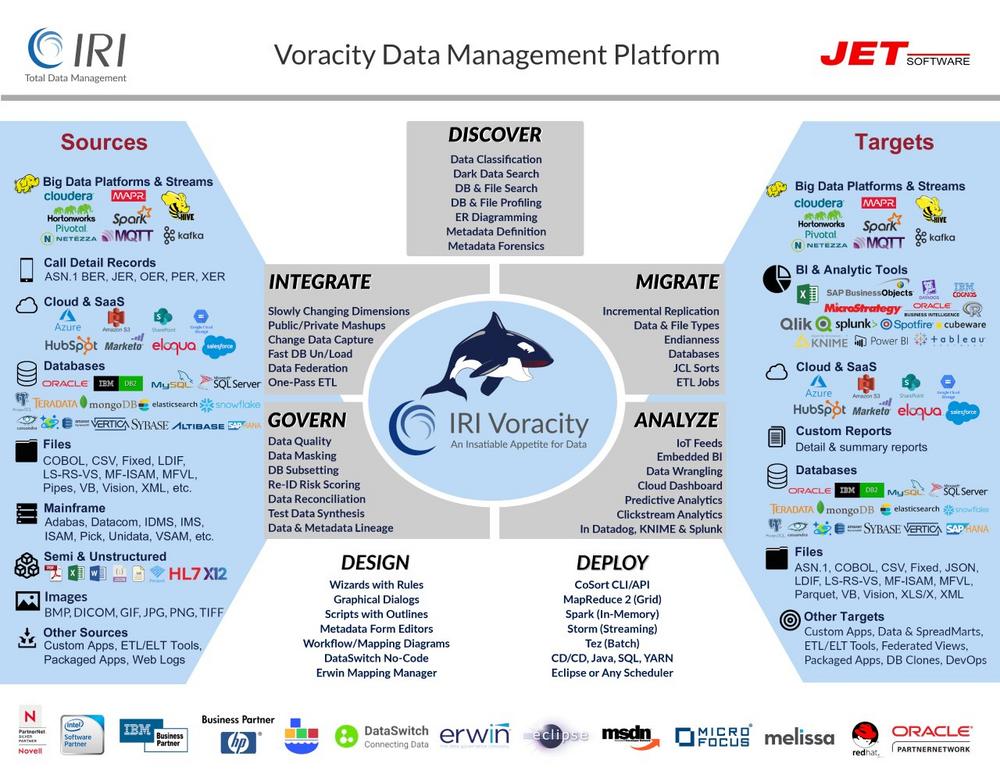
-
❌ Talend Data Integration ❌ Talend Data Fabric beschleunigen und Daten via Datenmaskierung oder synthetischen Testdaten für TDM schützen ❗
Talend Data Fabric: Es gibt bestimmte Herausforderungen, die mit großen Datenmengen verbunden sind, wie beispielsweise das Sortieren, Verbinden, Aggregieren, Laden und Entladen von Daten. Die parallele Verarbeitung oder Optimierung in anderen Bereichen oder Tools kann umständlich sein und möglicherweise hohe Kosten verursachen. Zudem kann dies die Leistung für andere Benutzer beeinträchtigen. Im Hinblick auf die Sicherheit bietet Talend möglicherweise nicht die erforderlichen Funktionen für das Erkennen, Klassifizieren oder Maskieren von Daten oder das Testen von Datenfunktionen, die Datenverwalter und Anwendungsentwickler benötigen. Transformationen beschleunigen: Sort-Beschleunigung, Aggregation und Zusammenführen von Talend ETL-Strömen mit einem tSystem-Aufruf an die Programme CoSort Sort Sort Control Language (SortCL). Führen Sie große Datentransformationen mehrfach zeitsparend aus, ohne…
-
❌ KNIME ❌ 9x schnelleres ETL und Data Analytics, mit zusätzlicher Datensicherheit auf Feldebene ❗
KNIME (für Konstanz Information Miner) ist eine kostenlose und Open-Source-Datenanalyse-, Berichts- und Datenforschungsumgebung, die auf Eclipse™ basiert. Die KNIME Analytikplattform bietet durch ihr modulares Datenpipelingkonzept verschiedene Komponenten für Machine Learning und Data Mining. KNIME verfügt wie andere Analysetools über integrierte ETL-Knoten, die Ihnen bei der Integration und Aufbereitung von Daten helfen. Aber wie andere Analysewerkzeuge ist auch KNIME durch großes Datenvolumen, Vielfalt, Geschwindigkeit und Wahrhaftigkeit herausgefordert.. außer, wenn es von IRI Voracity angetrieben wird! Glücklicherweise ist es jetzt möglich, die Datenaufbereitung und -analyse nahtlos zu beschleunigen und zu kombinieren…. in der gleichen grafischen IDE für Voracity, die ebenfalls auf Eclipse basiert und IRI Workbench genannt wird. Insbesondere ist der "Voracity…
-
❌ Datenmissbrauch verhindern ❌ Sensible Daten in Cloud-Datenbank finden und Datenmaskierung in JSON, PDF, Bild oder MS-Dokumenten❗
Definieren, Erkennen und De-Identifizieren von PII in Dark Data Dateien: Mit IRI DarkShield können Sie sensible Informationen in verschiedenen strukturierten, semistrukturierten und unstrukturierten Quellen klassifizieren, finden und löschen oder anderweitig maskieren, einschließlich: Text, PDF- und MS Office-Dokumente, Parquet- und Bilddateien, relationale und NoSQL-Sammlungen und sogar Gesichter. DarkShield nutzt gemeinsam genutzte Datenklassen, benutzerdefinierte Suchkombinationen und konsistente Maskierungsfunktionen für alle Quellen vor Ort und in der Cloud. Mit DarkShield können Sie auch Job-Ergebnisse (und die dazugehörigen Datei-Metadaten) in seiner Eclipse oder Ihrer SIEM-Umgebung extrahieren, freigeben und anzeigen. Mit DarkShield können Sie Anfragen nach dem "Recht auf Vergessen" erfüllen, bestimmte Datenextrakte an diejenigen liefern, die die Übertragbarkeit von Datensätzen anfordern und die Datenqualität…
-
❌ Realistische Testdaten ❌ Daten synthetisieren für ein vollständiges Datenbankschema mit referentieller Integrität ❗
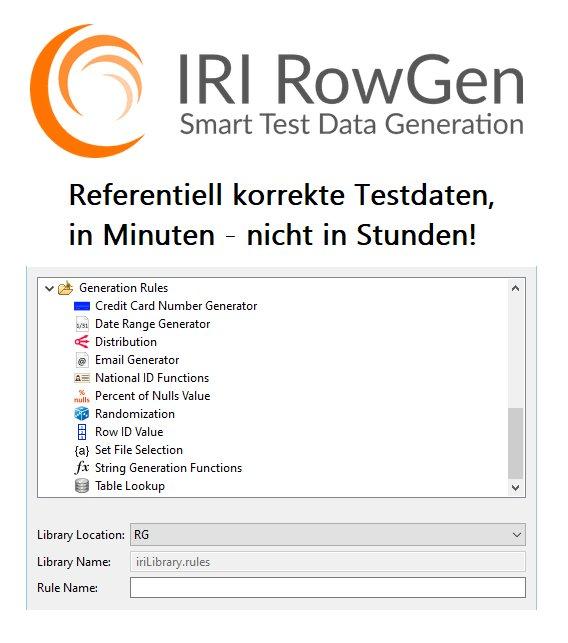
Synthetisieren realistischer Daten mit Set-Dateien: Dieser Artikel demonstriert, wie realistische Daten synthetisiert werden, um ein vollständiges Datenbankschema mit referentieller Integrität in einem Arbeitsgang zu füllen. IRI RowGen erstellt Datenzeilen in Flat-Files, Datenbanktabellen und Reports entweder durch zufällige Generierung von Spaltenwerten in bestimmten Datentypen, Bereichen und Verteilungen oder durch zufällige Auswahl von Daten aus Nachschlagetabellen oder externen "Set-Dateien". Die Wahl einer der beiden Methoden kann ad hoc oder als tabellenübergreifende Regeln auf einer spaltenweisen Basis festgelegt werden. Set-Dateien bieten mehr Realismus für synthetisierte Spalten, die Namen, Orte, Adressen und andere Eigennamen oder nicht numerische Werte enthalten. IRI liefert mehrere vorgefertigte Set-Dateien mit dem Produkt aus, aber sie sind ansonsten sehr einfach…
-
❌ Big Data ❌ Datenqualität und Datenintegrität zwangsläufig im Verantwortungsbereich der Unternehmen ❗
IRI Voracity Data Quality & Security adressiert Analytics- und Cloud-Herausforderungen! Zum achten Mal in Folge hat das Magazin Database Trends and Applications (DBTA) in seiner aktuellen Online-Ausgabe unseren Partner IRI The CoSort Company unter den "100 Companies That Matter Most in Data" aufgeführt. In der Liste werden Hardware-, Software- und IT-Unternehmen aufgeführt, die Kunden dabei helfen, die wichtigsten Herausforderungen des Daten- und Analysemanagements im Jahr 2023 zu meistern. Im Eröffnungsartikel schreibt DBTA-Chefredakteurin Stephanie Simone, dass diese Herausforderungen darin bestehen, die Datensicherheit mit neuen Dateninitiativen in Einklang zu bringen, einen geschäftlichen Mehrwert zu liefern und die Unternehmenskultur in Bezug auf Daten zu verändern." Sie stellt in ihrer Einleitung fest, dass "die…
-
❌ Snowflake ETL ❌ Performance steigern und Verarbeitungskosten senken und zusätzliche Sicherheitsfunktionen nutzen ❗
Die Lösung für zeitaufwendige Probleme mit Snowflake: Datensuche, -profilierung und/oder -klassifizierung Integration oder Daten-Wrangling für DW/BI-Ops Datenbewegung/Migration zu/von Tabellen Transformieren oder Laden großer Tabellen Datenerfassung oder -replikation ändern Clustering oder Abfrage der Performance Generierung intelligenter und sicherer Testdaten Maskierung sensibler Daten Auch spezifische Leistungsdiagnosen und -abstimmungen brauchen Zeit und können andere Benutzer betreffen. Schließlich können gespeicherte SQL-Prozeduren auch ineffizient programmiert werden und erfordern eine Optimierung und dauern dann immer noch zu lange! Schnelles, kostengünstiges Datenmapping und Datenverwaltung von und in Snowflake! Daten in Ordnung halten: IRI CoSort für die Vorsotierung von Flat-Files für Bulk-Ladungen und Inserts. Das entfernt den Overhead dieser Arbeit von Snowflake und verbessert die Leistung von Clustering…
-
❌ Datenschutz im Bild ❌ Sensible Daten erkennen, klassifizieren und via Datenmaskierung automatisch DSGVO-konform schützen❗
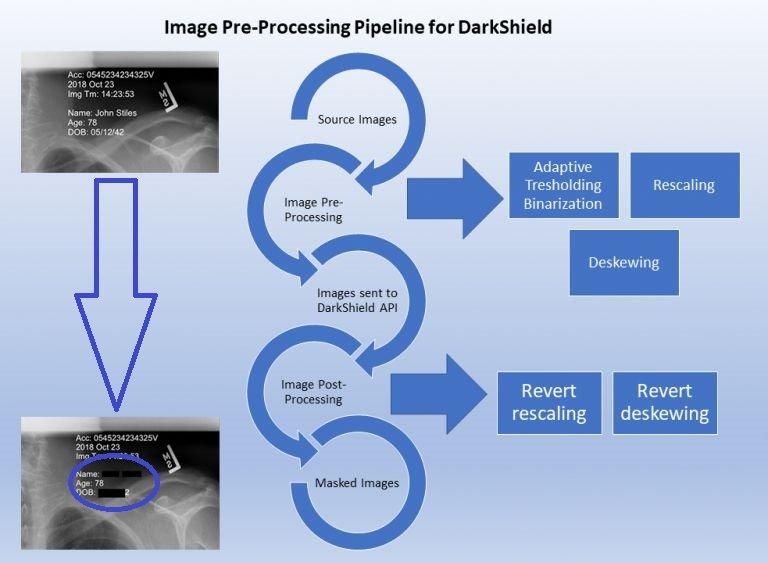
Vorverarbeitung von Bildern zur Verbesserung der OCR-Ergebnisse: OCR-Software (Optical Character Recognition) ist eine Technologie zur Erkennung von Text in einem digitalen Bild. OCR wird von der IRI DarkShield-Software verwendet, um Text in eigenständigen oder eingebetteten Bildern während der PII-Suche und -Maskierungsvorgänge zu erkennen. OCR hat jedoch ihre Grenzen: Um genaue Ergebnisse zu erzielen, muss das Bild vertikal ausgerichtet sein, die richtige Größe haben und so klar wie möglich sein. Nicht jedes Bild erfüllt diese Anforderungen! Wir müssen daher Methoden finden und anwenden, um diese Bilder durch Vorverarbeitung an unsere Bedürfnisse anzupassen. In diesem Artikel werden einige Vorverarbeitungsmethoden vorgestellt und erläutert, wie sie die Qualität der OCR-Ausgabe im Zusammenhang mit der…
-
❌ Database Subsetting ❌ Automatisches Erzeugen einer Teilmenge verwandter Daten von referenziell korrekten Testdaten für DB-Prototypen und DevOps ❗
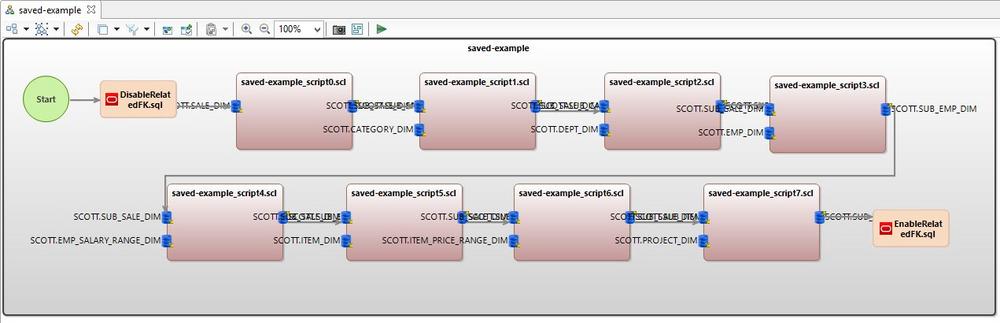
Datenbase Subsetting: Wenn eine Datenbank eine bestimmte Größe überschreitet, entstehen hohe Kosten und es wird auch aus Sicherheitsgründen riskant, vollständige Kopien für Entwicklung, Tests und Schulungen bereitzustellen. In den meisten Fällen benötigen Teams kleinere Kopien der größeren Datenbank und der Schutz personenbezogener Daten in diesen Kopien ist von großer Bedeutung. Der Prozess des Datenbank-Subsettings beinhaltet die Erstellung einer kleineren, korrekten Kopie einer größeren Datenbank durch die Verwendung von echten Tabellenauszügen. Teilmengen werden genutzt, um die Kosten und Risiken, die mit vollständigen Datenmengen einhergehen, zu reduzieren, entweder in Kombination mit oder anstelle von Datenmaskierung oder der Generierung von Testdaten. Das manuelle Erstellen aussagekräftiger Teilmengen ist eine komplexe und zeitaufwändige Aufgabe, da…
-
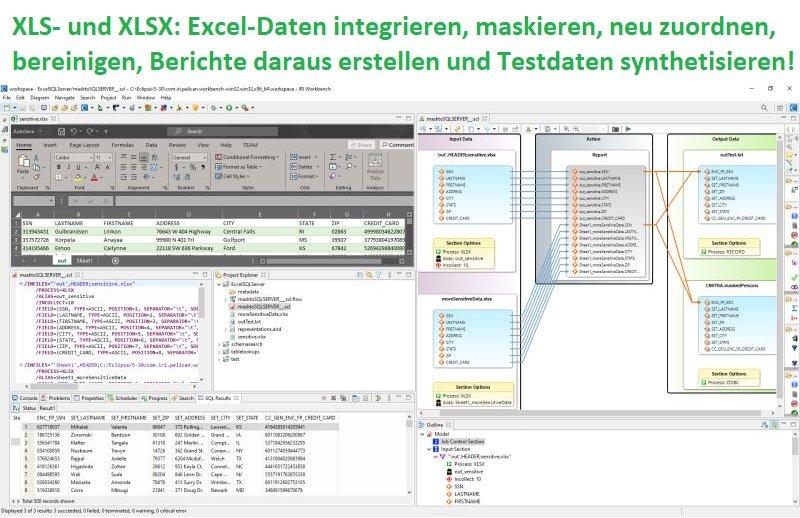
❌ Excel für BI ❌ Umfassende Datenverarbeitung von einem/mehreren Excel-Arbeitsblättern zusammen mit Tabellen, Flat-Files und Streaming-Daten ❗
Umfassende und schnelle Verarbeitung von Tabellenkalkulationsdaten: Zusätzlich zu allen anderen strukturierten Datenquellen, die die IRI-Software bereits unterstützt, ist es jetzt möglich, Daten aus XLS- und XLSX-Dateien zu lesen und zu verarbeiten! IRI CoSort, für schnelles Sortieren, Umwandeln und Berichten IRI NextForm, für Mapping, Migration und Replikation IRI RowGen, für die zufällige Auswahl oder Generierung von realistischen Testdaten IRI FieldShield, für die Maskierung sensibler Daten IRI Voracity, für alle oben genannten Funktionen sowie für ETL, Datenbereinigung und -aufbereitung für Analysezwecke und zum Zurückschreiben der resultierenden Daten in diese oder andere Ziele, einschließlich eines oder mehrerer Blätter. Dieser Artikel gibt einen Überblick über die Operationen und die Syntax des SortCL-Programms, das mit…
-
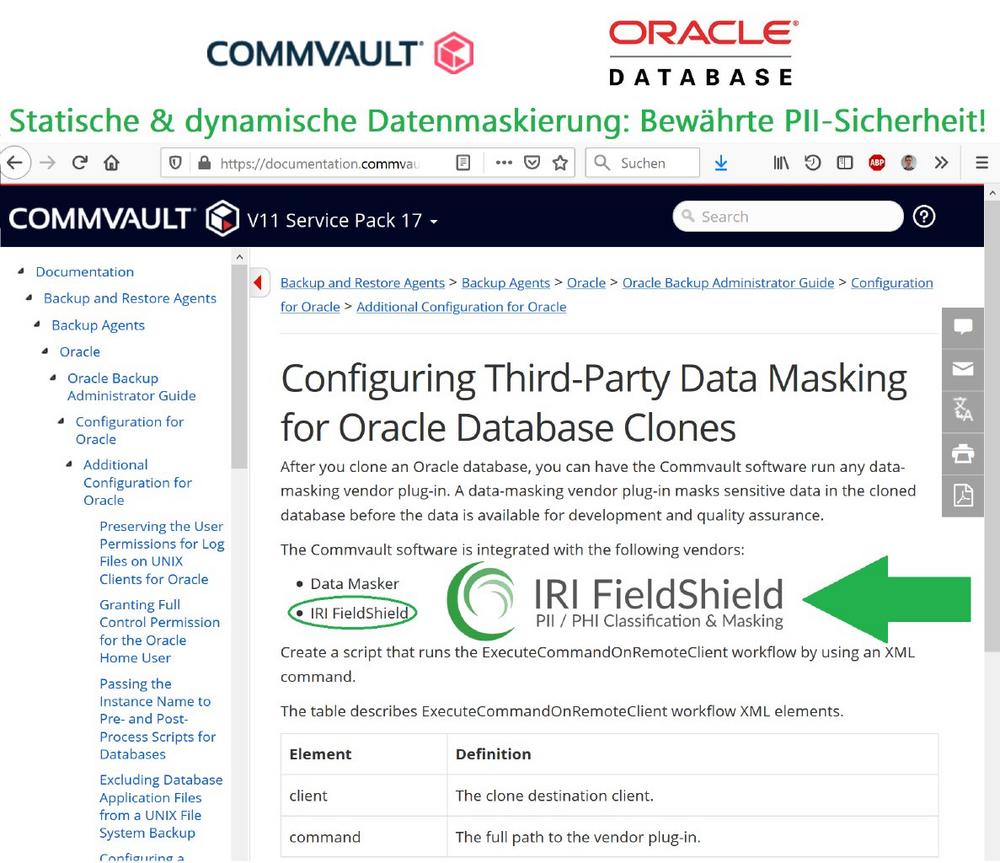
❌ Oracle Datenbank Backup ❌ Datenbank via Commvault klonen und automatisch via Plug-In sensible Daten schützen ❗
Sicheres Datenbank-Klonen: Das Sicherheitsprodukt IRI FieldShield maskiert sensible Daten in der geklonten Datenbank, bevor dann die Daten für die Entwicklung und Qualitätssicherung zur Verfügung stehen! Nachdem Sie eine Oracle-Datenbank geklont haben, können Sie die Commvault-Software mit unserer Datenmaskierung via Plug-In ausführen lassen. Die Commvault-Software ist bei unserem IRI FieldShield integriert. Die Anleitung finden Sie direkt bei Commvault V11 Service Pack 17 unter: "Configuring Third-Party Data Masking for Oracle Database Clones" Was ist FieldShield? IRI FieldShield® ist eine leistungsstarke und kostengünstige Software zur Datenerkennung und –maskierung von PII in strukturierten und semistrukturierten Quellen, groß und klein. Die FieldShield-Dienstprogramme in Eclipse dienen zur Profilierung und De-Identifizierung von Daten im Ruhezustand (statische Datenmaskierung)…