-
❌ Testautomatisierung ❌ Den Testentwurf automatisieren für eine effizientere Testautomatisierung ❗
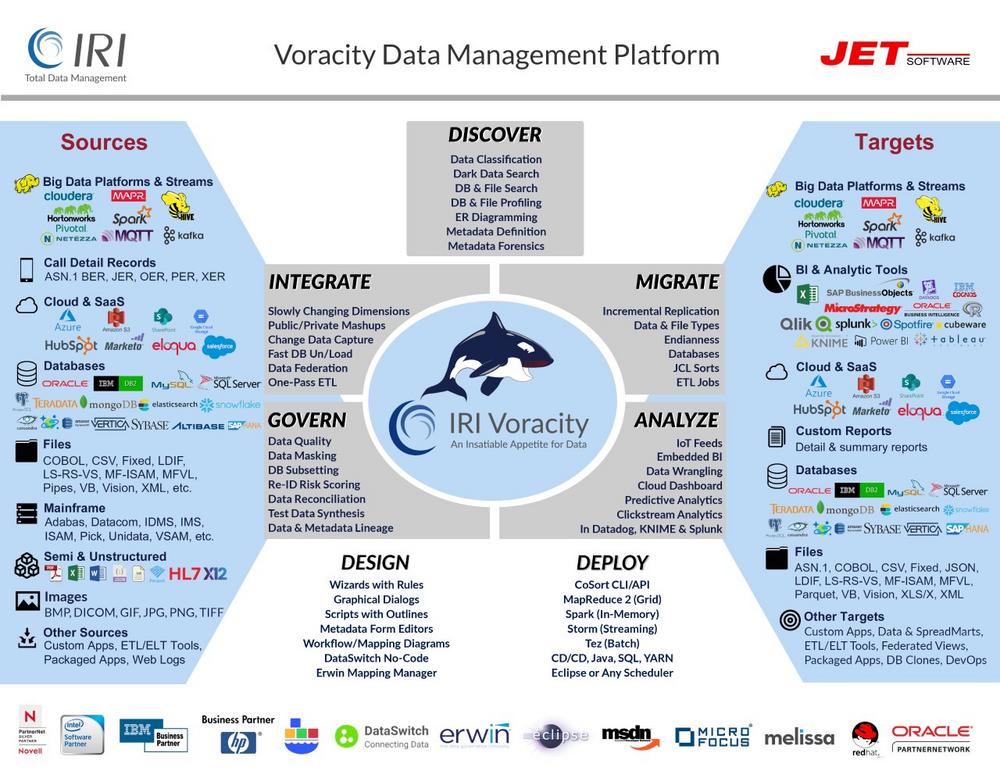
Testautomatisierung: Automatisierung des Testentwurfs! Dies ist der erste in einer Reihe von Blog-Beiträgen, die die verschiedenen Datenmanagement-Funktionen von IRI Voracity in einer Reihe von Kontexten und Anwendungsfällen hervorheben werden. Auf höchster Ebene ist Voracity eine Datenmanagement-Plattform, die eine breite Palette von datenorientierten Funktionen bietet und auf die über die IRI Workbench zugegriffen wird, eine assistentengesteuerte Benutzeroberfläche, die durch grafische Modellierung unterstützt wird. Zum Auftakt dieser Serie beginnen wir mit einem Thema, das uns sehr am Herzen liegt: die Automatisierung des Testentwurfs. Für diejenigen unter Ihnen, die es noch nicht wissen: Die Automatisierung des Testentwurfs ist philosophisch gesehen eine Weiterentwicklung der Testautomatisierung, die den Einsatz der Automatisierung als Ganzes und während…
-
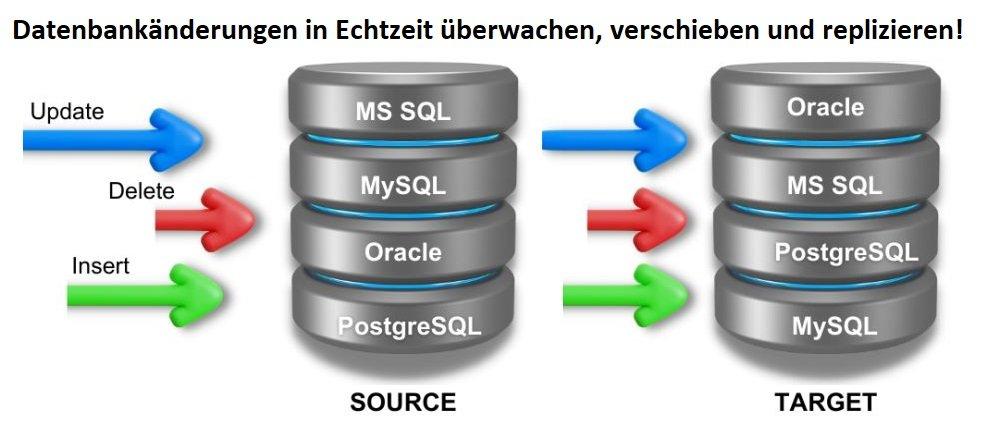
❌ Datenbankreplikation ❌ In Echtzeit Quelldatenbank(en) überwachen mit automatischer Datenreplikation in Zielsilo(s) ❗
Was ist IRI Ripcurrent? Ripcurrent ist der Name einer von IRI entwickelten Java-Anwendung, die die eingebettete Debezium-Engine und die Streaming-Funktion des SortCL-Programms von IRI CoSort kombiniert, um in Echtzeit auf Datenbank-Änderungsereignisse zu reagieren, indem Daten an nachgelagerte Ziele repliziert werden, optional mit Transformationsregeln (z. B. PII-Maskierung), die konsequent auf der Grundlage der Klassifizierung der Daten angewendet werden. Ripcurrent lässt sich mit Debezium integrieren, um Änderungen von verschiedenen DBs zu verfolgen. Ripcurrent bündelt Debezium-Konnektoren für MySQL, SQL Server, PostgreSQL und Oracle. Debezium unterstützt MongoDB, DB2 und Vitess, aber es ist mehr Arbeit erforderlich, um Ripcurrent für diese zu unterstützen. Ripcurrent veranlasst SortCL automatisch, auf eingefügte, aktualisierte oder gelöschte Datenzeilen zu reagieren.…
-
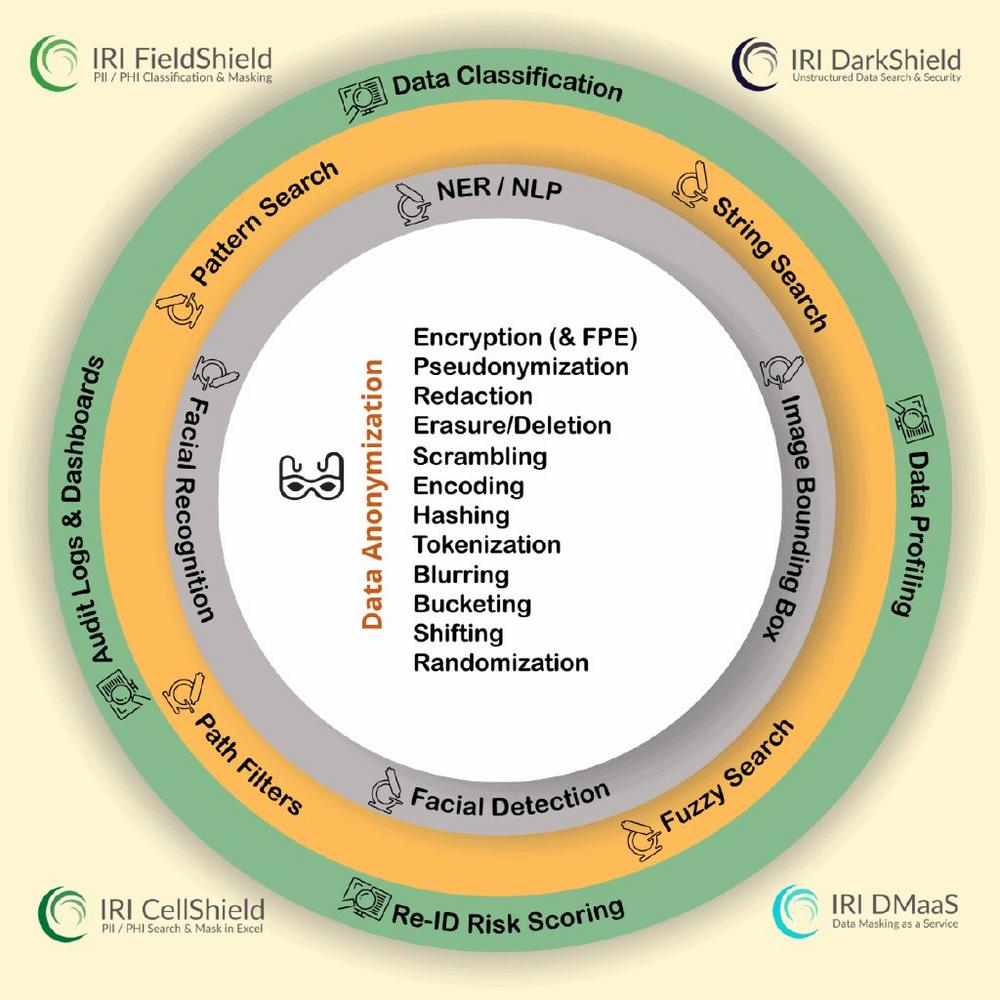
❌ Dark Data finden ❌ Gezielter Datenschutz in unstrukturierten Daten wie Microsoft Office-Dokumenten, PDF, Bildern und Textdateien ❗
Tensorflow- und PyTorch-NER-Modelle: Die Erkennung von benannten Entitäten (Named Entity Recognition, NER) ist eine Art des maschinellen Lernens (ML), um benannte Entitäten im grammatikalischen Kontext von unstrukturiertem Text (Dokumenten) zu erkennen. NER wird benötigt, um Dinge wie Personennamen und Straßenadressen zu finden, da diese weder Mustern entsprechen, noch wahrscheinlich eine Übereinstimmung mit Werten in einer definierten Liste (Lookup Set) haben. Da es sich bei vielen Entitäten wie Personennamen oder Adressen um persönlich identifizierbare Informationen (PII) handelt, verwendet IRI DarkShield NER, um solche Daten zu finden und zu maskieren. Während die Kenntnis des Namens einer Person allein vielleicht kein allzu großes Risiko darstellt, erhöht sich in Kombination mit anderen sensiblen Daten…
-
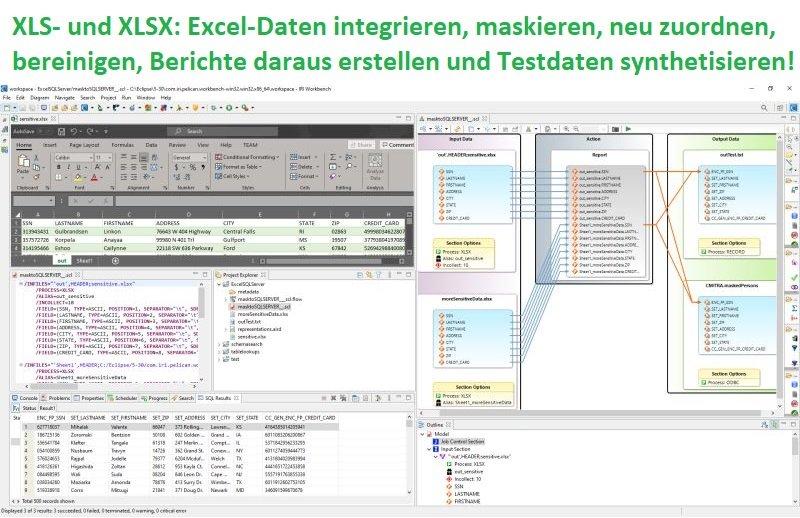
❌ Datenschutz in Excel ❌ Individuelle oder globale Funktionen zur Datenmaskierung in XLS- und XLSX-Dateien ❗
Welches ist das beste Tool, um sensible Daten in Excel zu schützen? Die auch einzeln verfügbaren drei Produkte der IRI Data Protector Suite haben gemeinsame Suchmethoden (wie Muster- oder Wörterbuchabgleiche) und individuell oder global anwendbare Datenmaskierungsfunktionen (wie Verschlüsselung, Redigierung, Hashing und Pseudonymisierung). Alle drei können daher identische und potenziell austauschbare Chiffretexte erzeugen, um Determinismus und Datenintegrität zu wahren. Sie sind auch alle unterstützte Komponenten der IRI Voracity Datenmanagement-Plattform: IRI FieldShield wurde entwickelt, um strukturierte Datenbank- und Flat-File-Daten zu klassifizieren, zu suchen und zu maskieren. FieldShield verwendet das CoSort SortCL-Programm zur Datendefinition und -manipulation, um Quell- und Ziellayouts sowie alle Mapping-/Maskierungstransformationen zu definieren. SortCL verwendet 4GL-Job-Skripte, die in der Regel…
-
❌ Datensicherheit in der Cloud ❌ Reversible Datenmaskierung in semi- und unstrukturierten Dark Data Dateien in S3, GCP und Azure BLOB ❗
IRI DarkShield ist ein Datenmaskierungswerkzeug zum Auffinden und De-Identifizieren sensibler Daten in semi- und unstrukturierten Dateien und Datenbanken. DarkShield ist eines der drei zentralen Datenmaskierungsprodukte der IRI Data Protector Suite, die grafische Datenklassifizierungs-, Such- und Maskierungsjob-Designmodelle in der IRI Workbench IDE, die auf Eclipse basiert, nutzen können. Es werden zwei leistungsfähige Remote Procedure Call (RPC) Application Programming Interface (API)-Versionen zur Verfügung gestellt: die "Base" DarkShield API und die DarkShield-Files API. Um sensible Daten in einer Vielzahl von Quellen zu finden und zu schützen, verwenden die DarkShield-APIs spezifizierte Suchabgleiche und Maskierungsregeln, die Geschäftsregeln folgen. Weitere Informationen zur Erstellung von Suchabgleichern und Maskierungsregeln finden Sie in diesem Artikel. Die DarkShield-Basis-API wird für…
-
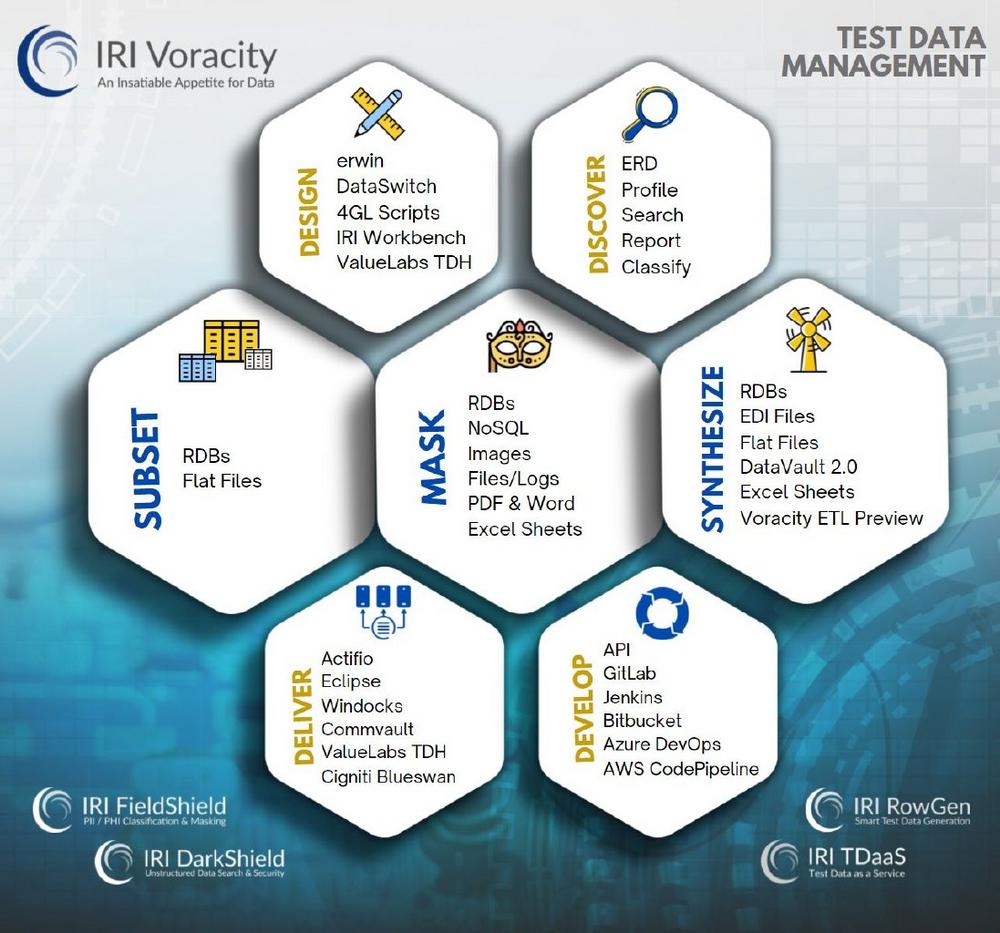
❌ TDM Tool ❌ Vielschichtiges Testdatenmanagement-Framework für DevOps, MLOps und DataOps bereitstellen❗
Sicheres Testdatenmanagement: Daten, die durch Anwendungsentwicklung, maschinelles Lernen und Analysepipelines fließen, müssen mehrere Anforderungen erfüllen, die allen Bereichen gemeinsam sind, darunter: Realitätsnähe, um die Eigenschaften der Produktionsdaten und die Anforderungen der Anwendungstests widerzuspiegeln Konformität mit Geschäfts- und Datenschutzregeln sowie DB- und Analysemodellen Verfügbarkeit oder Sicherheit der Daten (je nach Sichtweise) Nachvollziehbarkeit für die Abstammung und Verantwortlichkeit Die an diesen Pipelines beteiligten Akteure verstehen diese Anforderungen aus ihrer eigenen Perspektive. IRI, auch bekannt als "The CoSort Company", bietet ein vielschichtiges Testdatenmanagement-Framework, um diese Anforderungen zu erfüllen. Die Rolle von IRI in diesem weiten Bereich begann mit der Notwendigkeit, umfangreiche, realistische Daten zu erstellen, um das Volumen und die Vielfalt der Datenumwandlungs-…
-
❌ Datenschutz im Bild ❌ Bildvorverarbeitung um sensible Daten in Bildern zu finden und per Datenmaskierung direkt GDPR-konform zu schützen❗
Vorverarbeitung von Bildern zur Verbesserung der OCR-Ergebnisse: OCR-Software (Optical Character Recognition) ist eine Technologie zur Erkennung von Text in einem digitalen Bild. OCR wird von der IRI DarkShield-Software verwendet, um Text in eigenständigen oder eingebetteten Bildern während der PII-Suche und -Maskierungsvorgänge zu erkennen. OCR hat jedoch ihre Grenzen: Um genaue Ergebnisse zu erzielen, muss das Bild vertikal ausgerichtet sein, die richtige Größe haben und so klar wie möglich sein. Nicht jedes Bild erfüllt diese Anforderungen! Wir müssen daher Methoden finden und anwenden, um diese Bilder durch Vorverarbeitung an unsere Bedürfnisse anzupassen. In diesem Artikel werden einige Vorverarbeitungsmethoden vorgestellt und erläutert, wie sie die Qualität der OCR-Ausgabe im Zusammenhang mit der…
-
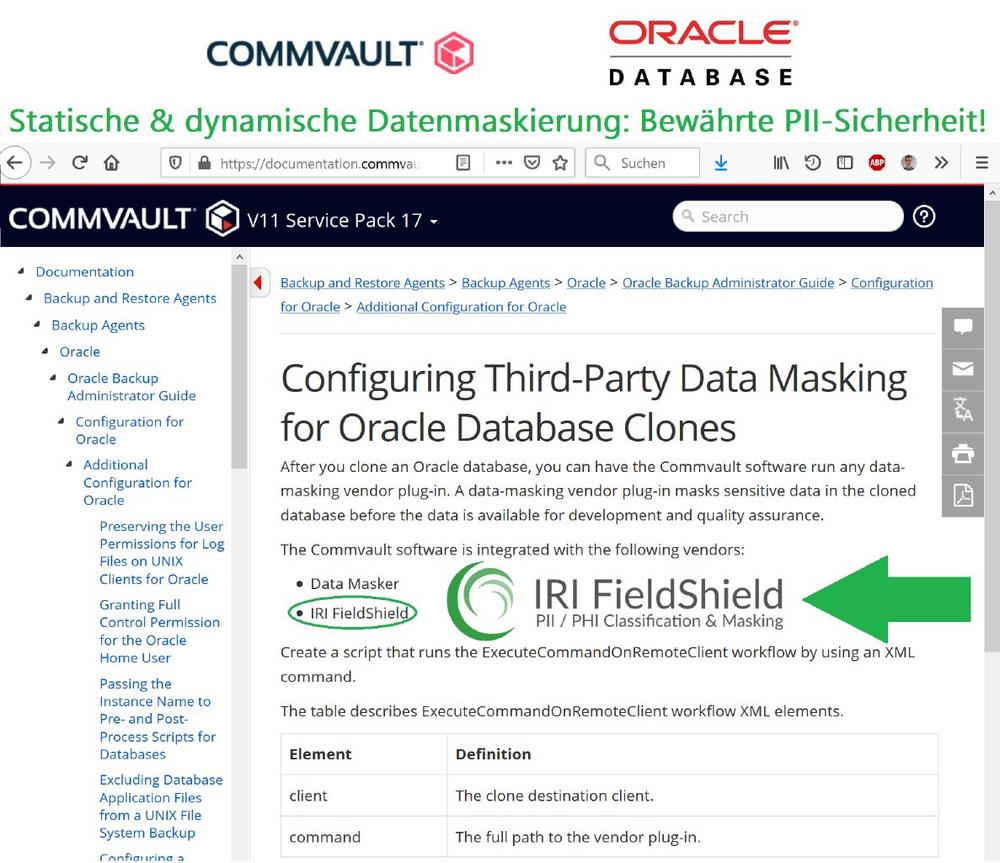
❌ Backup mit Commvault ❌ Oracle Datenbank mit Datensicherheit von sensiblen Daten per bspw. Datenmaskierung ❗
Sichere Datenverarbeitung von geklonter Datenbank: Das Sicherheitsprodukt IRI FieldShield maskiert sensible Daten in der geklonten Datenbank, bevor die Daten für die Entwicklung und Qualitätssicherung zur Verfügung stehen! Nachdem Sie eine Oracle-Datenbank geklont haben, können Sie die Commvault-Software mit unserer Datenmaskierung via Plug-In ausführen lassen. Die Commvault-Software ist bei unserem IRI FieldShield integriert. Die Anleitung finden Sie direkt bei Commvault V11 Service Pack 17 unter: "Configuring Third-Party Data Masking for Oracle Database Clones" Was ist FieldShield? IRI FieldShield® ist eine leistungsstarke und kostengünstige Software zur Datenerkennung und –maskierung von PII in strukturierten und semistrukturierten Quellen, groß und klein. Die FieldShield-Dienstprogramme in Eclipse dienen zur Profilierung und De-Identifizierung von Daten im Ruhezustand…
-
❌ UniKix TPE und BPE ❌ Transaktionsverarbeitung und Batch-Sortierung von VSAM- und sequentiellen Daten ❗
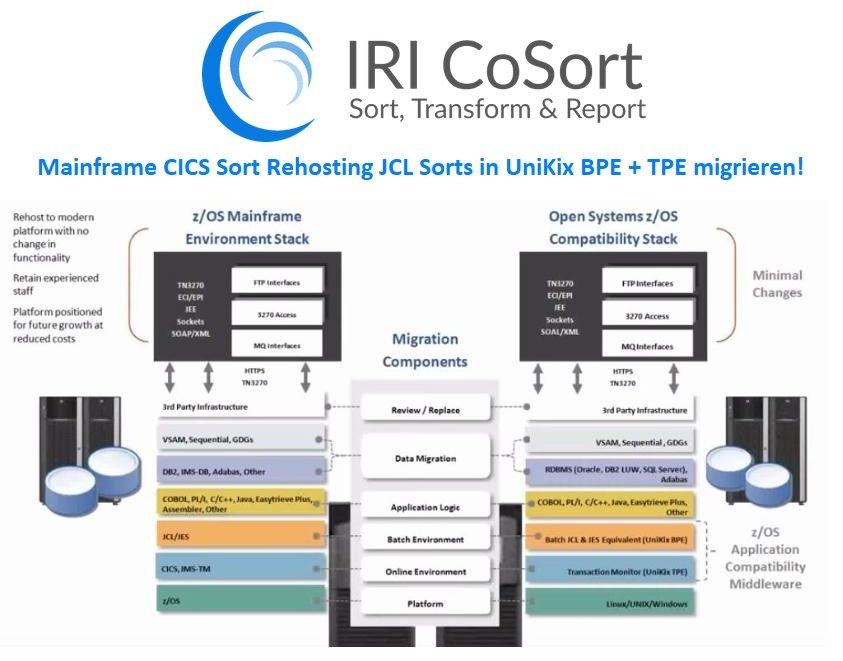
Mainframe CICS Sort Rehosting: JCL Sorts in UniKix BPE und TPE migrieren! Herausforderungen: Wenn Sie vom Mainframe zu "offenen Systemen" wechseln, arbeiten Sie möglicherweise mit dem Mainframe Rehosting Solutions Team von NTT DATA (früher Dell, Clerity, Sun, Blue Phoenix und UniKix) zusammen. Eine der Komponenten Ihrer Migration wird das Sortierpaket sein. Sie benötigen eine Lösung für die Konvertierung von JCL-Sortierschritten, die Verarbeitung von VSAM-Dateien, die damit verbundene Datentransformation und Berichtsdienste unter Unix oder Windows. Möglicherweise suchen Sie auch nach einer Möglichkeit, eine Vielzahl anderer Datenmanagement- und Schutzvorgänge gleichzeitig zu modernisieren und möchten lieber mit einem einzigen, bewährten und erschwinglichen Anbieter zusammenarbeiten und gleichzeitig die Lernkurve und die Komplexität der…
-
❌ Data Lake ❌ Bündelung von semi/un/strukturierten Rohdaten und schnelle Datenverarbeitung in wenigen Schritten ❗
Data Lake: Ein Data Lake ist ein einziger Speicher für Unternehmensdaten, der sowohl Rohdaten (die eine exakte Kopie der Quelldaten darstellen) als auch umgewandelte Daten enthält, die für Berichte und Analysen verwendet werden. Einige wollen, dass das Data Lake das traditionelle Data Warehouse ersetzt, während andere ihn eher als Staging-Bereich für die Einspeisung von Daten in bestehende Data Warehouse-Architekturen sehen. Den See säubern: Ein Hauptproblem bei Datenseen ist, wie bei echten Seen, dass die Menschen nicht wissen, was sich in ihnen befindet oder wie sauber sie sind. In der Natur können unbekannte Dinge im Wasser das Ökosystem zerstören. Unbekannte Daten in einem Datensee können das Projekt zerstören. Auch dazu rät…