-
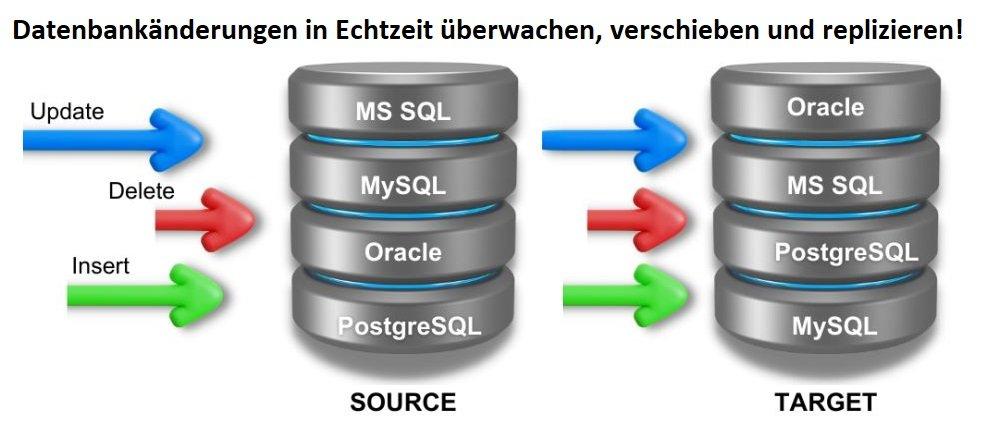
❌Datenbankreplikation in Echtzeit❌ Änderungen (CDC) in der Struktur und dem Inhalt von Datenbankspalten automatisch erkennen und verwalten ❗
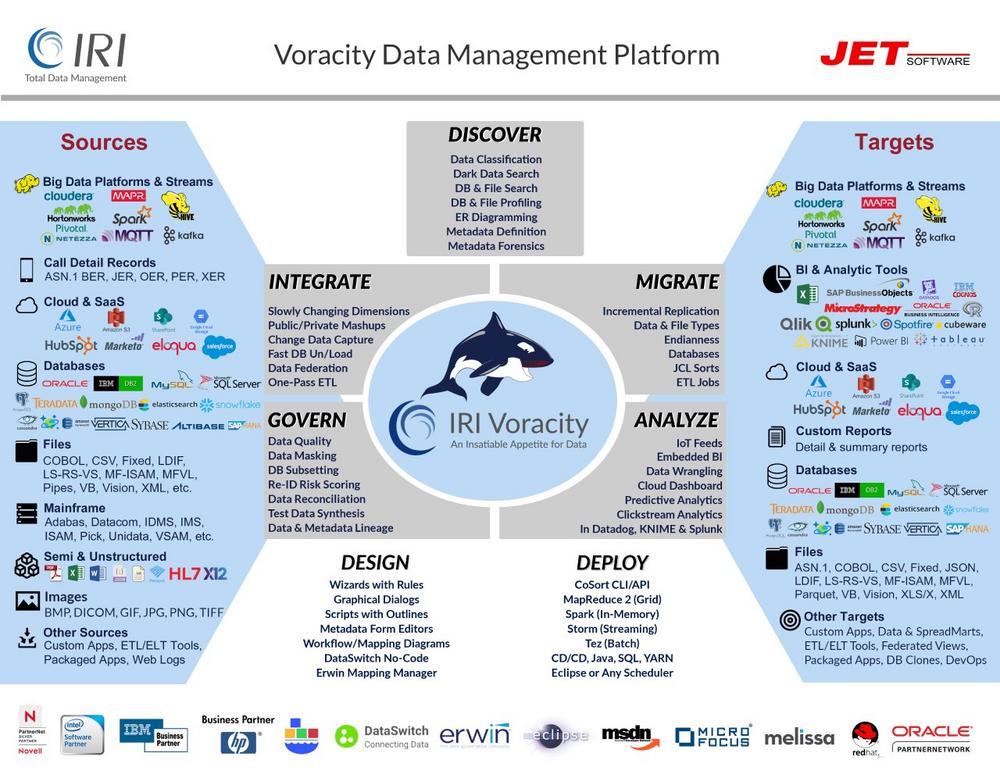
End-to-End-Datenmananagement: Die Datenmanagement-Plattform IRI Voracity kombiniert Datenermittlung, -integration, -migration, -steuerung und -analyse mit der Backend-Datenverarbeitungs-Engine IRI CoSort und der auf Eclipse basierenden Front-End-IDE IRI Workbench. Letztes Jahr wurde zudem ein vielseitiges Modul zum Generieren, Profilieren, Migrieren zu und Prototypisieren von Data Vault 2.0 Modellen eingeführt. In diesem Jahr hat wurde nun die zukunftsweisende Funktion "IRI Ripcurrent" in Voracity eingeführt, um Änderungen in der Struktur und dem Inhalt von Datenbankspalten in Echtzeit zu verwalten. IRI Ripcurrent erkennt neue, aktualisierte oder gelöschte Zeilen – oder Änderungen an der Struktur einer Tabelle oder eines Schemas – und reagiert automatisch auf diese Informationen auf verschiedene Arten, einschließlich: Datenreplikation: Um Testziele innerhalb derselben oder einer…
-
❌ SAP ASE und IQ ❌ 12x schnelleres ETL und gezielter Datenschutz von SAP IQ (RDBMS) und SAP Adaptive Server Enterprise für OLTP ❗
Als SAP Sybase IQ oder ASE DBA werden Sie mit verschiedenen Performance- und Schutzproblemen konfrontiert: Entladen und Laden von großen Sybase-Tabellen Langsame Hilfsoperationen (z.B. Reorgs) oder Abfragen Ungeschützte personenbezogene Daten (PII) Lästige Datenbankmigration oder -replikation Generierung von oder Zugriff auf Testdatensätze Auch spezifische Leistungsdiagnosen und -abstimmungen brauchen Zeit und können andere Benutzer betreffen. Spezielle Tools zur Datenmaskierung und zum Testdatenmanagement sind teuer und zu schwer zu bedienen. Schließlich können gespeicherte SQL-Prozeduren auch ineffizient programmiert werden, müssen optimiert werden und dauern dann immer noch zu lange. Beschleunigung der Sybase-Entladung: IRI FACT (Fast Extract), um Transaktionstabellen parallel zu Flat Files auszugeben. FACT unterstützt Sybase IQ und ASE, OCS 15 und höher. FACT…
-
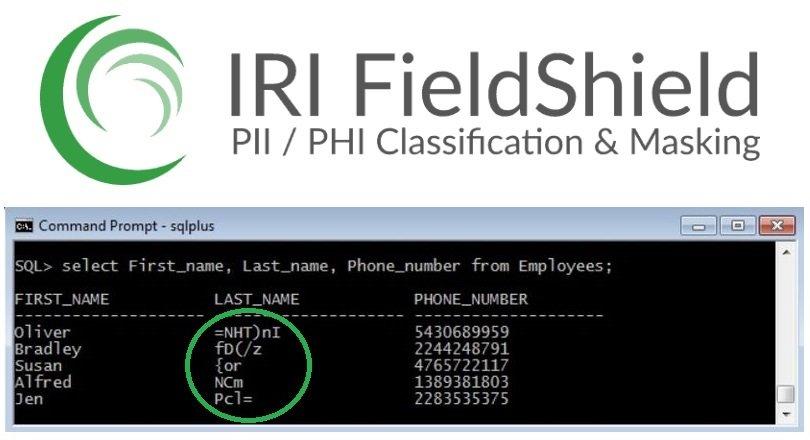
❌ Oracle Datenbank ❌ Automatische Datenmaskierung in Echtzeit bei Einfügung oder Aktualisierung ❗
Datenmaskierung in Echtzeit: In früheren Artikeln wurde die statische Datenmaskierung neuer Datenbankdaten mit Hilfe der /INCLUDE-Logik oder der /QUERY-Syntax in geplanten IRI FieldShield-Job-Skripten beschrieben, die Änderungen der Spaltenwerte erforderten, um Aktualisierungen zu erkennen. Dieser Artikel beschreibt einen passiveren, aber integrierten Weg zum Auslösen von FieldShield-Maskierungsfunktionen auf der Basis von SQL-Ereignissen, d.h. zum Maskieren von Daten, wie sie in Echtzeit erzeugt werden. Er kann auch als "Prozedurenmodell" für andere Datenbanken und Betriebssysteme dienen. Der Artikel geht zunächst auf die Installation von FieldShield ein und nennt die dazu benötigten Anforderungen. Danach folgt ein anschaulicher Anwendungsfall mit PL/SQL-Triggern für die ASCII-Format bewahrende Verschlüsselung und die dazu gehörende entschlüsselte Ansicht. Allgemeiner gesagt können Sie…
-
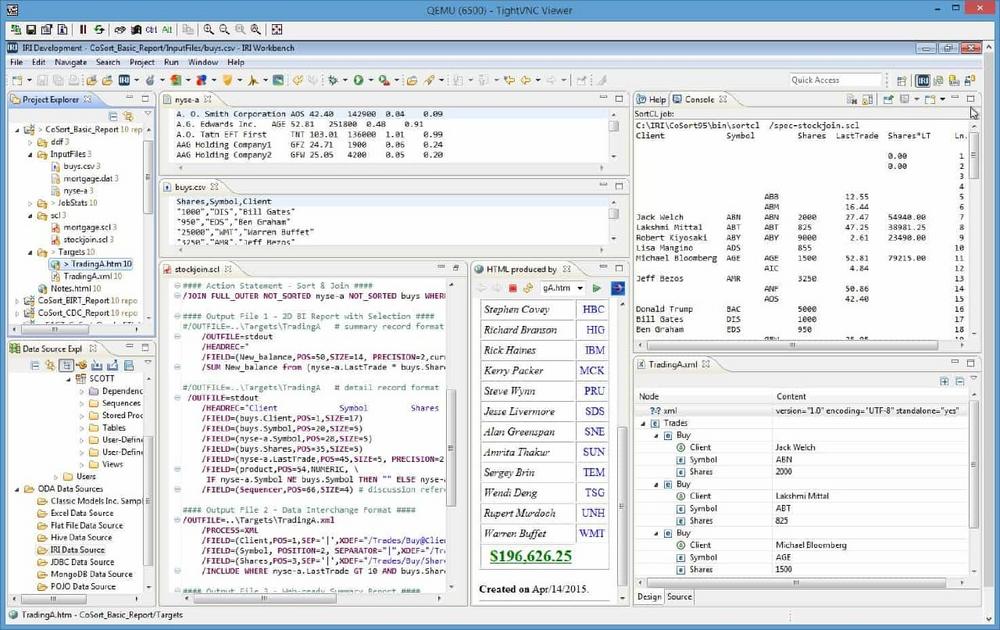
❌ Integrierte BI ❌ Datentransformation(en) mit Reports im gleichen Jobskript und I/O-Pass ❗
Schnelles, einfaches Big Data Reporting: Eine der wichtigsten integrierten (eingebetteten) Funktionen in allen IRI-Datenmanagementprodukten ist die Berichtserstellung! IRI-Benutzer die große Datentransformationen durchführen, können auch ein oder mehrere benutzerdefinierte Detail- und Zusammenfassungsberichte im gleichen Jobskript und I/O-Pass erstellen, d.h. sie führen BI direkt mit ETL aus. Und da IRI NextForm (für Daten/Datenbank-Migration), IRI FieldShield (für Datenmaskierung) und IRI RowGen (für synthetische Testdaten) auch SortCL-Fähigkeiten nutzen, können auch sie viele der gleichen Arten von Berichten mit den gleichen Metadaten generieren. Strukturierte Datenquellen (Datenbank oder Flat-File) werden ebenso gut unterstützt wie viele Formen von semi- und unstrukturierten Daten. Es gibt keine Begrenzung der Anzahl der Quellen oder Ziele. Sehen Sie diese Liste der…
-
❌ Adabas und Natural ❌ 6x schnellere Datenverarbeitung und Report via Plug’n’Play Sort für nahtlose Prozessbeschleunigung ❗
NATURAL Sort-Ersatz: Der 6x schnellere Weg, um große Datensätze direkt zu sortieren! IRI CoSort enthält eine Plug’n’Play-Sortierbibliothek für Benutzer von Natural unter Unix. Ohne Benutzereingriff und einen einfachen Makefile-Link kann die CoSort Engine in Natural bis zu sechsmal schneller sortieren als die native Sortierung. Eine vollständige Anleitung zur Verwendung von CoSort und einer externen Sortierung finden Sie in der Installationsdokumentation der Software AG Natural unter "Re-Linking a Natural Nucleus". CoSort´s erschwingliche, bequeme und schnellere Möglichkeit zur Verarbeitung und Berichterstattung großer Dateien, während Sie große Arbeitsdateien von und nach Natural bewegen und gezielt einsetzen. Schließlich kann es erforderlich sein, dass CoSort Daten in Adabas-Quellen und -Zielen manipuliert, maskiert, repliziert, von ihnen…
-
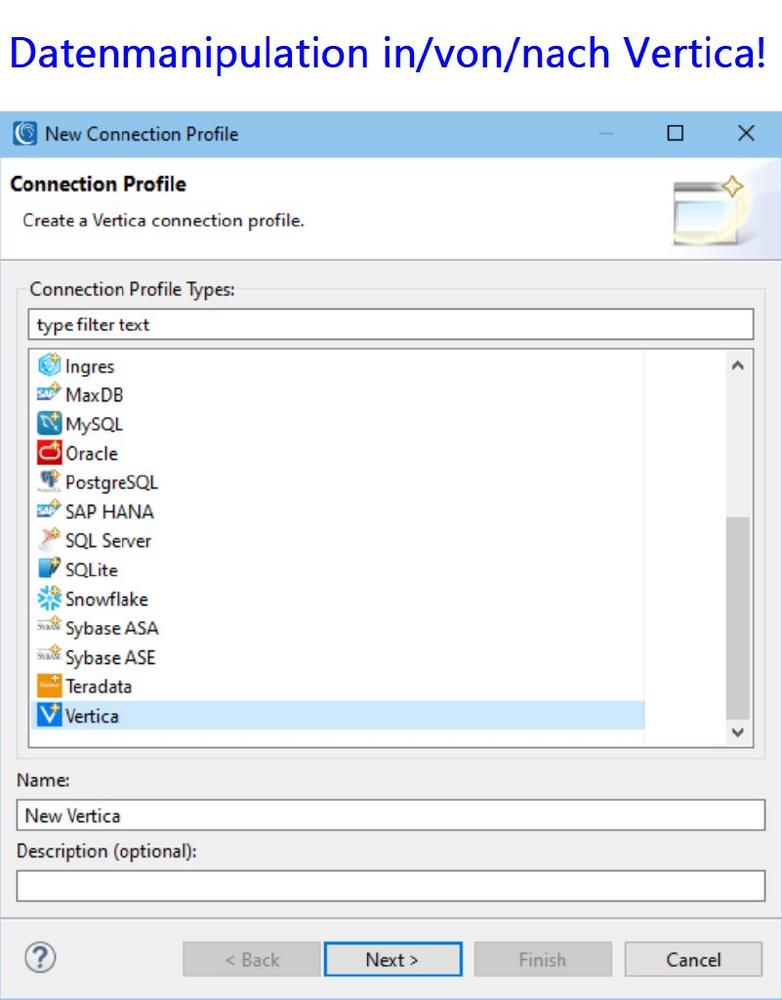
❌ Vertica Datenbank ❌ Schnellere Datenintegration und Datenmigration von VLDB mit Datenschutz für Vertica Database ❗
Schnellstes Big Data Management: Wie andere Artikel in unserem Blog über die Verbindung und Konfiguration von relationalen Datenbanken mit der IRI Voracity Datenmanagement-Plattform beschreibt dieser Artikel detailliert, wie man gezielt Vertica-Quellen erreicht. Die IRI Voracity Datenmanagement-Plattform besteht aus ihren Ökosystemprodukten: IRI CoSort für schnellste Big Data Manipulation seit 1978 IRI NextForm zur Datenmigration und -formatierung IRI FieldShield zur Datenmaskierung von sensiblen Daten in semi- un strukturierten Quellen IRI DarkShield zur Datenmaskierung von sensiblen Daten in semi- und unstrukturierten Quellen IRI RowGen zur synthetischen Testdatengenerierung Dieser Artikel beschreibt detailliert, wie man Vertica-Quellen erreicht. Er beschreibt näher die ODBC- und JDBC-Verbindungen und Konfigurationen, die erforderlich sind, um Vertica mit der SortCL-Engine und…
-
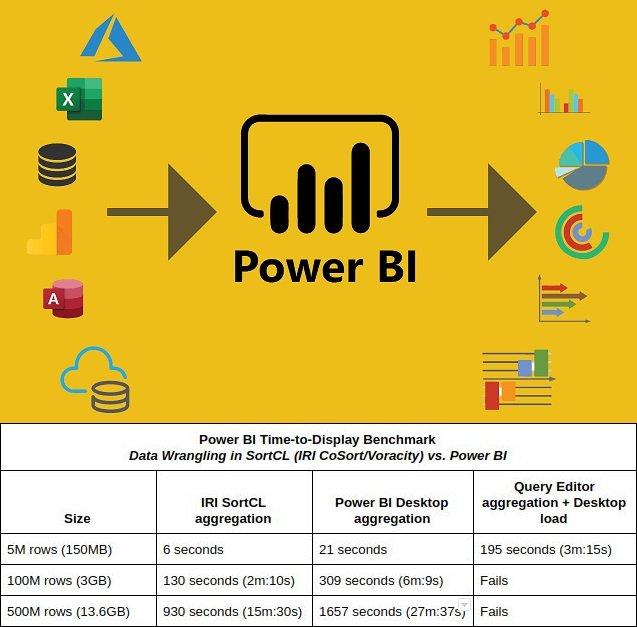
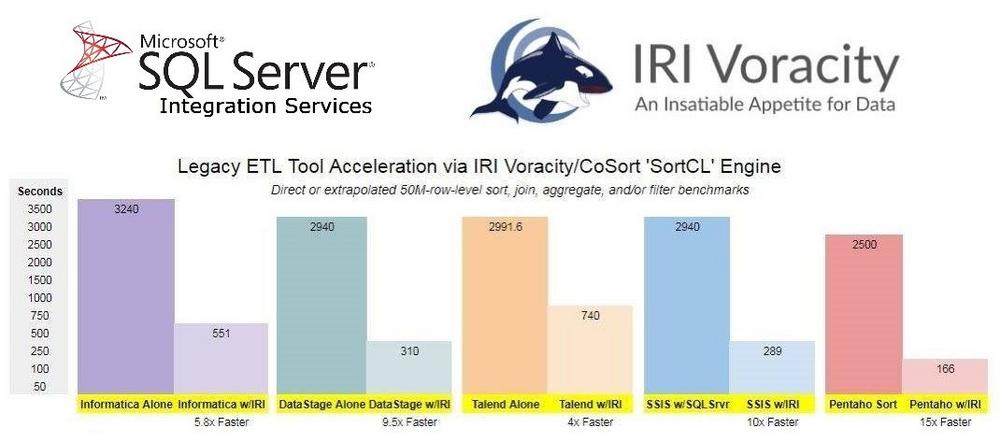
❌ Microsoft Power BI ❌ 20x schnellere Datenintegration und Datenvisualisierung, mit Datenbereinigung und Datenmaskierung ❗
Schnellere Datenvorbereitung für Power BI: Power BI ist ein beliebtes Self-Service-Business Intelligence-Tool von Microsoft. Es kann individuell gestaltete Dashboards und Berichte erstellen, die für die Web- oder mobile Darstellung vorbereitet sind. Das Paket ermöglicht es Endanwendern Berichte und Dashboards ohne Unterstützung der IT-Abteilung zu erstellen. Einfache Datenwrangling-Aufträge wie Sortierung und Aggregation vor und nach der Anzeige der Daten können dauern jedoch zu lange oder stürzen ab, wenn sie mit großen Datenquellen versorgt werden. Power BI mit mehr Power: Wenn Sie mehrere oder hochvolumige Datenquellen erfassen, integrieren, bereinigen oder maskieren müssen, sollten Sie dies außerhalb der BI-Schicht tun! Das Programm SortCL im IRI CoSort Paket oder die Datenmanagement-Plattform IRI Voracity wickelt…
-
❌ MariaDB und MySQL ❌ Schnellere Datenbankabfrage- und Ladeleistung, sowie sensible PII schützen ❗
Die Lösung für zeitaufwendige Probleme bei der Arbeit mit MariaDB- und MySQL-Datenbanken: Datenermittlung: Profilerstellung, Klassifizierung, ERDs Be- und Entladen großer Tabellen Routinemäßige Versorgungsoperationen (Reorgs) Komplexe Abfragen Migration oder Replikation Maskierung sensibler Daten Generierung intelligenter und sicherer Testdaten Auch spezifische Leistungsdiagnosen und -abstimmungen brauchen Zeit und können andere Benutzer betreffen. Schließlich können gespeicherte SQL-Prozeduren auch ineffizient programmiert werden, erfordern eine Optimierung und dauern dann immer noch zu lange. Beschleunigen Sie die Entladung: Verwenden Sie IRI FACT (Fast Extract) zur Beschleunigung der MySQL-Entladung. Verwenden Sie die SQL-Syntax in FACT’s CLI oder GUI, um Tabellendaten in Flat-Files zu übertragen. Geben Sie SELECT * aus der Tabelle an, damit Sie das Entladen nicht mit…
-
❌ Microsoft SQL Server ❌ 10-fache ETL-Beschleunigung, Data Preparation und DSGVO-konformen Datenschutz gewährleisten ❗
Herausforderungen: Möglicherweise haben Sie eines oder mehrere dieser zeitaufwendigen Probleme bei der Arbeit mit MS SQL Server-Datenbanken lokal oder in der Azure-Cloud: Datenermittlung: Profilerstellung, Klassifizierung, ERDs Be- und Entladen großer Tabellen Routinemäßige Versorgungsoperationen (Reorgs) Komplexe Abfragen oder PowerBI-Performance Migrations- oder Replikationsarbeiten Schlechte Datenqualität oder Einheitlichkeit Zugriffs- und Aktivitätskontrolle, Überwachung und Audit (Firewall) Maskierung von PII in Tabellen statisch oder in Anwendungen wie MS Dynamics dynamisch Generierung intelligenter und sicherer Testdaten für Prototyping, DevOps, Demos, etc. Auch spezifische Leistungsdiagnosen und -abstimmungen brauchen Zeit und können andere Benutzer betreffen. Schließlich können gespeicherte SQL-Prozeduren auch ineffizient programmiert werden, müssen optimiert werden und dauern dann immer noch zu lange. Lösungen: Einfache und kostengünstige IRI-Software…
-
❌ Push von IBM Informix ❌ Schnellere Datenintegration von/nach Informix und DSGVO-konformen Datenschutz von OLTP- und IoT-Daten gewährleisten❗
Schnelleres Datenmanagement und höchste Datensicherheit in nur einer Konsole! IRI Workbench™ ist die kostenlose grafische Benutzeroberfläche (GUI) und integrierte Entwicklungsumgebung (IDE) für alle IRI-Datenmanagement- und Schutzsoftwareprodukte und die Voracity-Plattform, die sie beinhaltet. Die unter Windows, MacOS und Linux verfügbare Workbench steuert Aufträge über bewährte IRI CoSort und Hadoop Engines und nutzt dabei alles, was Eclipse™ bietet. Dieser Artikel dokumentiert die Verbindungen, die in IRI Workbench- und 64-bit CoSort-kompatiblen Runtime-Umgebungen erforderlich sind, um mit 64-bit Informix Dynamic Server (IDS) v12 Tabellenquellen und -zielen zu arbeiten. Wie Sie sehen werden, laufen diese Schritte auf die gleiche Weise ab wie andere RDBMS-Verbindungen, die wir in diesem Blog dokumentiert haben, einschließlich: MS SQL, Oracle, PostgreSQL, Salesforce, Snowflake und Teradata. In jedem Fall ist eine JDBC-Verbindung erforderlich, um das visuelle Browsen und den…