-
❌ Oracle Datenbank klonen und schützen ❌ Via Commvault klonen und automatische Datenmaskierung für DSGVO-konforme Daten ❗
Sicherheitsorientiertes Datenbank-Klonen leicht gemacht: IRI FieldShield® sorgt dafür, dass sensible Informationen in einer geklonten Datenbank maskiert werden, bevor die Daten für Entwicklungs- und Qualitätskontrollzwecke verwendet werden können! Nachdem Sie eine Oracle-Datenbank geklont haben, können Sie die Commvault-Software nutzen, um unsere Datenmaskierung über ein integriertes Plug-In anzuwenden. Die Integration der Commvault-Software mit unserem IRI FieldShield® ermöglicht dies. Eine detaillierte Anleitung finden Sie in Commvault V11 hier ab Service Pack 15 bis 19 unter dem Titel "Konfiguration der Drittanbieter-Datenmaskierung für Oracle-Datenbankklone". Aber was genau ist FieldShield? IRI FieldShield® ist eine leistungsstarke und kostengünstige Software, die es ermöglicht, personenbezogene Daten (PII) in strukturierten und semistrukturierten Datenquellen, unabhängig von ihrer Größe, zu erkennen und…
-
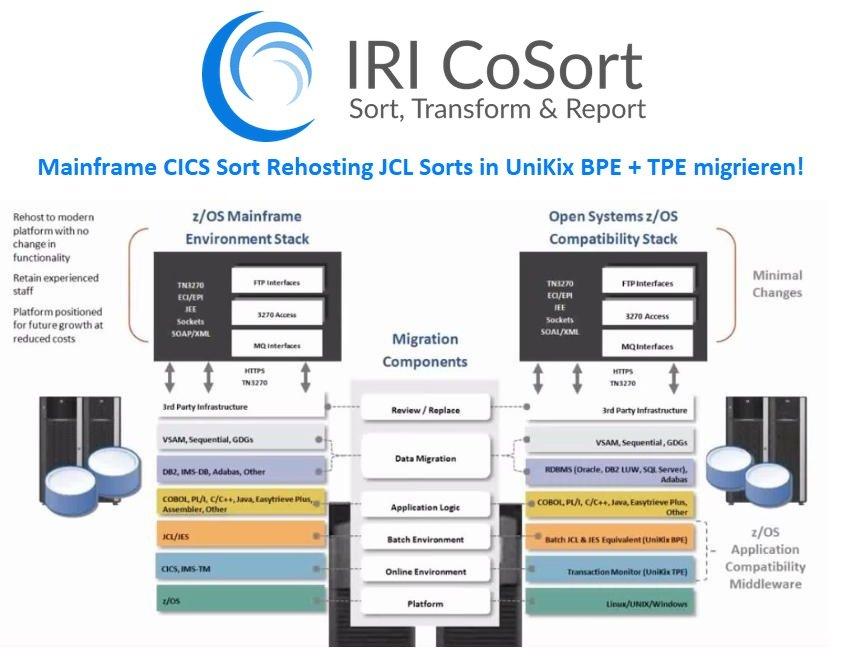
❌ UniKix BPESort ❌ Beschleunigung von UniKix Mainframe Re-hosting Batch-Sortierung (BPE) ❗
Rehosting von Mainframeanwendungen: Die Migration von Mainframe-Anwendungen und -Datenverarbeitungssystemen zu "offenen Systemen" ist ein bedeutender Schritt für viele Unternehmen. Bei dieser Migration kann es zu verschiedenen Herausforderungen kommen, und eine dieser wichtigen Herausforderungen betrifft die Sortier- und Verarbeitungsschritte, die im Mainframe-Umfeld mittels JCL (Job Control Language) durchgeführt werden. Hier kommt IRI CoSort ins Spiel. IRI CoSort ist eine bewährte Lösung für die Migration von Legacy-Sortiersoftware und die Modernisierung von Anwendungen, die auf dem Mainframe laufen. Eines der Hauptprobleme bei der Migration besteht darin, JCL-Sortierschritte in eine Form zu überführen, die auf offenen Systemen wie Unix oder Windows funktioniert. CoSort bietet eine Lösung für diese Konvertierung und ermöglicht es, die Sortieraufgaben…
-
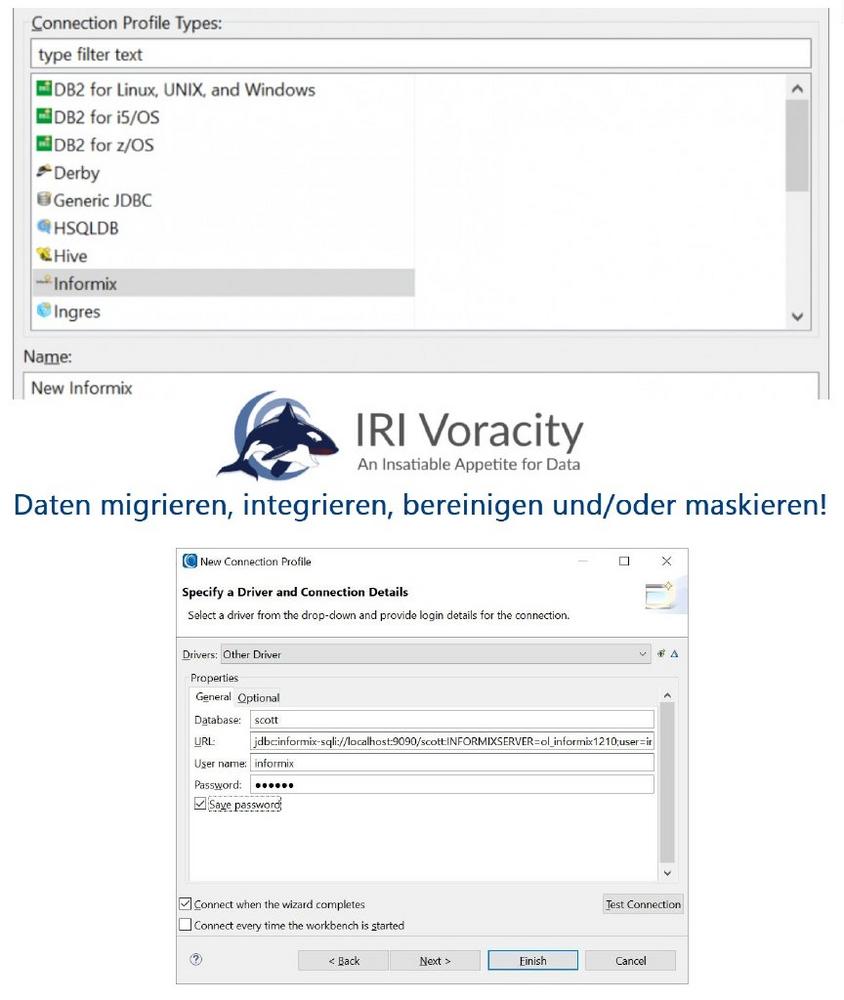
❌ IBM Informix ❌ Beschleunigung von ETL und erweiterte Datensicherheit für DSGVO-konforme OLTP-Daten ❗
IBM Informix: Datenmanagement und Datensicherheit! IRI Workbench™ ist eine kostenlose grafische Benutzeroberfläche und integrierte Entwicklungsumgebung für IRI-Datenmanagement- und Schutzsoftwareprodukte. Sie ist für Windows, MacOS und Linux verfügbar und bietet schnelleres Datenmanagement und höchste Datensicherheit in einer Konsole. Die Workbench steuert Aufträge mithilfe von IRI CoSort und Hadoop Engines und nutzt die Funktionen von Eclipse™. Der Artikel dokumentiert die Verbindungen, die benötigt werden, um mit 64-bit Informix Dynamic Server (IDS) Tabellenquellen und -zielen in IRI Workbench und 64-bit CoSort-kompatiblen Runtime-Umgebungen zu arbeiten. Diese Schritte ähneln denen für andere RDBMS-Verbindungen, wie MS SQL, Oracle, PostgreSQL, Salesforce, Snowflake und Teradata. End-to-End Datenmanagement umsetzen, Alles innerhalb nur einer Konsole: Datenermittlung, Profilerstellung, Klassifizierung und Metadatendefinition.…
-
❌ Testdaten für TDM ❌ Umfassendes Testdatenmanagement-Framework für DevOps, MLOps und DataOps bereitstellen ❗
Testdatenmanagement: Erzeugen von authentischen Daten! In diesem Artikel wird gezeigt, wie man realitätsnahe Daten synthetisiert, um ein vollständiges Datenbankschema mit referenzieller Integrität in einem einzigen Schritt zu befüllen. IRI RowGen generiert Datensätze in verschiedenen Formaten, darunter Flat-Files, Datenbanktabellen und Berichte. Dies geschieht entweder durch zufällige Erzeugung von Werten in bestimmten Datentypen, Bereichen und Verteilungen oder durch die zufällige Auswahl von Daten aus Nachschlagetabellen oder externen "Set-Dateien". Die Wahl zwischen diesen beiden Methoden kann ad hoc getroffen werden oder basierend auf Spaltenregeln, die über verschiedene Tabellen hinweg gelten. Die Verwendung von Set-Dateien ermöglicht die Erzeugung realistischer Daten für Spalten, die Namen, Orte, Adressen und andere nicht-numerische Werte enthalten. IRI stellt einige…
-
❌ Microsoft Azure Blob Storages ❌ Binary Large Objects (BLOBs) für leistungsfähiges Data Lake ❗
Datenverlust verhindern: PII und andere sensible Daten finden und verschleiern! IRI DarkShield ist ein leistungsstarkes Werkzeug zur Datenmaskierung, das entwickelt wurde, um sensible Informationen in halbstrukturierten und unstrukturierten Dateien sowie Datenbanken aufzuspüren und zu anonymisieren. Es werden zwei robuste Remote Procedure Call (RPC) Application Programming Interfaces (APIs) bereitgestellt: die "Base" DarkShield API und die DarkShield-Files API. Diese APIs ermöglichen die Identifizierung und Schutz sensibler Daten in verschiedenen Quellen, indem sie spezifische Suchmuster und Maskierungsregeln gemäß den Geschäftsvorschriften anwenden. Weitere Informationen zur Erstellung solcher Suchmuster und Maskierungsregeln finden Sie in einem separaten Artikel. Die DarkShield-Base-API wird verwendet, um unstrukturierten Text außerhalb von Dateien zu suchen und zu maskieren. Im Gegensatz…
-
❌ Big Data Wegbereiter ❌ Lösungen zum Verpacken, Schützen und Bereitstellen von Daten für Analysen, ML/AI und DevOps ❗
Big Data 75: Companies Driving Innovation in 2023! Die Zeitschrift Database Trends and Applications (DBTA) hat Innovative Routines International (IRI), Inc. auch bekannt als The CoSort Company, in ihre Liste der "Big Data 75: Companies Driving Innovation in 2023" aufgenommen. Die Liste wurde in der Big Data Quarterly (BDQ)-Ausgabe der DBTA veröffentlicht, um Unternehmen bei der Bewältigung neuer Herausforderungen und eines sich schnell entwickelnden Big-Data-Ökosystems zu unterstützen", indem sie Unternehmen vorstellt, die Innovationen vorantreiben und die Möglichkeiten bei der Erfassung, Speicherung und Gewinnung von Werten aus Daten erweitern". Laut DBTA-Chefredakteurin Stephanie Simone haben "KI-Technologien in diesem Jahr unmittelbar an Zugkraft gewonnen … das Zugpferd, um das man sich hinter…
-
❌ Startpunktsicherheit ❌ Die wichtige Ergänzung zu Endpunktsicherheit für den umfassenden Datenschutz ❗
Big Data Management seit 40 Jahren: In diesem Artikel wird definiert, was wir als "Startpunktsicherheit" bezeichnen möchten, und zwar hauptsächlich durch einen Vergleich mit der Endpunktsicherheit. Wir hören immer wieder von Endpunktsicherheit. Es handelt sich dabei um Technologien zum Schutz sensibler Daten an bestimmten Punkten in einem Netzwerk. Die Endpunktsicherheit umfasst mobile Geräte, Laptops und Desktop-PCs sowie die Server und Netzwerkgeräte, über die sie verbunden sind. Sie kann sich auch auf Speichergeräte wie Daumen- und Festplattenlaufwerke und sogar auf noch granularere Punkte innerhalb dieser Geräte beziehen, einschließlich Ordnern, Dateien und ganzen Datenbanken, die beispielsweise verschlüsselt werden können. Aber wie sieht es mit der Sicherung von Daten an ihren Ausgangspunkten aus,…
-
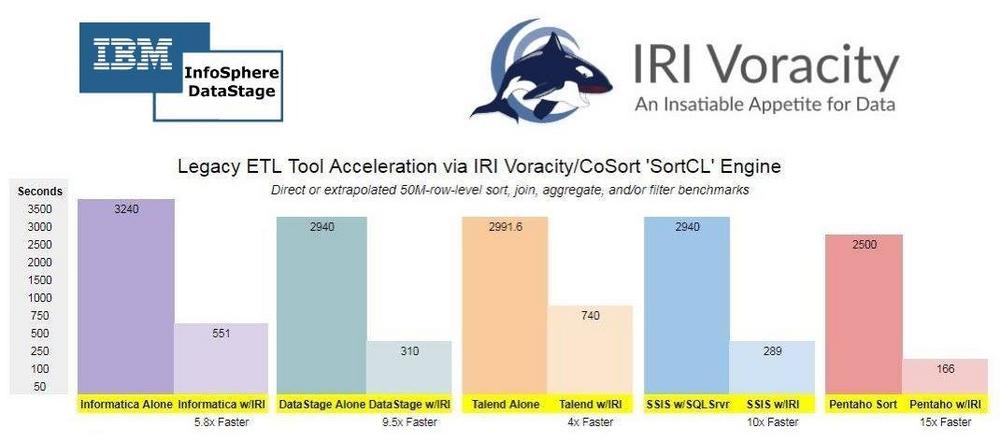
❌ IBM Infosphere Datastage ❌ Datenintegration von ETL-Tool Datastage nahtlos 10x schneller und sensible Daten schützen ❗
Big Data Management seit 40 Jahren: Selbst nach Anwendung von Tuning-Maßnahmen ist die Transformation großer Datensätze (über eine Million Zeilen) in DataStage immer noch zeitaufwendig, insbesondere ohne teure Hardware-Upgrades oder Aktualisierungen der Software. Besonders rechenintensive Aufgaben wie Sortieren, Zusammenführen, Aggregieren und Laden großer Datenmengen können zu Engpässen führen. Die Parallelisierung oder Optimierung in anderen Schichten oder Werkzeugen kann umständlich und kostenintensiv sein und gleichzeitig die Leistung für andere Benutzer beeinträchtigen. In Bezug auf die Datensicherheit können die von IBM angebotenen Lösungen zur Datenmaskierung teuer oder umständlich sein und nicht alle Anforderungen für die Identifikation personenbezogener Daten (PII) oder den Datenschutz erfüllen. Beschleunigung von DataStage-Transformationen: Um die Leistung von DataStage zu…
-
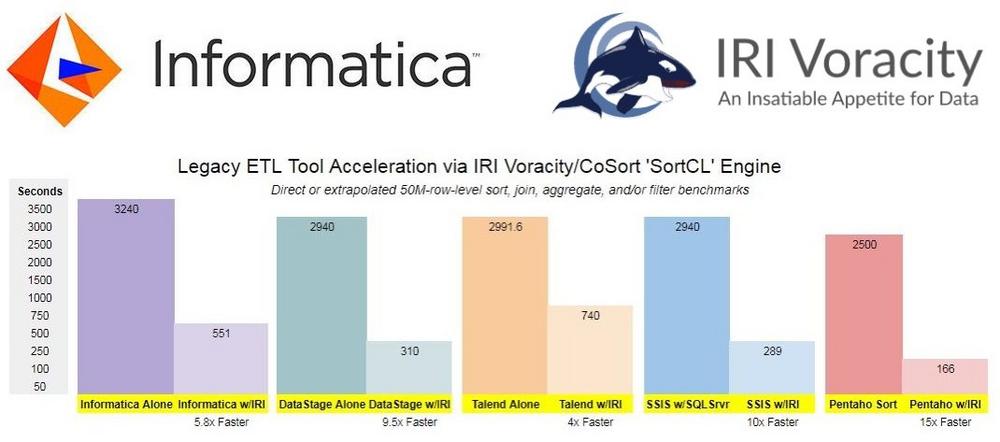
❌ ETL und ELT via Informatica ❌ Nahtlose Beschleunigung via Pushdown-Optimierung und Datenschutz DSGVO-konform gewährleisten❗
Push von Informatica: ETL- und ELT-Jobs einfach beschleunigen oder neu gestalten! Eine Möglichkeit zur Optimierung Ihrer Informatica ETL-Jobs besteht darin, sie zu beschleunigen oder neu zu gestalten. Bei der Verarbeitung großer Datenmengen in PowerCenter können verschiedene Herausforderungen auftreten, die zu Verzögerungen führen können. Dies kann insbesondere bei Operationen wie Sortieren, Verknüpfen, Aggregieren und Laden von Daten auftreten. Eine erste Option zur Optimierung ist die sogenannte "Pushdown-Optimierung", bei der die Verarbeitungslast auf eine bereits beanspruchte Datenbank oder eine teure und komplexe Plattform verschoben wird. Ein weiteres dringendes Anliegen besteht darin, die Sicherheit sensibler Produktionsdaten sicherzustellen, die durch Informatica Data Warehouse, Data Mart oder Testbetrieb übertragen werden. Dies erfordert möglicherweise rollenbasierte Datensicherungen…
-
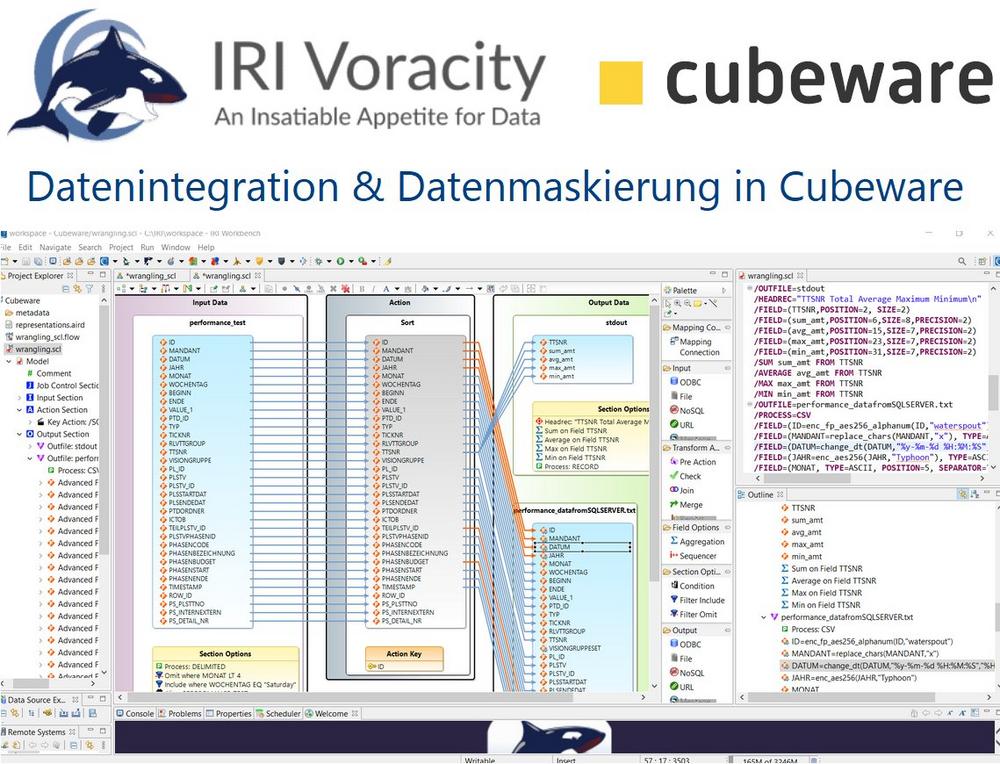
❌ Cubeware BI ❌ Schnellere Datenintegration mit DSGVO-konformen Daten für BI-Analytics in Cubeware Cockpit ❗
Big Data Management seit 40 Jahren: In früheren Artikeln in unserem Blog-Bereich für Business Intelligence haben wir bereits beschrieben, wie die Verarbeitung von Daten mithilfe unseres Produkts IRI CoSort und der Datenverwaltungsplattform IRI Voracity die Zeitspanne bis zur Datenvisualisierung und somit zu nutzbaren Erkenntnissen in BI-Tools erheblich verkürzen kann. Dieser Artikel hebt die Vorteile des Data Wranglings hervor, die Voracity in der Cubeware-Plattform für Analysen bietet! Voracity zeichnet sich durch seine Schnelligkeit im Umgang mit Daten und sein breites Spektrum an Datenmanipulations- und Datenschutzfunktionen aus. Es fehlt jedoch ein integriertes Visualisierungs- und Dashboard-Tool. Hier kommt Cubeware Cockpit ins Spiel. Voracity steigert den Wert des Importprozesses für Cubeware-Anwender durch schnelle, konsolidierte…