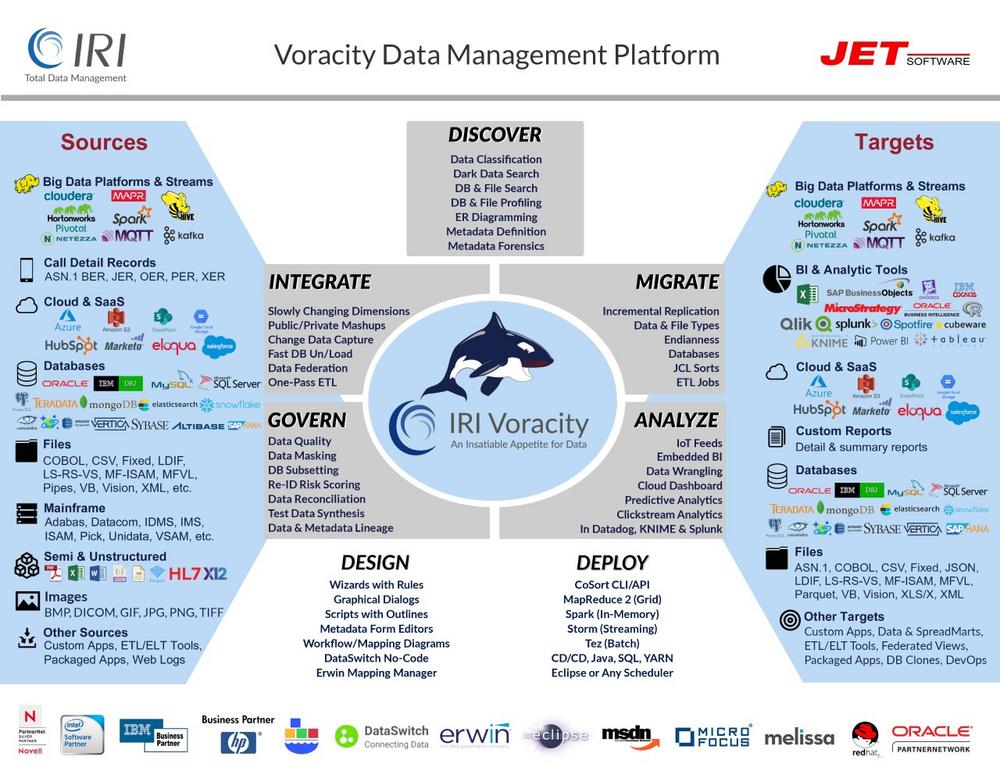
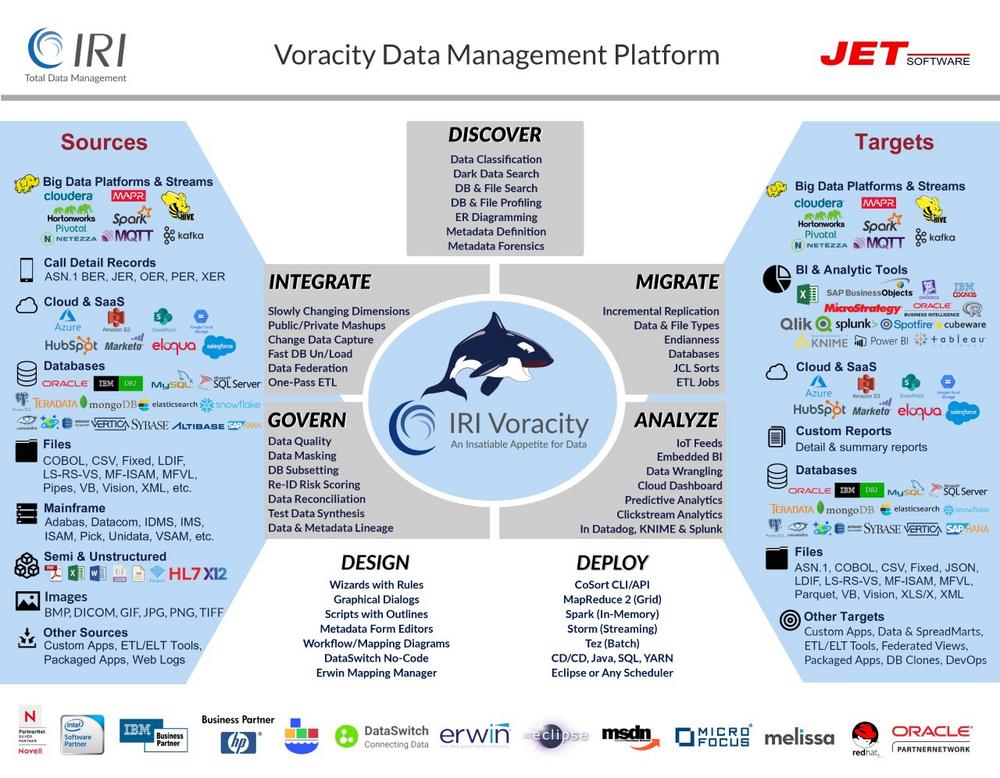
-
❌ TIBCO Spotfire ❌ 4x schnellere Datenvisualisierung und Datenanalyse für Datenintegration in BI-Tool TIBCO Spotfire ❗
Vorbereitung von Big Data für TIBCO Spotfire: TIBCO Spotfire® ist ein Datenvisualisierungstool für einfach zu erstellende Dashboards. Spotfire verfügt über eine speicherinterne Datenverarbeitung und eine ausgefeilte prädiktive Analyse. Wie die meisten Business Intelligence-Tools ist es jedoch nicht für die Integration großer Datenmengen und die Verarbeitung vor der Visualisierung konzipiert. Das SortCL-Programm im IRI CoSort Produkt oder in der IRI Voracity Plattform ist eine schnelle, einfache und kostengünstige Möglichkeit, große Datenmengen für Spotfire effizient aufzubereiten – sowohl in Bezug auf das Jobdesign als auch auf die Laufzeitperformance. In diesem Abschnitt erfahren Sie, warum. Wenn SortCL Rohdatensätze in einem einzigen Job und I/O-Pass vor Spotfire sortiert, zusammenführt und aggregiert, ist eine solche…
-
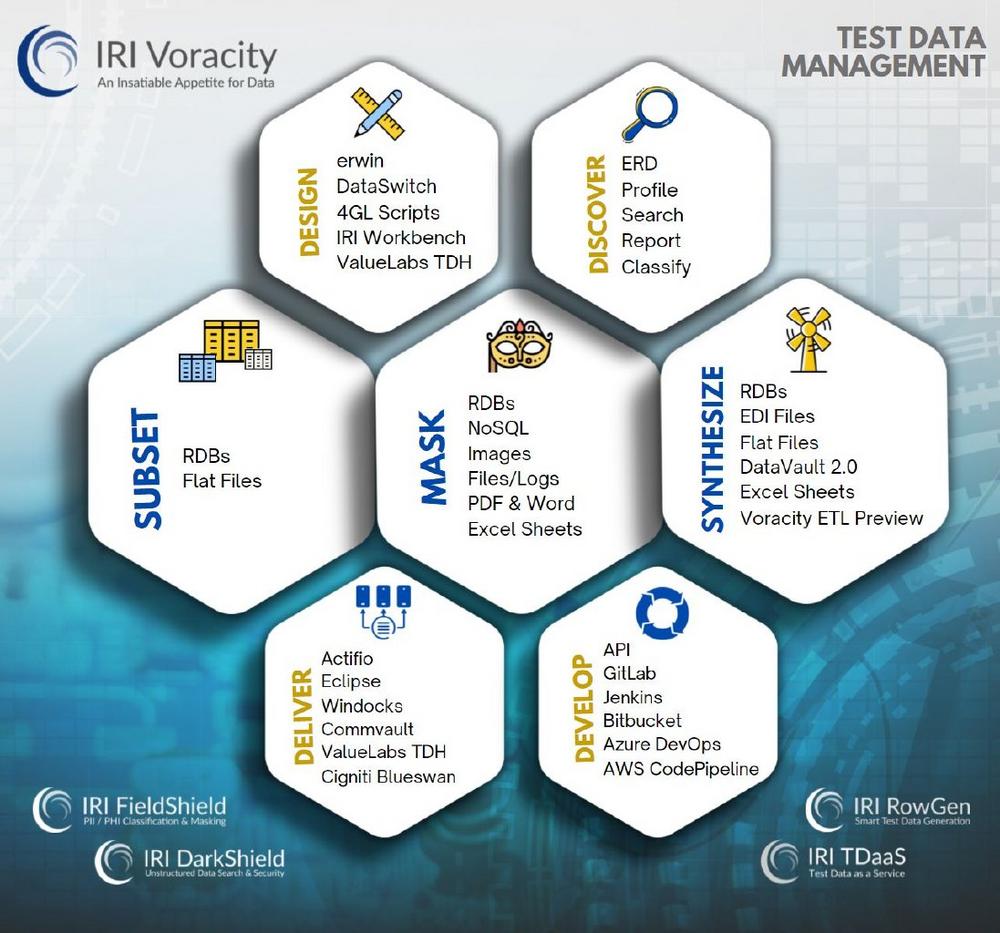
❌ Testdatenmanagement ❌ Sichere, realistische und referenziell korrekte Testdaten für DevOps und CI/CD erstellen❗
Intelligente Testdaten erstellen und verwalten für: Test-Datenbanken mit referentieller Integrität Simulation und Freigabe von Datei- und Berichtslayouts Entwicklung und Stresstest von Anwendungen Benchmarking neuer Hard- und Software Durchführung von Data Warehouse ETL-Tests Tabellenansichten, Indexreihenfolgen, Schlüsselbeziehungen sowie Datei- und Berichtsinhalte müssen die Realität widerspiegeln, um beim Testen nützlich zu sein. Das Erzeugen realistischer Werte und Formate mit sicheren Daten in idealen Bereichen – und das Befüllen großer Ziele – kann mit anderen Tools oder Programmen sehr lange dauern. Mit dem IRI RowGen-Produkt oder der IRI Voracity-Plattform können Sie mehrere Testdatenziele für Testdatenbanklasten, Flat-File-Strukturen und benutzerdefinierte Berichtsformate von Grund auf neu generieren – alles ohne Zugriff auf echte Daten. Oder wenn Sie…
-
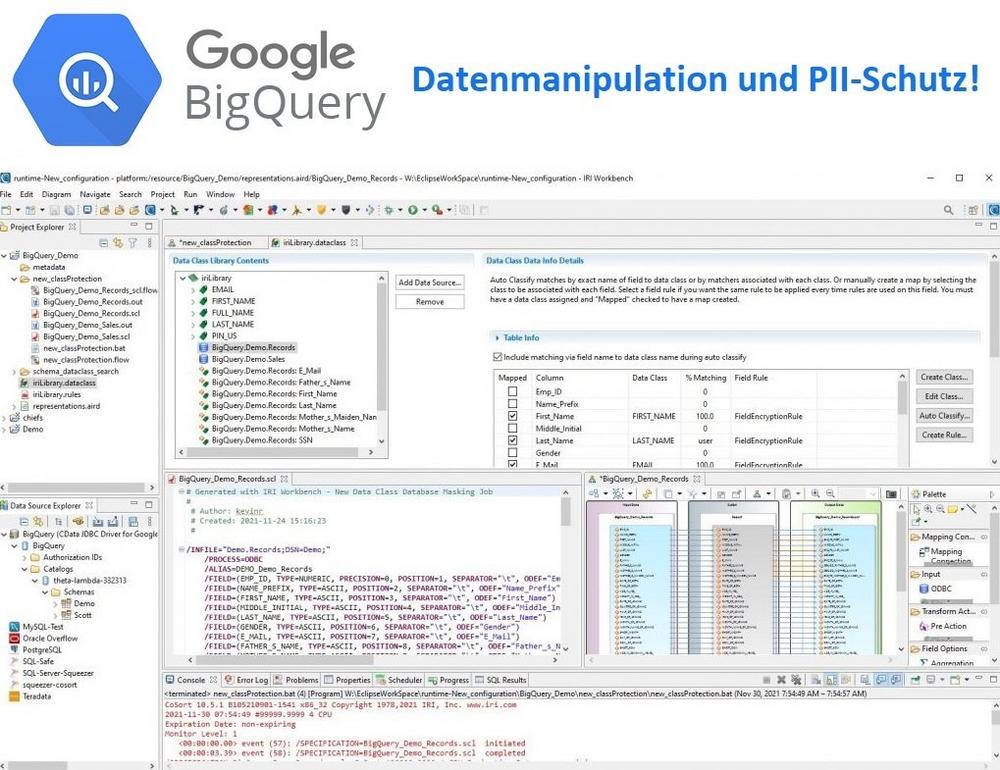
❌ Google BigQuery ❌ Back-End Datenverarbeitung für die Datentransformation im serverlosem Data Warehouse in der Google Cloud ❗
BigQuery ist ein verwaltetes, serverloses Data Warehouse in der Google Cloud, das skalierbare Analysen über Petabytes von Daten ermöglicht. Es handelt sich um eine relationale Datenbank als Platform as a Service (PaaS), die ANSI-SQL-Abfragen unterstützt. Als solche arbeitet sie mit der umfangreichen IRI-Software. Die Verbindung der Google BigQuery RDB mit IRI Workbench und dem Back-End-Verarbeitungsprogramm SortCL ist einfach und ermöglicht die Bewegung und Manipulation der strukturierten Daten durch kompatible IRI-Produkte. Das bedeutet IRI CoSort für schnellste Datentransformation, IRI FieldShield für Datenmaskierung, IRI NextForm für Datenmigration und IRI RowGen für synthetische Testdatengenierung oder die End-to-End Datenmanagementplatfform IRI Voracity, die alle diese einzelnen Produkte umfasst und weitere Funktionen bietet! Die Konnektivität folgt…
-
❌ Oracle Linux ❌ Beschleunigung von ETL-Aufträgen mit End-to-End Datensicherheit via Datenmaskierung und synthetischen Testdaten❗
Die stärkste Plattform für End-to-End Datenmanagement: Das Team der Oracle Linux und „Virtualization Alliance“ heißt die Datenverwaltungsplattform Voracity im ISV-Ökosystem willkommen. IRI Inc. hat Voracity auf Oracle Linux zertifiziert und unterstützt diese Plattform. Damit steht Oracle-DBAs, Datenarchitekten und Datenschutzteams schnellste Leistungs- und umfassende Sicherheitsfunktionen zur Verfügung. IRI Voracity kombiniert Datenermittlung, Integration, Migration, Verwaltung und Analyse in einem verwalteten Metadaten-Framework, das auf Eclipse aufbaut. Die Voracity-Plattform läuft in der Oracle Cloud-Infrastruktur und ermöglicht moderne PaaS- und SaaS-Optionen für KMU- und Unternehmenskunden, die eine schnellere, kostengünstigere und hochsichere Cloud-Ausführung von ETL-Aufträgen sowie Datenmaskierung und -synthese, Datenqualität und -migration und Datenmanipulation für Analysezwecke anstreben. In der Oracle Cloud-Infrastruktur oder on premise können Kunden…
-
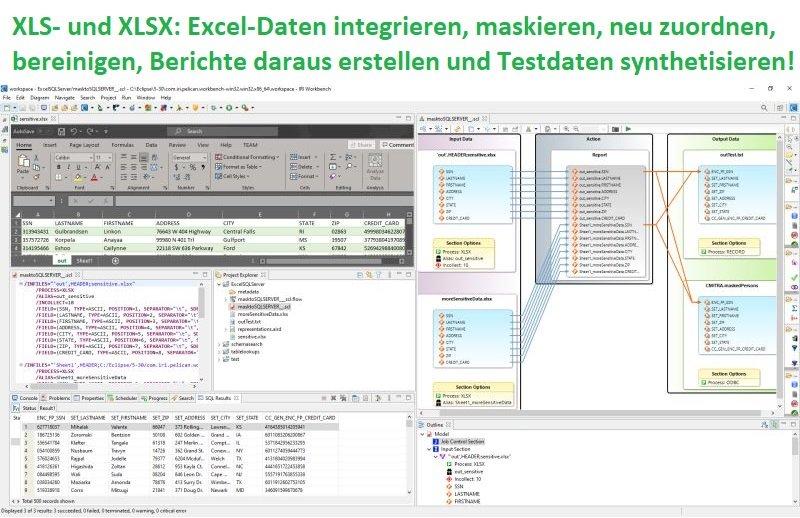
❌ XLS und XLSX ❌ Microsoft Excel Datenintegration, mit Datenbereinigung und Datenmaskierung für BI-Report oder TDM ❗
Zusätzlich zu allen anderen strukturierten Datenquellen ist es jetzt möglich, Daten aus XLS- und XLSX-Dateien im SortCL-Programm zu lesen und zu verarbeiten! IRI CoSort, für schnelles Sortieren, Umwandeln und Berichten IRI NextForm, für Mapping, Migration und Replikation IRI RowGen, für die zufällige Auswahl oder Generierung von realistischen Testdaten IRI FieldShield, für die Maskierung sensibler Daten IRI Voracity, für alle oben genannten Funktionen sowie für ETL, Datenbereinigung und -aufbereitung für Analysezwecke und zum Zurückschreiben der resultierenden Daten in diese oder andere Ziele, einschließlich eines oder mehrerer Blätter. Dieser Artikel gibt einen Überblick über die Operationen und die Syntax des SortCL-Programms, das mit IRI CoSort Version 10.5 eingeführt wurde, um Excel-Daten in…
-
❌ Tuning von VLDB ❌ Datenerfassung beschleunigen für bspw. Data Warehouse, schnellere Datenintegration und Datenmigration❗
Datenerfassung beschleunigen: Unloads 7x schneller! IRI FACT™ ist ein Dienstprogramm zum parallelen Entladen von sehr großen Datenbanktabellen (VLDB). FACT verwendet einfache Job-Skripte (unterstützt in einer vertrauten Eclipse-GUI), um schnell portable Flat-Files zu erstellen. Die Geschwindigkeit von FACT basiert auf nativen Verbindungsprotokollen und einer proprietären Split-Abfragelogik, die Milliarden von Zeilen in Minuten entladen. IRI FACT verwendet native Datenbank-APIs und parallele Verarbeitung, um Tabellen schneller in Flat-Fiels umzuwandeln als jedes andere Entladetool oder -verfahren. FACT skaliert linear im Volumen, so dass das Entladen einer Zwei-Milliarden-Zeilentabelle nicht mehr als doppelt so lange dauern sollte wie das Entladen einer Ein-Milliarden-Zeilentabelle. Die Kombination der leistungsstarken Extraktion von FACT mit den leistungsstarken, konsolidierten Datentransformationen und vorsortierten…
-
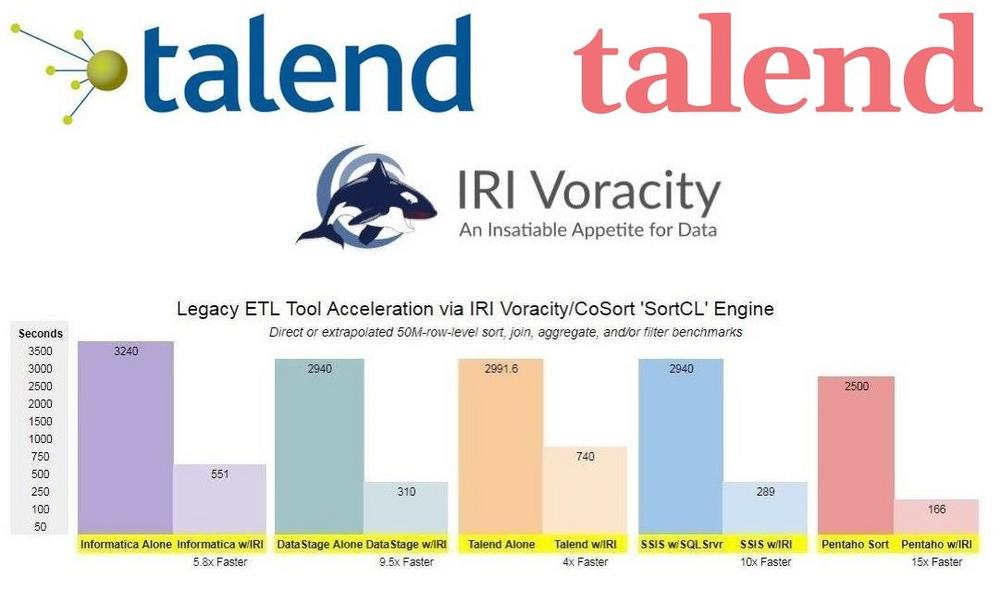
❌ Talend Data Fabric ❌ Schnellere Datenintegration mit Datenschutz via Datenmaskierung und synthetische Testdaten für TDM ❗
Auch nach der Beratung und Abstimmung können große Datenmengen (d.h. mehr als eine Million Zeilen) nur langsam transformiert werden, insbesondere ohne ein teures Hardware- oder Versionsupgrade von Talend! Große Datenengpässe sind große Sortierungen, Joins, Aggregationen, Ladungen und manchmal auch Entladungen. Die Parallelisierung oder Optimierung in anderen Ebenen oder Tools kann unhandlich, wenn nicht sogar teuer sein und die Leistung für andere Benutzer beeinträchtigen. Aus Sicherheitssicht bietet Talend möglicherweise nicht die Funktionen zum Erkennen, Klassifizieren oder Maskieren von Daten oder zum Testen von Datenfunktionen, die Datenverwalter und Anwendungsentwickler benötigen: Transformationen beschleunigen: Sort-Beschleunigung, Aggregation und Zusammenführen von Talend ETL-Strömen mit einem tSystem-Aufruf an die Programme CoSort Sort Sort Control Language (SortCL). Führen…
-
❌ SAP Sybase Datenbank ❌ 12-fache ETL-Beschleunigung und sicherer Datenschutz von Sybase IQ und ASE-Tabellen❗
Als SAP Sybase IQ oder ASE DBA können Sie mit einem oder mehreren dieser Performance- oder Schutzprobleme konfrontiert sein: Entladen und Laden von großen Sybase-Tabellen Langsame Hilfsoperationen (z.B. Reorgs) oder Abfragen Ungeschützte personenbezogene Daten (PII) Lästige Datenbankmigration oder -replikation Generierung von oder Zugriff auf Testdatensätze Auch spezifische Leistungsdiagnosen und -abstimmungen brauchen Zeit und können andere Benutzer betreffen. Spezielle Tools zur Datenmaskierung und zum Testdatenmanagement sind teuer und zu schwer zu bedienen. Schließlich können gespeicherte SQL-Prozeduren auch ineffizient programmiert werden, müssen optimiert werden und dauern dann immer noch zu lange. Beschleunigung der Sybase-Entladung: IRI FACT (Fast Extract), um Transaktionstabellen parallel zu Flat Files auszugeben. FACT unterstützt Sybase IQ und ASE, OCS…
-
❌ Tuning von Datadog ❌ Beschleunigung von Datenintegration und Datenmigration, sowie rechtskonformer Datenschutz in/aus Datadog❗
Was ist Datadog? Datadog ist eine Web-Anwendung zur Überwachung von Datenfeeds (Dateneinspeisung), zur Analyse von Trends, zur Erstellung analytischer Dashboard-Anzeigen und zum Senden von Warnmeldungen. Dieser Artikel ist der erste in einer 4-teiligen Serie über die Fütterung der Datadog Cloud-Analyseplattform mit verschiedenen Arten von Daten aus IRI Voracity-Operationen. In Fällen, in denen eine große Datenmenge offline vorbereitet werden muss, bevor die Daten ausgegeben werden und die Daten auf einer Infrastruktur außerhalb von Datadog verarbeitet werden können, kann Voracity für ein hochleistungsfähiges Daten-Wrangling sorgen. Die Serie konzentriert sich auf den Wert von Datadog und Voracity zusammen: Dieser Artikel beschreibt die Einspeisung verschiedener Daten aus IRI Voracity in die Datadog Cloud-Analyseplattform. Der…
-
❌ Snowflake ❌ Agile Datenintegration und Datenbereinigung mit optional verschlüsselter Datenbereitstellung ❗
Snowflake ETL und PII-Maskierung: Schnelles, kostengünstiges Datenmapping & Verwaltung! Möglicherweise sind Sie mit diesen zeitaufwendigen Problemen bei der Arbeit mit Snowflake konfrontiert: Datensuche, -profilierung und/oder -klassifizierung Integration oder Daten-Wrangling für DW/BI-Ops Datenbewegung/Migration zu/von Tabellen Transformieren oder Laden großer Tabellen Datenerfassung oder -replikation ändern Clustering oder Abfrage der Performance Generierung intelligenter und sicherer Testdaten Maskierung sensibler Daten Auch spezifische Leistungsdiagnosen und -abstimmungen brauchen Zeit und können andere Benutzer betreffen. Schließlich können gespeicherte SQL-Prozeduren auch ineffizient programmiert werden und erfordern eine Optimierung und dauern dann immer noch zu lange! Daten in Ordnung halten: IRI CoSort für die Vorsotierung von Flat-Files für Bulk-Ladungen und Inserts. Das entfernt den Overhead dieser Arbeit von Snowflake,…