-
❌ Sensible Daten schützen ❌ Lastausgleich & Authentifizierung von -Workloads für Datenmaskierung über NGINX❗
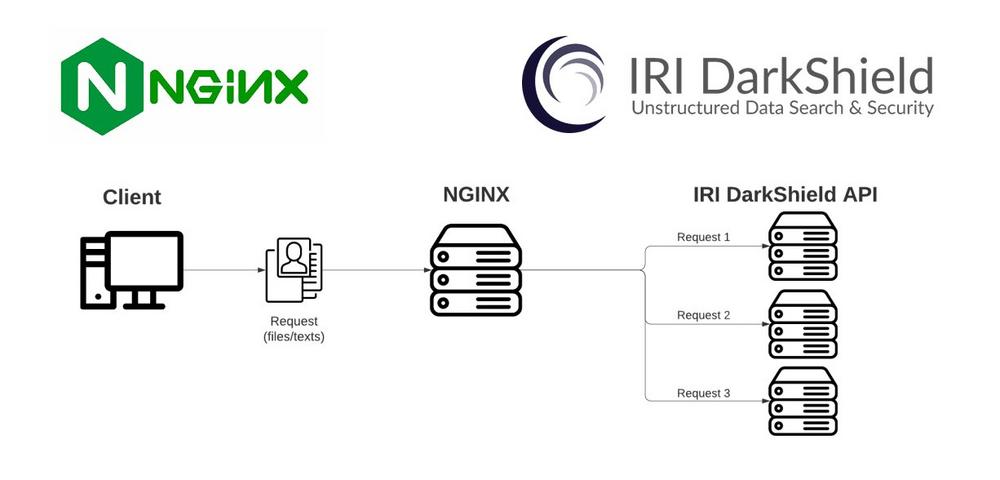
Lastausgleich & Authentifizierung von DarkShield über NGINX: Dieser Artikel demonstriert Methoden zum Ausgleich von Arbeitslasten und zur Authentifizierung von Nutzern der IRI DarkShield-API mithilfe der kostenlosen, einfach zu implementierenden Reverse-Proxy-Server-Software von NGINX. DarkShield ist ein kommerzielles Softwareprodukt von IRI zur Erkennung und Maskierung von Daten aus mehreren Quellen. Es findet und maskiert PII in Dateien, RDB- und NoSQL-DBs, Dokumenten und Bildern. Zusätzlich zur IRI Workbench GUI für DarkShield, die auf Eclipse aufbaut, bieten wir robuste und flexible RPC-APIs (Remote Procedure Call), die über einen Webdienst aufgerufen werden können. Dieser Artikel befasst sich mit letzterem. Die Kopplung von IRI DarkShield API und NGINX kann zu einer Verbesserung der Leistung führen und…
-
❌ PII in NoSQL finden + schützen ❌ Automatische Datenmaskierung in Couchbase, Redis und Solr Datenbanken❗
Datenschutz von NoSQL-Datenbanken: Sensible Daten finden und schützen! Dieser Artikel beschreibt die Verwendung der IRI DarkShield-Files API zum Auffinden und Maskieren von PII und anderen sensiblen Daten in Couchbase, Redis und Solr NoSQL-Datenbanken. In den beiden vorangegangenen Artikeln über die Maskierung von NoSQL-Datenbanken mit DarkShield wurden Cassandra, ElasticSearch, MongoDB sowie BigTable, CosmosDB und DynamoDB behandelt. IRI DarkShield ist ein Datenerkennungs- und Maskierungspaket zum Auffinden und De-Identifizieren sensibler Daten in halbstrukturierten und unstrukturierten Dateien und Datenbanken, einschließlich der NoSQL-Plattformen in diesem Artikel. DarkShield ist eines der drei zentralen Datenmaskierungsprodukte der IRI Data Protector Suite, die grafische Datenklassifizierungs-, Such- und Maskierungsjob-Designmodelle in der IRI Workbench IDE, die auf Eclipse basiert, nutzen. Um…
-
❌ Testdatenmanagement ❌ Sichere, realistische und referenziell korrekte Testdaten für Prototypen, DevOps, Benchmarks, etc.❗
Intelligente Testdaten erstellen und verwalten: Realistische Daten in realen Formaten! Brauchen Sie einen einfacheren Weg für: Erstellen von Test-DBs mit referentieller Integrität Simulation und Freigabe von Datei- und Berichtslayouts Entwicklung und Stresstest von Anwendungen Benchmarking neuer Hard- und Software Durchführung von Data Warehouse ETL-Tests mit Ihren Datenmodellen und Metadaten, aber nicht mit Produktionsdaten? Tabellenansichten, Indexreihenfolgen, Schlüsselbeziehungen sowie Datei- und Berichtsinhalte müssen die Realität widerspiegeln, um beim Testen nützlich zu sein. Das Erzeugen realistischer Werte und Formate mit sicheren Daten in idealen Bereichen – und das Befüllen großer Ziele – kann mit anderen Tools oder Programmen sehr lange dauern. Mit dem IRI RowGen-Produkt oder der IRI Voracity-Plattform können Sie mehrere Testdatenziele…
-
❌ PII in Cloud-Datenbank finden/schützen ❌ Automatische Datenmaskierung in Google Bigtable, Azure Cosmos DB und Amazon DynamoDB ❗
PII in Google BigTable, Azure Cosmos DB und Amazon DynamoDB finden und maskieren! Dieser Artikel behandelt die Verwendung der IRI DarkShield API zum automatischen Auffinden und De-Identifizieren von PII oder anderen sensiblen Daten in den drei großen NoSQL-Datenbanken der Cloud-Anbieter – Google Bigtable, MS CosmosDB in Azure und Amazon DynamoDB. Frühere Artikel in diesem Blog befassen sich damit, wie DarkShield-Assistenten in IRI Workbench Daten in anderen beliebten NoSQL-DBs finden und maskieren, darunter Cassandra, Elasticsearch und MongoDB. Ein weiterer Artikel behandelt CouchDB, Redis und Solr. Es gibt eine lange Liste von Endpunkt-Sicherheitspraktiken für NoSQL-DBs. Aber selbst damit gelingt es Angreifern immer noch, Löcher in diese Verteidigungsmaßnahmen zu schlagen. Unternehmen müssen daher…
-
❌ Datenmanagement-Plattform ❌ Kombination von Datenermittlung, Datenintegration, Datenmigration, Data Governance und Datenanalyse ❗
IRI Voracity mit neuem Data Vault Generator: Die Datenmanagement-Plattform Voracity von IRI wurde 2018 erstmals als DBTA Trend Setting Product ausgezeichnet. Voracity kombiniert Datenermittlung, Integration, Migration, Governance und Analysefunktionen, die sich durch Upgrades der Back-End-Datenverarbeitungs-Engine IRI CoSort 10.5 und der Front-End-IRI Workbench IDE auf Basis von Eclipse weiterentwickeln. Eine der neuesten Innovationen in Voracity ist ein Multioptions-Assistent zum Generieren, Profilieren, Migrieren zu und Prototypisieren von Data Vault-Modellen. Dan Linstedt erfand den Data Vault in den 1990er Jahren als eine modernere, agilere Methode, um skalierbare Data Warehouses zu entwerfen und zu erstellen und um Enterprise Analytics Services bereitzustellen. Der heutige Data Vault 2.0 (DV2) umfasst eine Referenzarchitektur, Entwicklungs- und Betriebsprozesse, agile…
-
❌ Datenschutz von PII in Bildern ❌ Vorverarbeitung von Bildern zur Verbesserung der OCR-Ergebnisse ❗
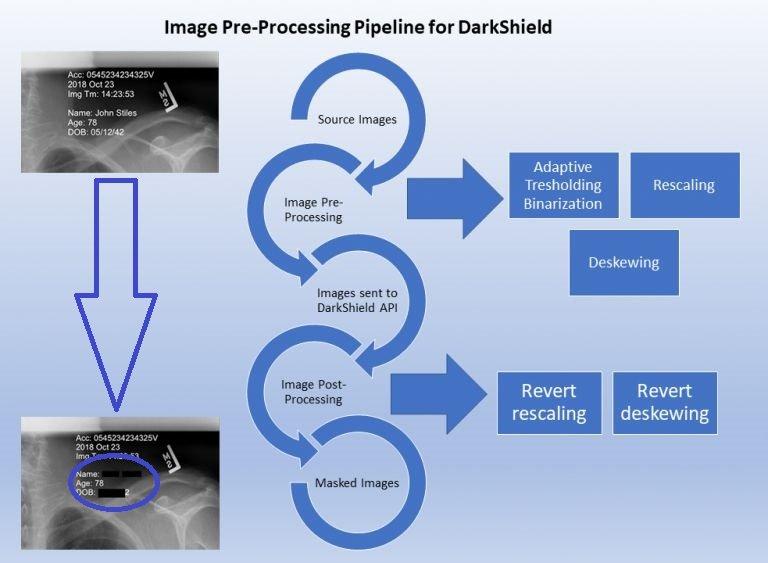
Vorverarbeitung von Bildern zur Verbesserung der OCR- und DarkShield-Ergebnisse: OCR-Software (Optical Character Recognition) ist eine Technologie zur Erkennung von Text in einem digitalen Bild. OCR wird von der IRI DarkShield-Software verwendet, um Text in eigenständigen oder eingebetteten Bildern während der PII-Suche und -Maskierungsvorgänge zu erkennen. OCR hat jedoch ihre Grenzen: Um genaue Ergebnisse zu erzielen, muss das Bild vertikal ausgerichtet sein, die richtige Größe haben und so klar wie möglich sein. Nicht jedes Bild erfüllt diese Anforderungen! Wir müssen daher Methoden finden und anwenden, um diese Bilder durch Vorverarbeitung an unsere Bedürfnisse anzupassen. In diesem Artikel werden einige Vorverarbeitungsmethoden vorgestellt und erläutert, wie sie die Qualität der OCR-Ausgabe im Zusammenhang…
-
❌ Dateiüberwachung ❌ Dynamisches Echtzeit Datenmanagement für Flat-Files ist jetzt möglich ❗
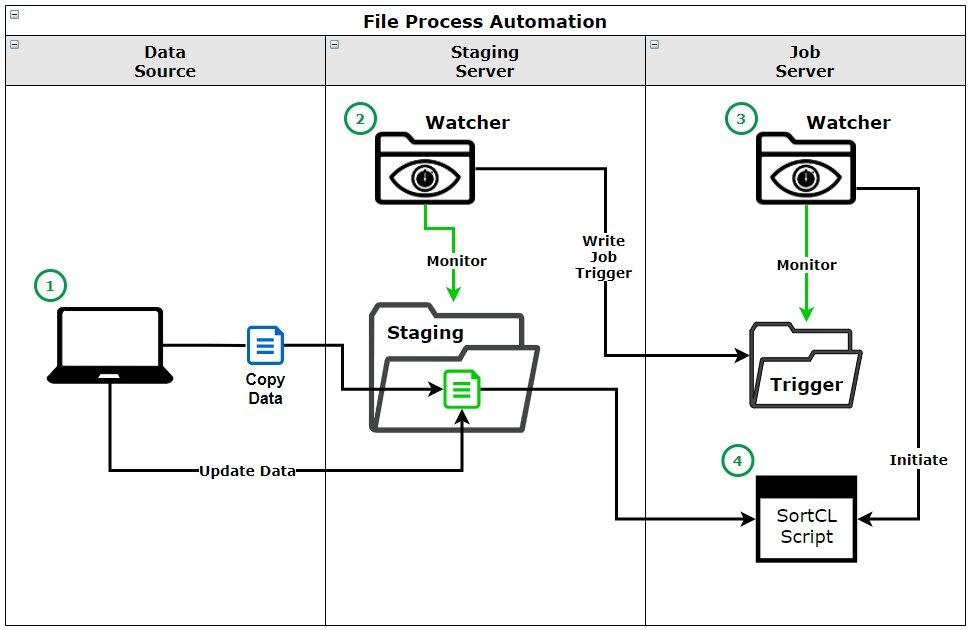
Automatisierung von Aufträgen durch Datei-Überwachung: Die manuelle Auslösung von SortCL-kompatiblen Jobs in IRI Voracity ETL-, CoSort Reporting-, FieldShield Maskierung- oder NextForm-Migrationsszenarien ist in Umgebungen, in denen Daten in Quellen dynamisch hinzugefügt oder geändert werden, nicht realistisch oder produktiv. Im Gegensatz dazu macht die Automatisierung von Aufträgen in Echtzeit manuelle Aufrufe überflüssig und stellt sicher, dass die richtigen Aufträge rechtzeitig ausgeführt werden. In diesem Beitrag zeigen wir ein Proof of Concept (POC), das automatisch ein vorhandenes SortCL-kompatibles Jobskript auf der Grundlage des Dateinamens ausführt, wenn eine neue Datei erstellt wird oder Daten in einer vorhandenen Datei hinzugefügt oder geändert werden. Anmerkung: Dieser Artikel ist technischer Natur und erfordert ein grundlegendes Verständnis…
-
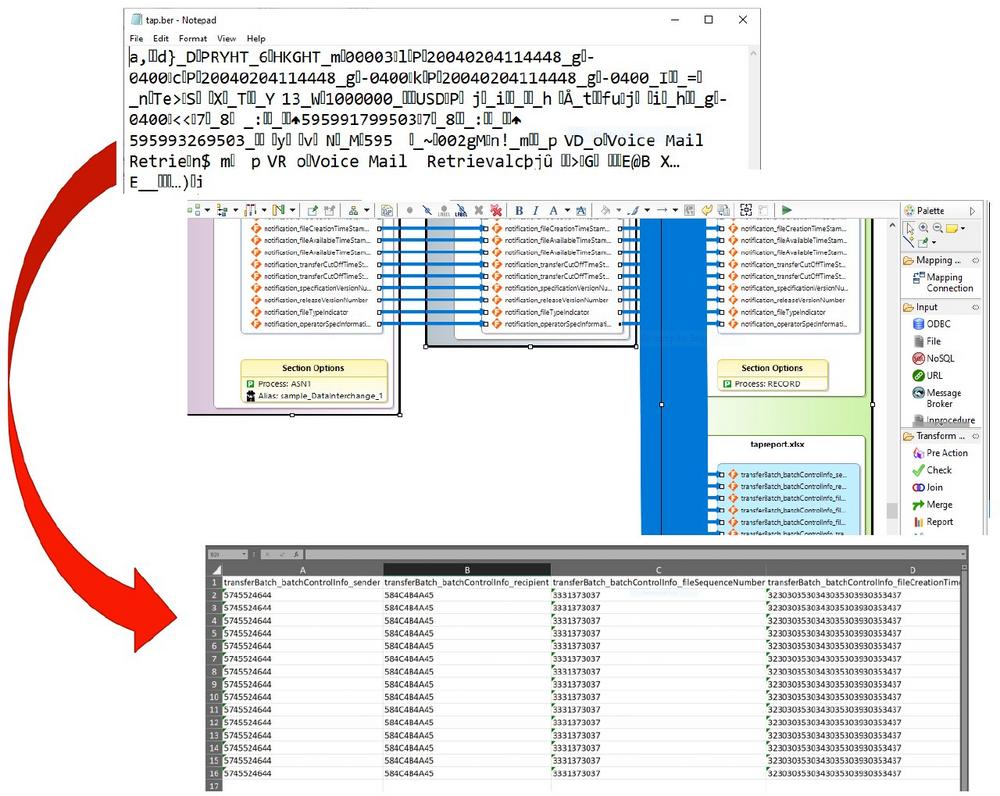
❌ Call Detail Record ❌ Tieferen Einblick in die CDRs erhalten und direkte Datenverarbeitung und Datenmaskierung von ASN.1 kodierten Dateien ❗
Direkte Unterstützung des ASN.1-Formats: Abstract Syntax Notation One (ASN.1) ist eine Sprache zur Beschreibung des Inhalts und der Kodierung von Nachrichtendaten, die zwischen Computern ausgetauscht werden (insbesondere in der Telekommunikationsindustrie). Dies ist der erste in einer Reihe von fünf Artikeln über das Dateiformat und das umfassende neue Data Engineering, das Sie mit ASN.1-Dateien unter Verwendung der IRI-Software durchführen können. Jede Datei wird durch eine ASN.1-Spezifikationsdatei (auch als Schema bezeichnet) beschrieben, die in der Regel die Erweiterung .asn hat. Diese für den Menschen lesbare Metadaten-Datei definiert jedes Feld in der Nachricht und wird automatisch in SortCL-kompatiblen Jobs in der IRI Voracity Datenmanagement-Plattform und ihren Komponentenprodukten (CoSort für Big Data Manipulation, NextForm…
-
❌ Datenverlust verhindern ❌ NoSQL-Datenbankcluster erfordert sowohl Endpunktsicherheit als auch Datenmaskierung ❗
Haben Sie Dark Data? Bis zu 90% der gesammelten oder generierten Unternehmens- und Regierungsdaten bleiben in unstrukturierten Text- und Bilddateien, Dokumenten und NoSQL-DBs oder anderen so genannten Dark Data Repositories verborgen. Um das rechtliche, finanzielle und Reputationsrisiko der Offenlegung von persönlich identifizierbaren Informationen (PII) in diesen oft obskuren Quellen zu mindern und um Datenschutzgesetze wie das GDPR einzuhalten, benötigen Sie eine Möglichkeit, die PII in diesen Quellen schnell zu lokalisieren und zu sichern. IRI DarkShield ist ein neues Produkt für die Erkennung, Bereitstellung, De-Identifizierung und Detaillierung von PII und anderen sensiblen Daten in unstrukturierten Dateien. Es stellt einen Durchbruch in den Bereichen unstrukturierte Datenmaskierungstechnologie, Geschwindigkeit, Benutzerfreundlichkeit und Erschwinglichkeit dar. IRI…
-
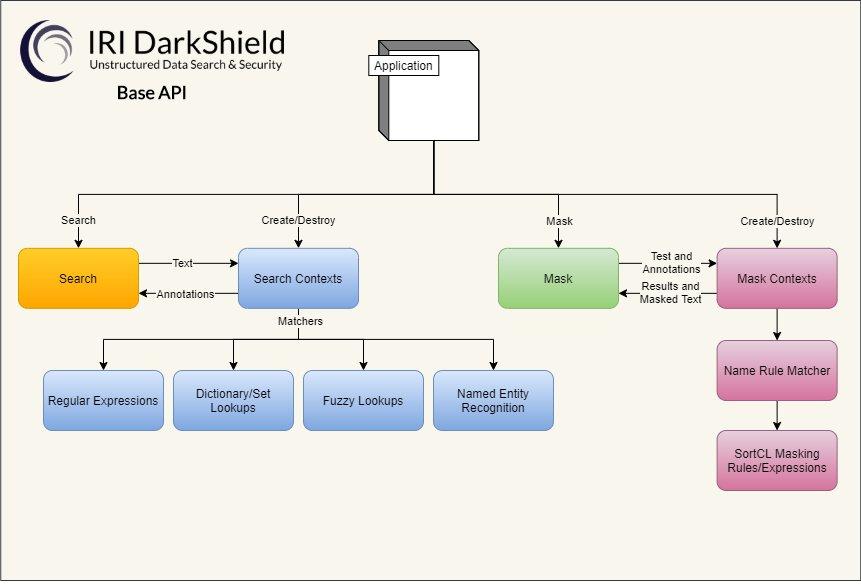
❌ PII in Dark Data ❌ Sensible Informationen auch in semi/un/strukturierten Quellen entdecken, bereitstellen und löschen ❗
. Dark Data: Versteckte PII überall finden und schützen! IRI DarkShield Version 4 verfügt über ein Remote Procedure Call (RPC) Application Programming Interface (API) für die Suche und Maskierung unstrukturierter Dateien. Die API ermöglicht die einfache Einbindung von DarkShield als Middleware in eine Pipeline außerhalb von IRI Workbench. Derzeit werden folgende Formate unterstützt: CSV/TSV Fixed Width HL7 X12 JSON MS Excel (.xls/.xlsx) MS Word (.doc/.docx) Parquet Klartext XML PDFs (mit eingebetteten Bildern) Bilder (png, .jpg/x/2, .tif/f, .gif, .bmp) DICOM Die API ist als Plugin auf der IRI Web Services Platform (Codename Plankton) aufgebaut, so dass der Benutzer selbst entscheiden kann, welche Dienste er benötigt, und dabei die gleichen Hosting-, Konfigurations-…