-
❌ Spotfire BI-Tool ❌ 4x schnellere Datenaufbereitung für Business Intelligence mit TIBCO Spotfire Datenvisualisierung❗
Vorbereitung von großen Datenmengen für TIBCO Spotfire: TIBCO Spotfire® ist ein Datenvisualisierungstool, das bei Life-Science-Forschern und Finanzunternehmen beliebt ist, die einfach zu erstellende Dashboards benötigen. Spotfire verfügt über eine speicherinterne Datenverarbeitung und eine ausgefeilte prädiktive Analyse. Wie die meisten Business Intelligence-Tools ist es jedoch nicht für die Integration großer Datenmengen und die Verarbeitung vor der Visualisierung konzipiert. Das SortCL-Programm im IRI CoSort Produkt oder in der IRI Voracity Plattform ist eine schnelle, einfache und kostengünstige Möglichkeit, große Datenmengen für Spotfire effizient aufzubereiten – sowohl in Bezug auf das Jobdesign als auch auf die Laufzeitperformance. In diesem Abschnitt erfahren Sie, warum. Wenn SortCL Rohdatensätze in einem einzigen Job und I/O-Pass vor…
-
❌ Datenschutz in Cloud ❌ Reversible Datenmaskierung von sensiblen PII in semi/unstrukturierten Dark Data Dateien in S3, GCP & Azure BLOB Speicher ❗
Schneller und sicherer Datenschutz: IRI DarkShield ist ein Datenmaskierungswerkzeug zum Auffinden und De-Identifizieren sensibler Daten in semi- und unstrukturierten Dateien und Datenbanken. DarkShield ist eines der drei zentralen Datenmaskierungsprodukte der IRI Data Protector Suite, die grafische Datenklassifizierungs-, Such- und Maskierungsjob-Designmodelle in der IRI Workbench IDE, die auf Eclipse basiert, nutzen können. Es werden zwei leistungsfähige Remote Procedure Call (RPC) Application Programming Interface (API)-Versionen zur Verfügung gestellt: die "Base" DarkShield API und die DarkShield-Files API. Um sensible Daten in einer Vielzahl von Quellen zu finden und zu schützen, verwenden die DarkShield-APIs spezifizierte Suchabgleiche und Maskierungsregeln, die Geschäftsregeln folgen. Weitere Informationen zur Erstellung von Suchabgleichern und Maskierungsregeln finden Sie in diesem Artikel.…
-
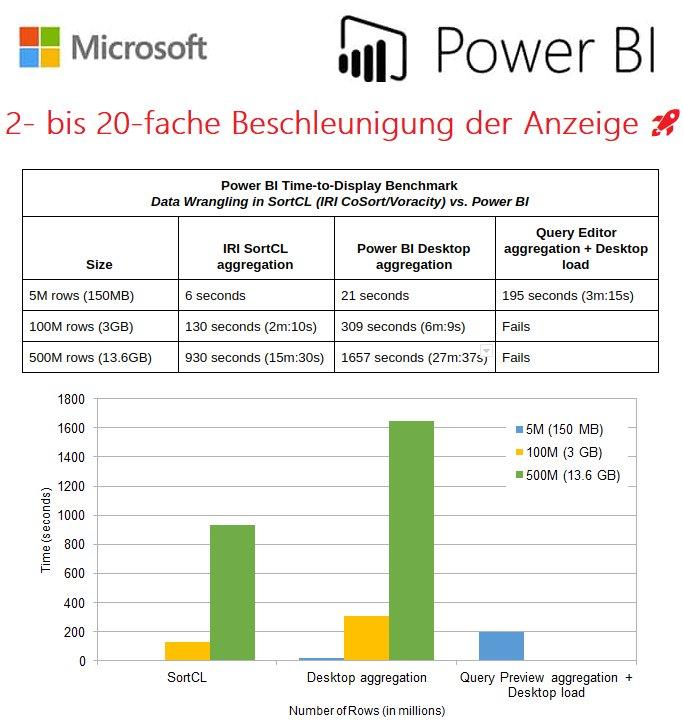
❌ Microsoft Power BI ❌ 20-fache Beschleunigung der Datenvisualisierung durch externe Datentransformation ❗
Datenvorbereitung für Power BI: Erhalten Sie schnellere Einblicke in Ihre Daten! Power BI ist ein beliebtes Self-Service-Business Intelligence-Tool von Microsoft. Es kann individuell gestaltete Dashboards und Berichte erstellen, die für die Web- oder mobile Darstellung vorbereitet sind. Das Paket ermöglicht es Endanwendern Berichte und Dashboards ohne Unterstützung der IT-Abteilung zu erstellen. Das PC Magazin zeichnete Power BI im Sommer 2018 mit der Editor’s Choice Auszeichnung aus: "für seine beeindruckende Benutzerfreundlichkeit, seine erstklassigen Datenvisualisierungsfunktionen und seine hervorragende Kompatibilität mit anderen Microsoft Office Produkten". Einfache Datenwrangling-Aufträge wie Sortierung und Aggregation vor und nach der Anzeige der Daten können sich jedoch ziehen oder abstürzen, wenn sie mit großen Datenquellen versorgt werden. Power…
-
❌ Test Data Generation ❌ Synthetische Testdaten in relationalen Cloud- oder NoSQL-DBs verwenden, anstatt mit Produktionsdaten zu testen❗
IRI RowGen ist das einzige Tool, das für große, strukturierte und semi-strukturierte Datenumgebungen mit mehreren Zielen konzipiert ist, die sichere und realistische Testdaten erfordern. RowGen erzeugt riesige Testdatenmengen für Datenbanken, BI- und DW-ETL/ELT-Tools und benutzerdefinierte Berichtsformate. Das einfache Batch-Ausführungsparadigma von RowGen ist datenbank- und plattformunabhängig und eignet sich daher ideal für die Anpassung und Automatisierung der Testdatengenerierung über Anwendungsfälle und Betriebssysteme hinweg sowie für das Ausschließen anderer Operationen wie Datenmaskierung. RowGen ist dennoch direkt kompatibel mit IRI FieldShield-Datenmaskierungsaufträgen – und IRI Voracity ETL-, Replikations- und Berichtsoperationen. Dies ist sehr praktisch, wenn Sie Testdaten von Grund auf in der gleichen Umgebung synthetisieren und mit ihnen arbeiten wollen. Sie verwenden alle die…
-
❌ Tableau BI-Tool ❌ 8x schnellere Datenaufbereitung für Business Intelligence mit Tableau Datenvisualisierung❗
Datenaufbereitung für Tableau: Schnelleres Bearbeiten, Maskieren und Verteilen von Daten! Tableau bietet eine Familie von interaktiven Datenvisualisierungstools für Business Intelligence. Nichts kann jedoch effektiv analysiert oder visualisiert werden, bis die Daten lokalisiert, erfasst, verfeinert, gruppiert, gesichert und anderweitig für die Visualisierung(en) vorbereitet wurden. Die IRI-Software bietet eine leistungsstarke, erschwingliche Datenmischung und -aufbereitung für Tableau in einer umfassenden Datenverwaltungsumgebung, die Datenerkennung (und -klassifizierung), Integration (ETL), Migration, Governance und Analytik unterstützt! Verwenden Sie die IRI CoSort-Software – oder die größere IRI Voracity-Plattform auf Basis von CoSort oder Hadoop – zum Extrahieren, Filtern, Transformieren und Schützen von Daten aus mehr als 150 verschiedenen Quellen. Insbesondere das Programm Sort Control Language (SortCL), das ursprünglich…
-
❌ Aussagekräftiges BI ❌ Data Warehouse und Data Lake überbrücken für optimierte und aufgabenkonsolidierte Datenmanipulation ❗
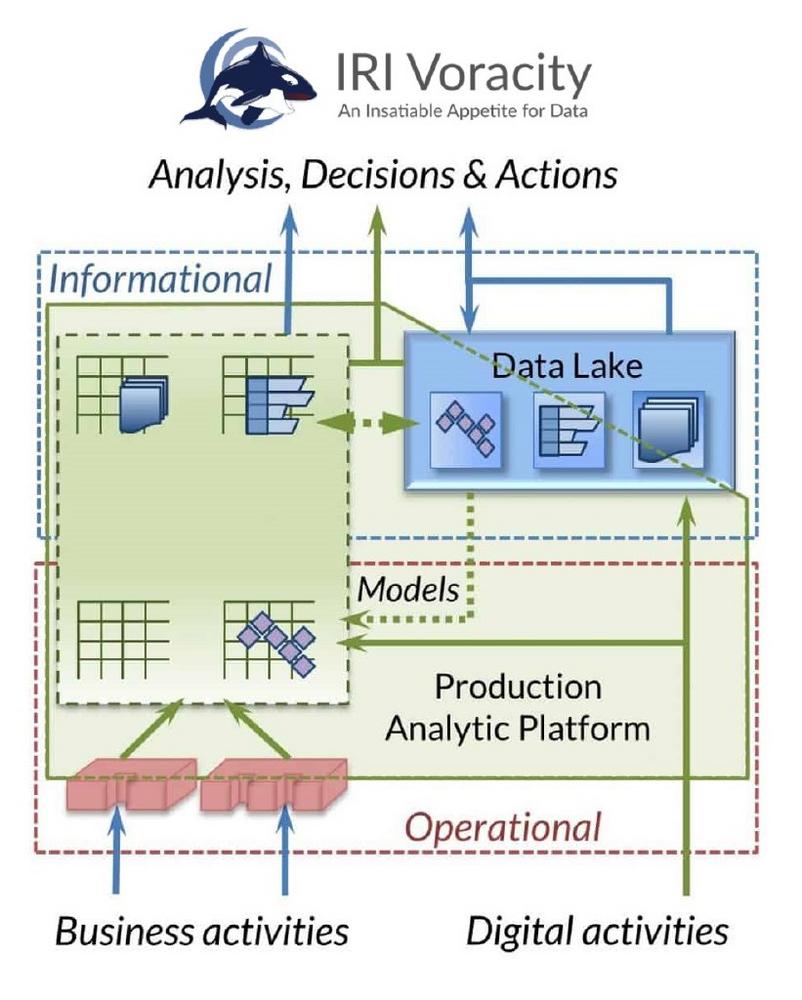
Gewinnen Sie Einblicke, während Sie große Datenmengen vorbereiten: Der Sinn der Datenerhebung besteht letztlich darin, Informationen und Erkenntnisse zu gewinnen. Und je besser die Informationsbilder Ihrer Daten sind, desto besser können Sie Entscheidungen treffen. Diese Entscheidungen heute zu treffen, bedeutet jedoch, 1) eine wachsende Menge und Vielfalt an Rohdaten schnell zu integrieren und 2) daraus durch aussagekräftige Berichte und Anzeigen, denen Sie vertrauen, analytische Erkenntnisse zu gewinnen. Wenn Sie sowohl schnell als auch kostengünstig handeln können, können Sie Wettbewerber übertreffen, die es nicht können. Die IRI Voracity Datenmanagement-Plattform ist der schnellste und kostengünstigste Ort, um die Aktivitäten der Big Data Integration und des Wrangling mit Sofortberichten oder analytischen Anwendungen von…
-
❌ Erweiterte Bildmaskierung ❌ Interne und externe Bildvorverarbeitung um sensible Daten in Bildern zu finden und per Datenmaskierung zu schützen❗
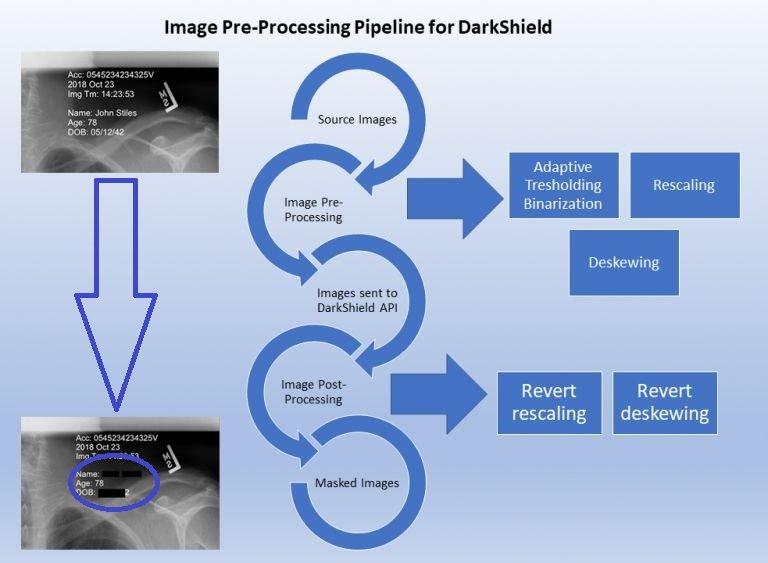
Vorverarbeitung von Bildern zur Verbesserung der OCR-Ergebnisse: OCR-Software (Optical Character Recognition) ist eine Technologie zur Erkennung von Text in einem digitalen Bild. OCR wird von der IRI DarkShield-Software verwendet, um Text in eigenständigen oder eingebetteten Bildern während der PII-Suche und -Maskierungsvorgänge zu erkennen. OCR hat jedoch ihre Grenzen: Um genaue Ergebnisse zu erzielen, muss das Bild vertikal ausgerichtet sein, die richtige Größe haben und so klar wie möglich sein. Nicht jedes Bild erfüllt diese Anforderungen! Wir müssen daher Methoden finden und anwenden, um diese Bilder durch Vorverarbeitung an unsere Bedürfnisse anzupassen. In diesem Artikel werden einige Vorverarbeitungsmethoden vorgestellt und erläutert, wie sie die Qualität der OCR-Ausgabe im Zusammenhang mit der…
-
❌ PII in Oracle DB ❌ Automatischer Datenschutz von sensiblen Daten in Oracle Database via Echtzeit Datenmaskierung❗
Echtzeit-Datenmaskierung mit Triggern: In früheren Artikeln wurde die statische Datenmaskierung neuer Datenbankdaten mit Hilfe der /INCLUDE-Logik oder der /QUERY-Syntax in geplanten IRI FieldShield-Job-Skripten beschrieben, die Änderungen der Spaltenwerte erforderten, um Aktualisierungen zu erkennen. Dieser Artikel beschreibt einen passiveren, aber integrierten Weg zum Auslösen von FieldShield-Maskierungsfunktionen auf der Basis von SQL-Ereignissen, d.h. zum Maskieren von Daten, wie sie in Echtzeit erzeugt werden. Er kann auch als "Prozedurenmodell" für andere Datenbanken und Betriebssysteme dienen. Dieser Artikel geht zunächst auf die Installation von FieldShield ein und nennt auch die dazu benötigten Anforderungen. Danach folgt ein anschaulicher Anwendungsfall mit PL/SQL-Triggern für die ASCII-Format bewahrende Verschlüsselung und die dazu gehörende entschlüsselte Ansicht. Allgemeiner gesagt können…
-
❌ TDM Tool ❌ Schnell intelligente, sichere und realistische Testdaten für DevOps, MLOps und DataOps bereitstellen❗
Intelligente, sichere Testdaten für DevOps, MLOps und DataOps! Daten, die durch Anwendungsentwicklung, maschinelles Lernen und Analysepipelines fließen, müssen mehrere Anforderungen erfüllen, die allen drei Bereichen gemeinsam sind, darunter: Realitätsnähe, um die Eigenschaften der Produktionsdaten und die Anforderungen der Anwendungstests widerzuspiegeln Konformität mit Geschäfts- und Datenschutzregeln sowie DB- und Analysemodellen Verfügbarkeit oder Sicherheit der Daten (je nach Sichtweise) Nachvollziehbarkeit für die Abstammung und Verantwortlichkeit Die an diesen Pipelines beteiligten Akteure verstehen diese Anforderungen aus ihrer eigenen Perspektive. IRI, auch bekannt als "The CoSort Company", bietet ein vielschichtiges Testdatenmanagement-Framework, um diese Anforderungen zu erfüllen. Die Rolle von IRI in diesem weiten Bereich begann mit der Notwendigkeit, umfangreiche, realistische Daten zu erstellen, um…
-
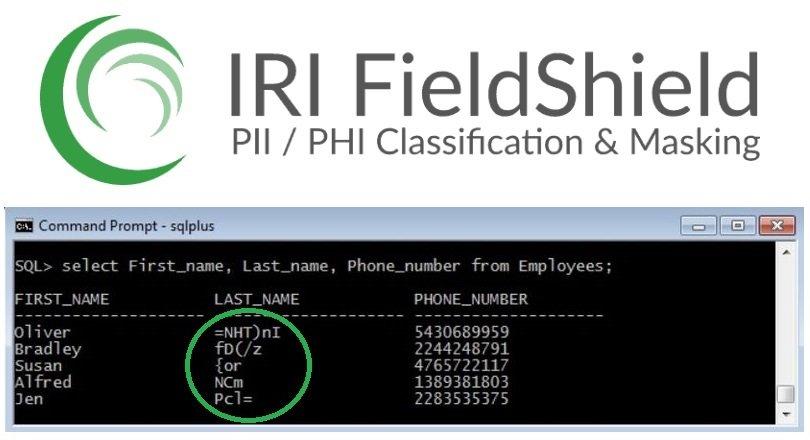
❌ Kritische PII + PHI-Daten ❌ Sensible personenbezogene Daten wie Gesundheitsdaten finden und HIPAA-konform schützen ❗
Müssen Sie geschützte Gesundheitsinformationen (PHI) oder andere persönlich identifizierbare Informationen (PII) bearbeiten oder verschleiern? Und können Sie dies auf eine Weise tun, die: sicher vor Hacking oder Bypass ist (Sammeln der Informationen aus anderen Daten)? die ursprünglichen Spalten- und Feldlayouts (Position, Größe Datentyp) beibehält? die anonymisierten Daten für Testzwecke real genug aussehen lässt? bequem, einfach, effizient und erschwinglich ist? die HIPAA Safe Harbour Regel erfüllen wird? Mit IRI FieldShield können Sie die Schlüsselidentifikatoren (und die Quasi-Identifikatoren) in Datenbankspalten und in Feldern in strukturierten und JSON-Dateien leicht klassifizieren, finden und entfernen oder auf andere Weise de-identifizieren. Mit IRI CellShield können Sie dasselbe in Excel 2010 und neueren Tabellenkalkulationen tun. Und mit…