-
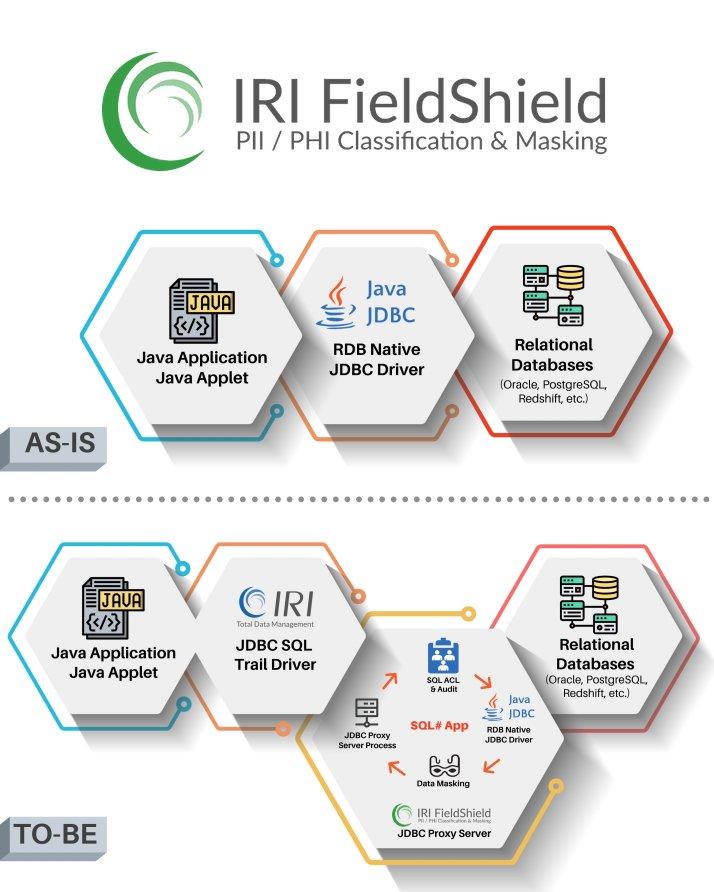
❌ Dynamische Datenmaskierung ❌ Automatische Anonymisierung und Verschleierung von sensiblen Daten in Echtzeit ❗
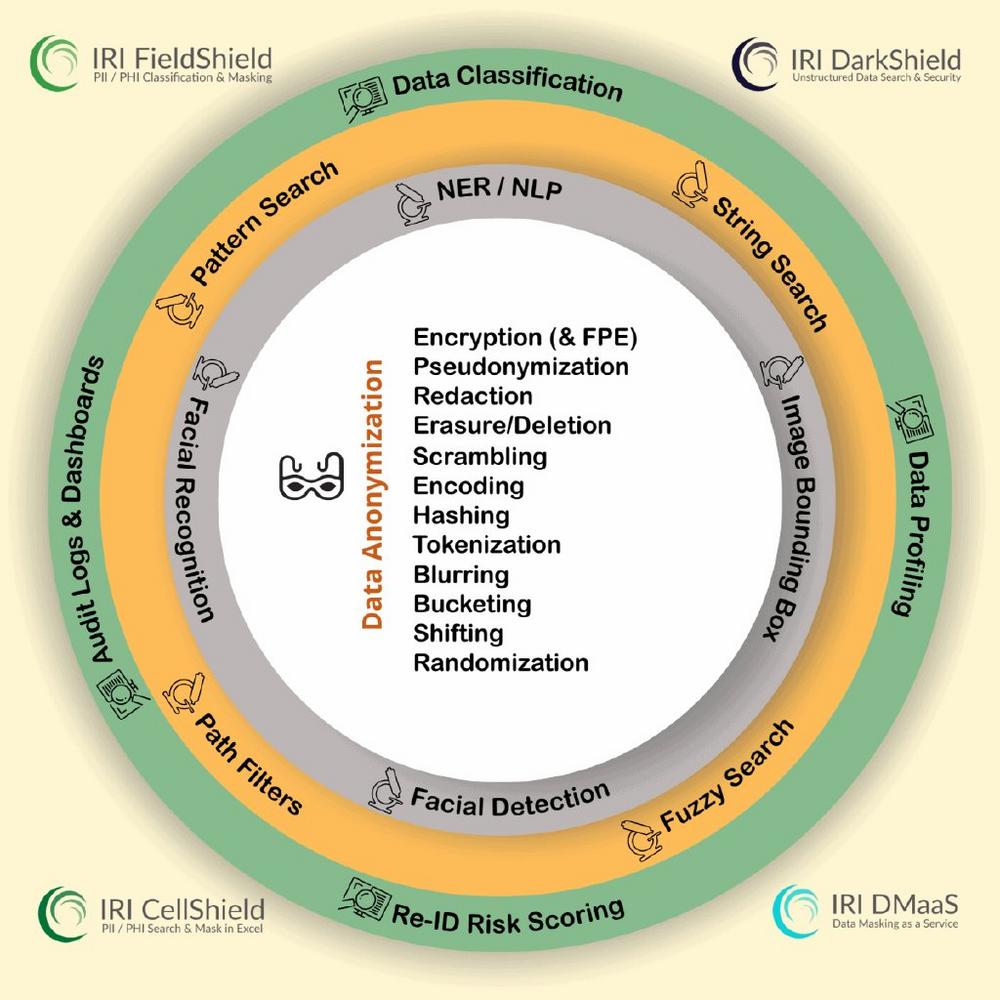
Sensible Daten bei Zugriff schützen: Dynamische Datenmaskierung bezeichnet den Prozess, bei dem Maskierungstechniken in Echtzeit angewandt werden, um sensible Informationen zu schützen. Diese Technik passt bestehende vertrauliche Daten an, sobald Benutzer darauf zugreifen oder Abfragen durchführen. Ihr Hauptziel besteht darin, rollenbasierte Sicherheitsmaßnahmen in Anwendungen wie Kundensupport oder Krankenaktenverwaltung zu implementieren. Die Funktionsweise der dynamischen Datenmaskierung gestaltet sich folgendermaßen: Alle Anwender interagieren über einen Vermittlungsserver (Proxy) mit der Datenbank. Bei Datenleseanfragen wendet der Datenbank-Proxy Maskierungsregeln an, die auf Benutzerrollen, Berechtigungen oder Zugriffsebenen basieren. Autorisierte Nutzer erhalten die unmaskierten Originaldaten, während nicht autorisierte Nutzer maskierte Daten erhalten. Dieser Artikel erläutert eine Methode zur dynamischen Datenmaskierung (DDM), die in IRI FieldShield integriert ist.…
-
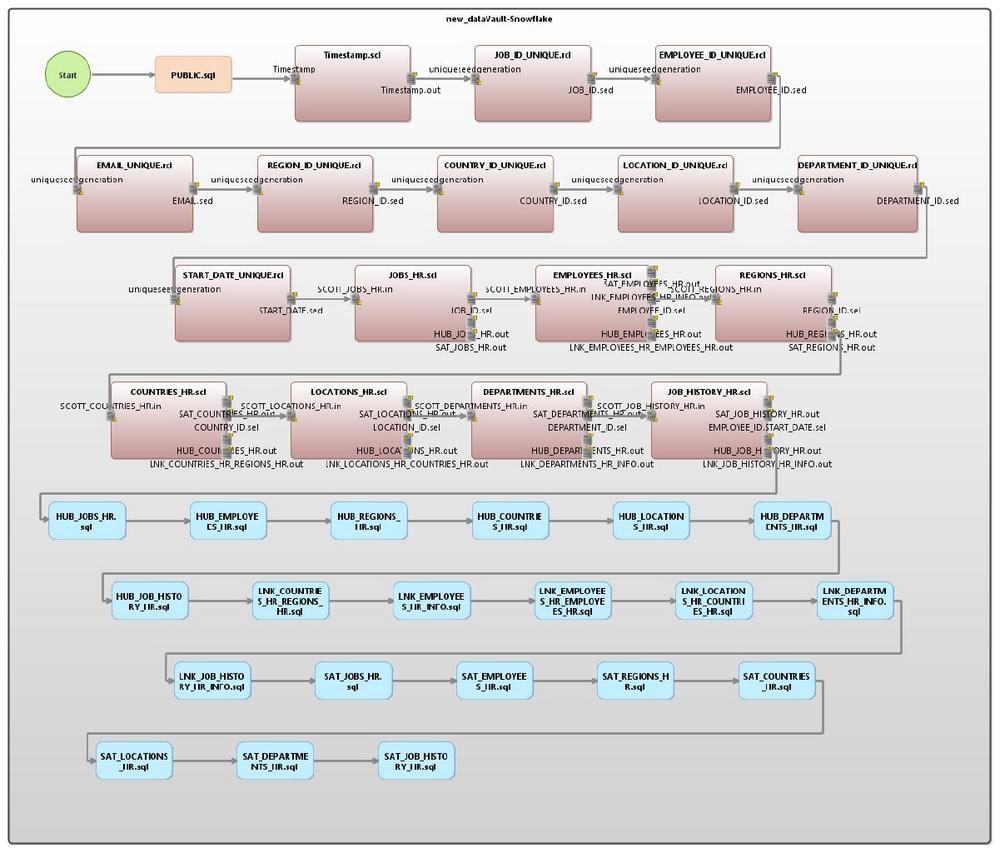
❌ Data Vault für Data Warehouse ❌ Datenmigration von RDB-Datenbankmodell in eine hybride Data Vault 2.0 Architektur ❗
Big Data Management seit 40 Jahren: IRI CoSort kam 1978 auf den Markt, um Sortier- und Berichtsfunktionen im Großrechnerformat auf Abteilungs- und Desktop-Computer zu bringen. Heute können Sie die jahrzehntelangen Fortschritte bei der Hochgeschwindigkeitsdatenbewegung und -manipulation in ergonomischen Softwareprodukten nutzen – oder in einer einzigen Plattform "IRI Voracity", die Folgendes kombiniert: Data Discovery – Klassifizierung, Diagrammerstellung, Profilerstellung und Suche in strukturierten, halbstrukturierten und unstrukturierten Datenquellen, vor Ort oder in der Cloud Datenintegration – individuell optimierte, aber konsolidierte E-, T- und L-Operationen in einem Durchgang sowie CDC, sich langsam ändernde Dimensionen und Möglichkeiten zur Beschleunigung oder zum Verlassen jeder bestehenden ETL-Plattform Datenmigration – Konvertierung von Datentypen, Dateiformaten und Datenbankplattformen sowie inkrementelle…
-
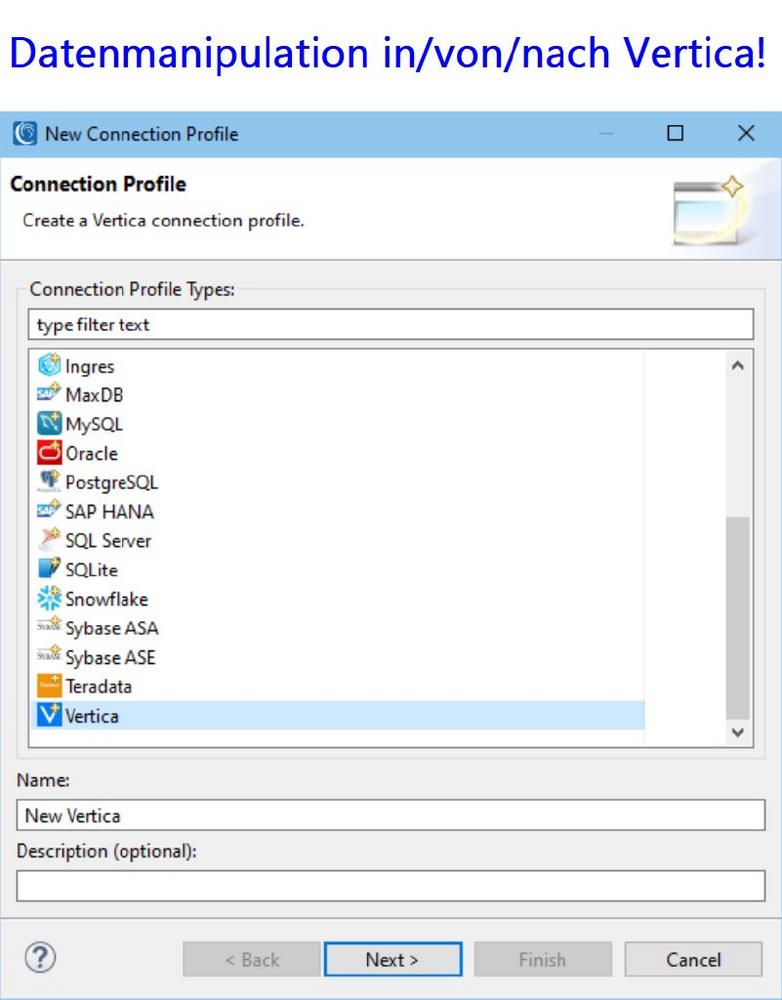
❌ Vertica Datenbank ❌ Schnelle Datenintegration, umfassende Datenmigration und Datenschutz von Vertica Database ❗
Big Data Management seit 40 Jahren: Wie andere Artikel in unserem Blog über die Verbindung und Konfiguration von relationalen Datenbanken mit der IRI Voracity Datenmanagement-Plattform beschreibt dieser Artikel detailliert, wie man gezielt Vertica-Quellen erreicht. Die IRI Voracity Datenmanagement-Plattform besteht aus ihren Ökosystemprodukten: IRI CoSort für schnellste Big Data Manipulation seit 1978 IRI NextForm gezielt zur Datenmigration und -formatierung IRI FieldShield gezielt zur Datenmaskierung von sensiblen Daten in semi- un strukturierten Quellen IRI DarkShield gezielt zur Datenmaskierung von sensiblen Daten in semi- und unstrukturierten Quellen IRI RowGen gezielt zur synthetischen Testdatengenerierung Dieser technische Artikel beschreibt, wie man Vertica-Quellen erreicht. Er beschreibt unter anderem die ODBC- und JDBC-Verbindungen und Konfigurationen, die erforderlich sind…
-
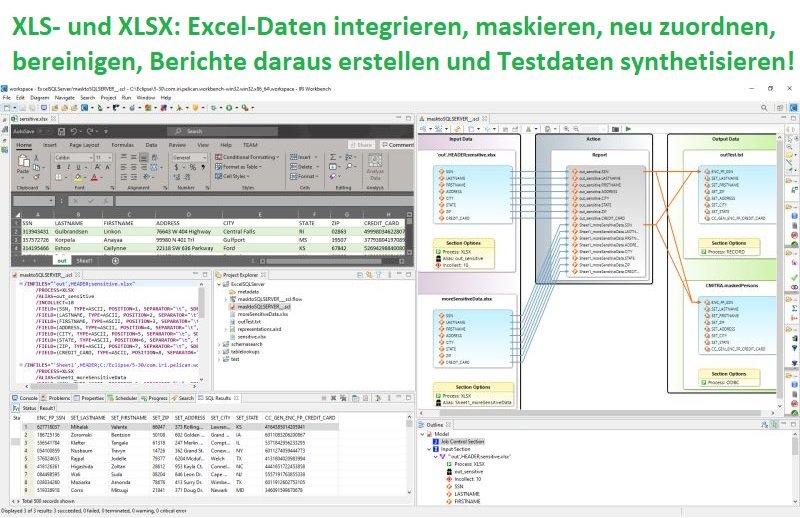
❌ Testdaten für Excel ❌ Formatierte, bereichsbezogene und nach Häufigkeit verteilte Testdaten in Microsoft Excel erzeugen❗
Dieser Artikel ist eine Fortsetzung des vorangegangenen Artikels, in dem die IRI-Unterstützung für XLS- und XLSX-Dateiformate im SortCL-Programm vorgestellt wurde, das zum Verschieben und Bearbeiten von Tabellenkalkulationsdaten in der IRI Voracity-Datenmanagement-Plattform und den darin enthaltenen Fit-for-Purpose-Produkten verwendet wird. Diese Job-Beispiele zeigen, was diese Metadaten-kompatiblen Anwendungen mit Daten direkt in/aus Excel-Tabellen im XLS- oder XLSX-Format alles machen können: Synthese von Testdaten: Dieses Skript demonstriert die Verwendung eines IRI RowGen-Auftragsskripts zum Generieren einer kleinen Menge zufälliger Testdaten in einer XLSX-Datei und einer XLS-Datei mit einer Kopfzeile. Synthese von Zufallsdaten mit verschlüsselten Feldern: Dieser hybride RowGen-FieldSheld-Job demonstriert die zufällige Auswahl von Namen und E-Mail-Domänen aus Set-Dateien und die anschließende Maskierung dieser Namen mit…
-
❌ PCI DSS ❌ Statische und dynamische Datenverschlüsselung für Konformität von sensiblen Kartendaten ❗
Primäre Kontonummern (PAN) und Kreditkartennummernwerte, zusammen mit anderen gefährdeten Daten in mehreren Datenquellen finden und GDPR-konform schützen! Die Datenermittlungs- und Maskierungsfunktionen in den Produkten der IRI Data Protector Suite – oder der IRI Voracity Plattform – helfen dabei, die Auswirkungen von Datenschutzverletzungen abzuschwächen oder sogar zunichte zu machen, und unterstützen BFSI-Unternehmen und andere Organisationen, die Kreditkartendaten verwalten, bei der Einhaltung der PCI DSS Regeln. Die anwendbaren Sicherheitsfunktionen auf Feldebene sind starke Verschlüsselung, SHA-2 kryptographisches Hashing und Tokenisierung. In strukturierten Datenquellen wie normal geformten relationalen Datenbankspalten und Feldern in Flat-Files können IRI FieldShield-Benutzer die Datenklassifizierung, Suchmethoden und Schutzfunktionen ihrer Wahl auf PANs und andere sensible Daten auf intuitive, effiziente und flexible…
-
❌ Tableau für BI und Analytics ❌ 8-fache Beschleunigung von Tableau Datenvisualisierung für Business Intelligence❗
Schnellere Datenaufbereitung für Tableau: Schnelleres Bearbeiten, Maskieren und Verteilen von Daten! Tableau bietet eine Familie von interaktiven Datenvisualisierungstools für Business Intelligence und Analytics. Nichts kann jedoch effektiv analysiert oder visualisiert werden, bis die Daten lokalisiert, erfasst, verfeinert, gruppiert, gesichert und anderweitig für die Visualisierung(en) vorbereitet wurden. Die IRI-Software bietet eine leistungsstarke, erschwingliche Datenmischung und -aufbereitung für Tableau in einer umfassenden Datenverwaltungsumgebung, die Datenerkennung (und -klassifizierung), Integration (ETL), Migration, Governance und Analytik unterstützt! Verwenden Sie die IRI CoSort-Software – oder die größere IRI Voracity-Plattform auf Basis von CoSort oder Hadoop – zum Extrahieren, Filtern, Transformieren und Schützen von Daten aus mehr als 150 verschiedenen Quellen. Insbesondere das Programm Sort Control…
-
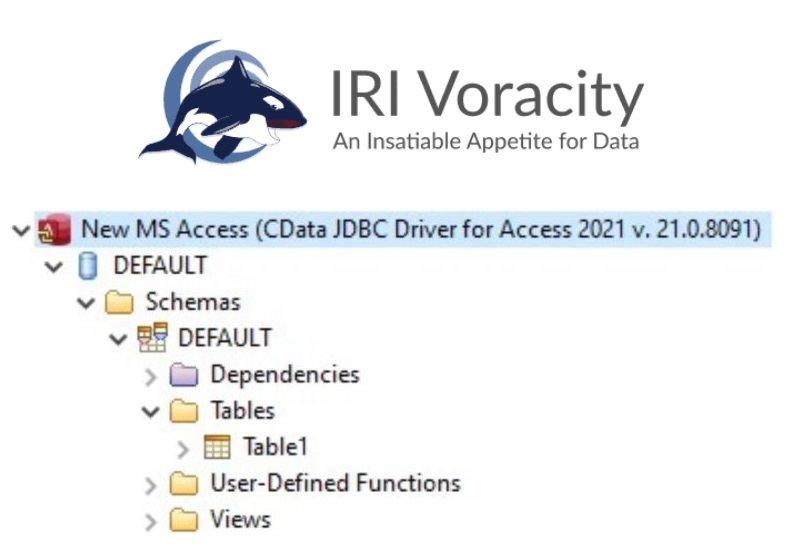
❌ Microsoft Access ❌ End-to-End Datenverwaltung und schnellere Datenmanipulation von/in MS Access DBMS ❗
Microsoft Access Daten mit Voracity verarbeiten: Die One-Stop-, Full Stack Datenlösung-Plattform aus einer Hand! Voracity ist das, worauf Sie gewartet haben…. eine einzige, intuitive und preisgünstige Plattform, die auf Eclipse™ basiert für: Data Discovery (Profiling, Klassifizierung, ERDs, Dark Data) Datenintegration (ETL, CDC, SCD, TDM) Datenmigration (Dateien, DBs, Datentypen, Datensatzlayouts) Data Governance (Maskieren, Bereinigen, MDM, EMM) Analytics (integrierte BI & Datenaufbereitung) Voracity ist die einzige Data Life Cycle Management (DLCM) und Kurationsplattform, die die Kostenkurven von ETL-Megavendoren und Spezialsoftware sowie die Komplexität und das Risikoprofil von getrennten Apache-Projekten abbildet. Durch seine kostenlose Eclipse GUI, IRI Workbench, können Voracity-Benutzer Datenquellen schnell manipulieren, migrieren, maskieren, mungen und mehrfach verwenden, intern und extern, strukturiert…
-
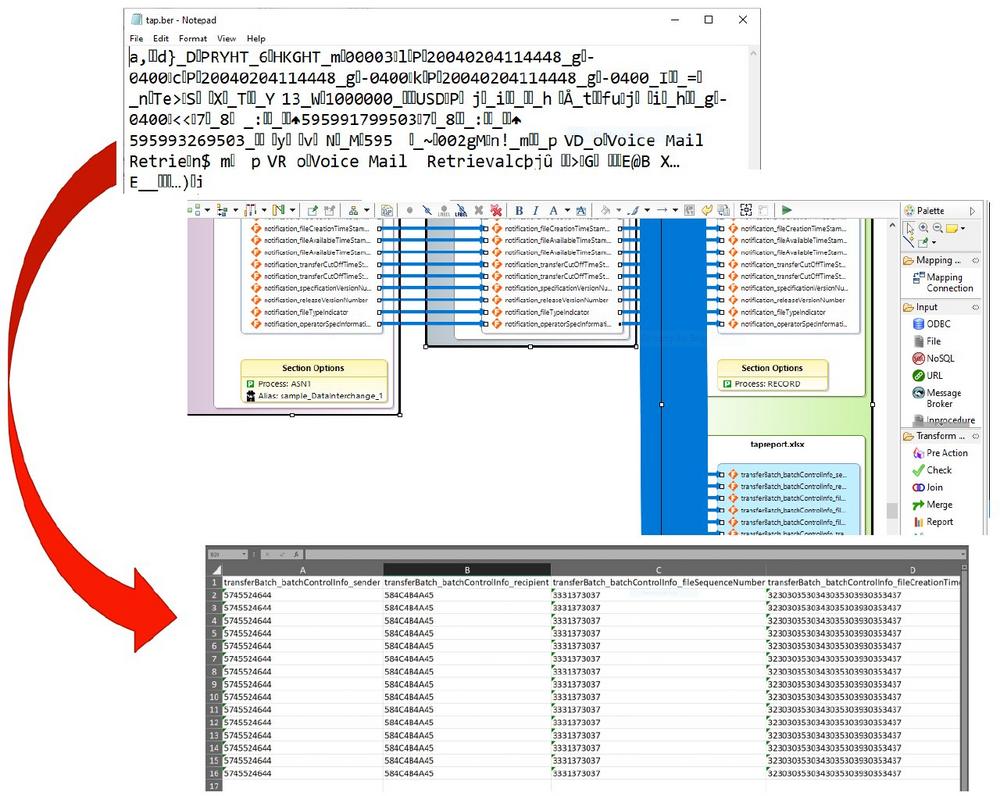
❌ CDR- und UDR-Daten ❌ Sofortige Datenverarbeitung und Datenschutz von nativen ASN.1-Format, ohne vorherige Vermittlung ❗
Direkte Unterstützung des ASN.1-Formats: Abstract Syntax Notation One (ASN.1) ist eine Sprache zur Beschreibung des Inhalts und der Kodierung von Nachrichtendaten, die zwischen Computern ausgetauscht werden (insbesondere in der Telekommunikationsindustrie). Dies ist der erste in einer Reihe von fünf Artikeln über das Dateiformat und das umfassende neue Data Engineering, das Sie mit ASN.1-Dateien unter Verwendung der IRI-Software durchführen können. Jede Datei wird durch eine ASN.1-Spezifikationsdatei (auch als Schema bezeichnet) beschrieben, die in der Regel die Erweiterung .asn hat. Diese für den Menschen lesbare Metadaten-Datei definiert jedes Feld in der Nachricht und wird automatisch in SortCL-kompatiblen Jobs in der IRI Voracity Datenmanagement-Plattform und ihren Komponentenprodukten (CoSort für Big Data Manipulation, NextForm…
-
❌ Datenschutz in Elasticsearch ❌ Sensible PII-Daten in CSV- und JSON-Sammlungen sofort finden und automatisch schützen ❗
Sensible Daten aufspüren und automatisch schützen: Elasticsearch ist eine auf Java basierende Suchmaschine mit einer HTTP-Schnittstelle, die Daten in JSON-Dokumenten ohne festes Schema speichert. Bedauerlicherweise sind Elasticsearch-Datenbanken häufig von teuren und schmerzhaften Verletzungen personenbezogener Daten (PII) betroffen. Wenn jedoch alle PII oder andere sensible Informationen in diesen Datenbanken maskiert würden, wären erfolgreiche Hackerangriffe und unautorisierte Kopien kein Problem mehr. Die mehrfach ausgezeichnete Sicherheitssoftware von IRI, die auf datenzentrierten Ansätzen beruht, hat sich in zahlreichen Umgebungen bewährt, um Verstöße zu verhindern, Datenschutzvorschriften einzuhalten und DevOps-Tests durchzuführen. So können Sie nachweisen, dass Sie sie konform geschützt haben! IRI FieldShield: Finden, klassifizieren und maskieren von PII mit hohem Risiko in Legacy-Dateien, relationalen und…
-
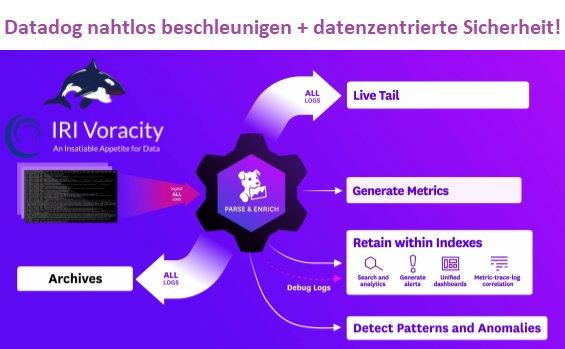
❌ Datadog Monitoring ❌ ETL-Beschleunigung von Big Data und DSGVO-konformer Compliance von Datadog❗
Datadog: Cloud Monitoring as a Service! Datadog ist eine Web-Anwendung zur Überwachung von Datenfeeds (Dateneinspeisung), zur Analyse von Trends, zur Erstellung analytischer Dashboard-Anzeigen und zum Senden von Warnmeldungen. Dieser Artikel ist der erste in einer 4-teiligen Serie über die Einspeisung der Datadog Cloud-Analyseplattform mit verschiedenen Arten von Daten aus IRI Voracity-Operationen. In Fällen, in denen eine große Datenmenge offline vorbereitet werden muss, bevor die Daten ausgegeben werden und die Daten auf einer Infrastruktur außerhalb von Datadog verarbeitet werden können, kann Voracity für ein hochleistungsfähiges Daten-Wrangling sorgen: Dieser zweite Artikel beschreibt die Einspeisung verschiedener Daten aus IRI Voracity in die Datadog Cloud-Analyseplattform. Der Artikel konzentriert sich auf die Vorbereitung der Daten…