabellen-Passwörter, die längst kein verlässlicher Schutz mehr sind. Wenn es um sensible Daten geht, braucht es mehr als reine Zugriffsbeschränkungen. Mit IRI CellShield heben Sie den Datenschutz in Microsoft Excel auf ein neues Niveau – wirksam, kontrollierbar und nahtlos in Ihre gewohnte Arbeitsumgebung integriert. Sensible Daten schützen – ohne sie unbrauchbar zu machen! Statt Informationen lediglich zu sperren, maskieren Sie kritische Inhalte gezielt und regelbasiert. Realistische, aber fiktive Ersatzwerte sorgen dafür, dass Ihre Tabellen weiterhin für Tests, Analysen, Entwicklung und Datenaustausch genutzt werden können – ohne dabei echte personenbezogene oder geschäftskritische Inhalte offenzulegen. Ihre Vorteile mit CellShield: 1. Automatisches…
-
❌ IBM Informix ❌ Zentrales Datenmanagement mit hoher Sicherheit, Performance und Zukunftsfähigkeit ❗
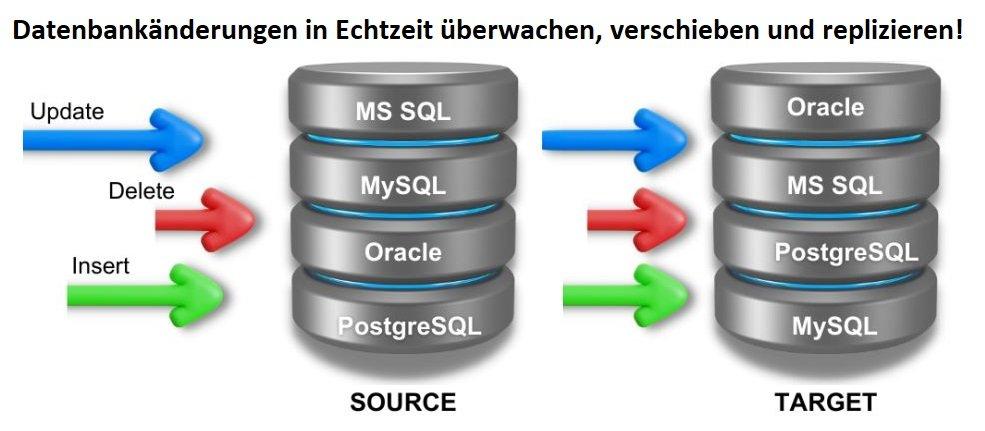
Mit der IRI Workbench steht eine zentrale, plattformübergreifende Umgebung zur Verfügung, um Daten aus IBM Informix Informix effizient zu analysieren, zu integrieren, zu schützen und weiterzuverarbeiten. Die kostenlose Lösung läuft unter Windows, macOS und Linux und vereint alle relevanten Datenmanagement-Funktionen in einer intuitiven, Eclipse-basierten Konsole! Die IRI Workbench optimiert die Verarbeitung von Informix-Tabellenquellen und -zielen und unterstützt leistungsstarke ETL-, Migrations- und Replikationsszenarien. Durch die Integration mit IRI CoSort- und Hadoop-Engines lassen sich große Datenmengen performant transformieren, analysieren und absichern. Zusätzlich ermöglicht die Plattform Change Data Capture (CDC) zur Echtzeit-Erfassung von Datenänderungen aus Informix-Systemen. Ebenso ist die Anbindung an führende relationale Datenbanksysteme wie MS SQL, Oracle, PostgreSQL, Salesforce, Snowflake und Teradata…
-
❌Oracle Daten wirksam schützen❌ Echtzeit-Schutz durch intelligente, dynamische Maskierung in Oracle-Datenbanken ❗
Oracle-Daten in Echtzeit schützen: Heben Sie Ihre Datensicherheit auf ein neues Niveau, denn IRI Ripcurrent kombiniert leistungsstarke Replikation mit intelligenter, dynamischer Datenmaskierung – speziell für Oracle-Datenbanken entwickelt. In Verbindung mit der zentralen IRI Workbench steuern Sie sämtliche Prozesse komfortabel, transparent und effizient. Der integrierte Schema Data Class Wizard identifiziert sensible Daten automatisch, weist sie passenden Datenklassen zu und verknüpft sie direkt mit den richtigen Maskierungsregeln. So entstehen sofort einsatzbereite Maskierungs-Workflows mit FieldShield – schnell implementiert, präzise umgesetzt und DSGVO-konform. Das besondere Plus: Keine manuellen Anpassungen mehr. Ripcurrent erkennt neue Tabellen und Spalten automatisch und synchronisiert Änderungen in Echtzeit – ohne Unterbrechung des Betriebs. Ideal für Test- und Produktionsumgebungen, in denen…
-
❌ Optimale Datenqualität ❌ Nachhaltige Datenqualität als Grundlage für verlässliche Entscheidungen ❗
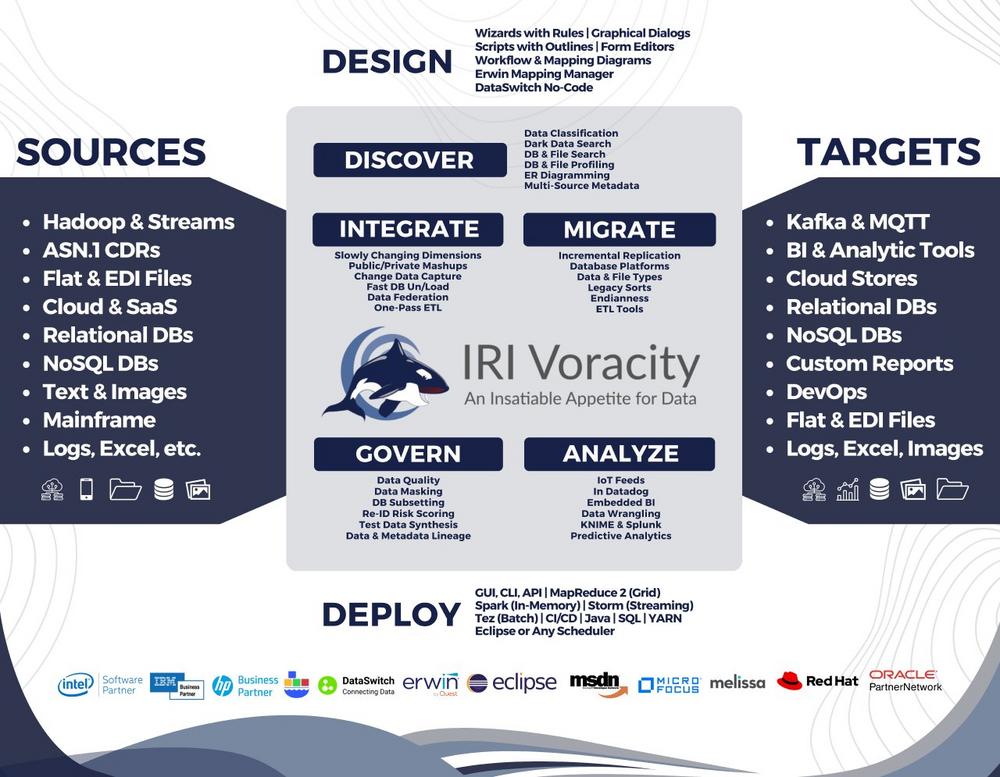
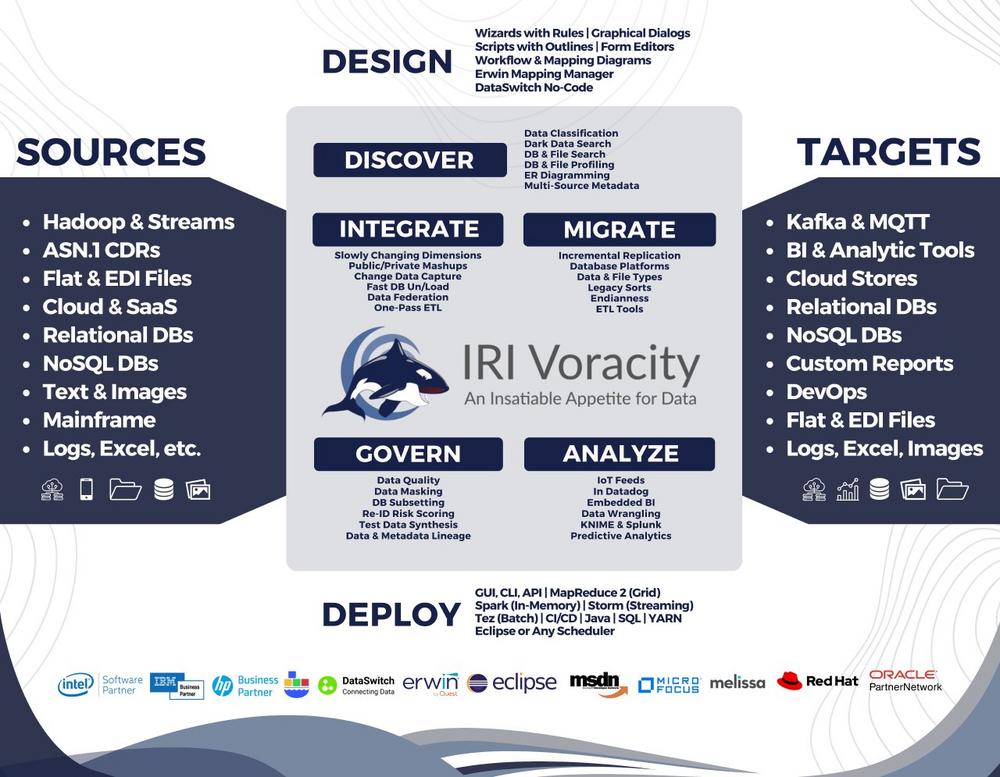
Hochwertige Daten sind ein zentraler Erfolgsfaktor für verlässliche Analysen, effiziente Geschäftsprozesse und eine nachhaltige Kostenkontrolle. Unzureichende Datenqualität führt häufig zu Fehlentscheidungen, redundanten Datenbeständen und ineffizienten Abläufen. Da Datenqualität in vielen Organisationen lange Zeit als nachrangiges Thema behandelt wurde, werden Probleme oft erst dann adressiert, wenn sie bereits operative oder wirtschaftliche Auswirkungen haben. Eine nachhaltige Sicherstellung der Datenqualität erfordert daher sowohl regelmäßige Prüfungen und Korrekturen bestehender Daten als auch eine prozessorientierte Qualitätssicherung, bei der Fehler bereits bei der Datenerfassung vermieden werden. IRI Voracity unterstützt diesen ganzheitlichen Ansatz mit leistungsstarken Funktionen zur Datenbereinigung und Datenanreicherung für strukturierte, semi-strukturierte und unstrukturierte Datenquellen. Mithilfe regelbasierter Workflows werden Inhalte auf Datentypen, Formate, Muster, Wertebereiche und…
-
❌ Datenmigration ohne Verluste ❌ Legacy-Daten konsistent über Dateien und Datenbanken hinweg sicher migrieren ❗
Eine sichere Datenmigration entscheidet sich oft an unscheinbaren technischen Details. Bevor Daten aus Legacy-Systemen in moderne Anwendungen, Datenbanken oder Cloud-Ziele überführt werden, lohnt sich deshalb ein genauer Blick auf Codierungen, Datentypen und Strukturen. Schon ein kurzer Scan der Quelldaten kann gemischte Zeichencodierungen innerhalb einzelner Spalten aufdecken – ein klassischer Stolperstein bei späteren Konvertierungen. Ebenso wichtig ist ein sogenannter Round-Trip-Test: Wird eine Datenstichprobe ins Zielformat konvertiert und anschließend wieder zurückgeführt, zeigen sich potenzielle Probleme sofort. Gerade bei Unicode-Formaten wie UTF-16 müssen zudem Surrogatpaare korrekt übernommen werden, da sonst Zeichen verloren gehen oder beschädigt ankommen. Zusätzliche Sicherheit bieten Prüfsummenvergleiche vor und nach der Migration, insbesondere bei geschäftskritischen Feldern. Und schließlich sollte nicht…
-
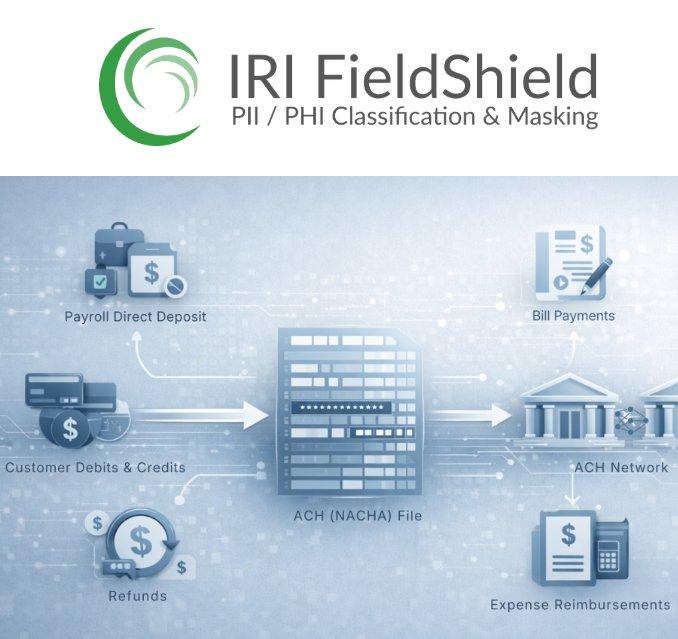
❌ ACH-Dateien schützen ❌ DSGVO-konformer Schutz sensibler ACH-Zahlungsdaten mit IRI FieldShield ❗
Schutz von ACH-Dateien: ACH-Dateien (NACHA-Dateien) sind ASCII-Textdateien mit fester Feldlänge, die zur Abwicklung elektronischer Zahlungsverkehrsprozesse über das Automated Clearing House Network genutzt werden. Sie bündeln Transaktionen wie Gehaltszahlungen per Direktüberweisung, Lastschriften, Gutschriften, Rückerstattungen und Spesenabrechnungen sowie zur Validierung von Bankkontodaten. Eine ACH-Datei besteht aus mehreren Transaktionsbatches und ist in 94 Zeichen lange Datensätze gegliedert, deren Struktur und Reihenfolge durch die NACHA-Regeln definiert sind. Die Datensätze umfassen Datei- und Batch-Header, detaillierte Transaktionsinformationen, optionale Zusatzinformationen sowie Kontrollsätze zur Summen- und Validierungsprüfung. Mit IRI FieldShield lassen sich ACH- (NACHA-)Dateien gezielt und datenschutzkonform schützen. Das Tool ermöglicht die strukturierte Maskierung sensibler Felder wie Kontonummern, Namen oder Identifikatoren, ohne dabei das feste Dateiformat oder die…
-
❌ Skalierbare Datenredaktion ❌ Datenschutzkonformes Schwärzen von sensiblen Dokumenten ❗
Mit dem exponentiellen Wachstum von Datenmengen in Bereichen wie Forschung, Softwaretests, Data Science, Advanced Analytics und künstlicher Intelligenz wächst auch die Angriffsfläche für Datenschutzverletzungen. Unternehmen verarbeiten heute Milliarden von Datensätzen, umfangreiche Log- und Eventdaten sowie riesige Archive unstrukturierter Dokumente. Klassische Datenschutzmaßnahmen, manuelle Redaktionsprozesse oder punktuelle Maskierungslösungen sind für diese Anforderungen weder skalierbar noch betrieblich beherrschbar. Datenschutz in Big-Data-Umgebungen ist daher primär eine technische Skalierungs- und Integrationsfrage. IRI DarkShield wurde genau für diesen Kontext entwickelt und stellt eine hochperformante Redaktions- und Data-Masking-Engine für große, heterogene Datenlandschaften dar. Der Fokus liegt auf der automatisierten, reproduzierbaren und regelbasierten Entfernung bzw. Maskierung sensibler Inhalte aus strukturierten, semi-strukturierten und unstrukturierten Daten – unabhängig von Format,…
-
❌ Datenmaskierung ❌ Der Schlüssel zum sicheren Arbeiten mit sensiblen Informationen im BFSI-Sektor ❗
Die Banking-, Finanzdienstleistungs- und Versicherungsbranche (BFSI) verarbeitet täglich enorme Mengen personenbezogener Daten (PII) sowie hochsensibler Finanzinformationen. Diese reichen von nationalen Identifikationsnummern, Kontodaten und Kreditwürdigkeitsinformationen bis hin zu Finanztransaktionen und Kreditunterlagen. Angesichts zunehmender Cyberbedrohungen und immer strengerer regulatorischer Vorgaben ist die Absicherung dieser Daten in Produktiv-, Test- und Speicherumgebungen zu einer geschäftskritischen Priorität geworden. Datenmaskierung stellt dabei eine zentrale Schutzschicht dar, da sie es Unternehmen ermöglicht, mit Daten zu arbeiten, ohne die tatsächlichen Werte offenzulegen. Im Folgenden werden zentrale Einsatzbereiche beschrieben, in denen Datenmaskierung im BFSI-Sektor aktiv genutzt wird, um Innovation zu fördern, regulatorische Anforderungen zu erfüllen und Risiken zu reduzieren. Schutz von Testdaten in DevOps und QA: Banken und Versicherungen…