-
❌ Testdata für CICD ❌ Testdatenmanagement für sichere realistische Testdaten für Azure, GitLab + AWS DevOps-CodePipeline ❗
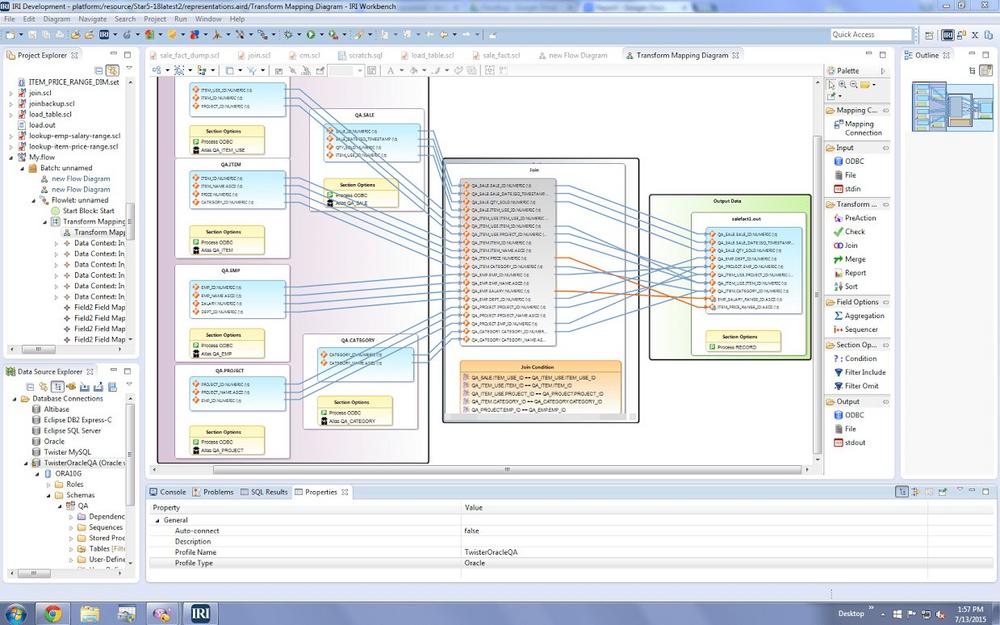
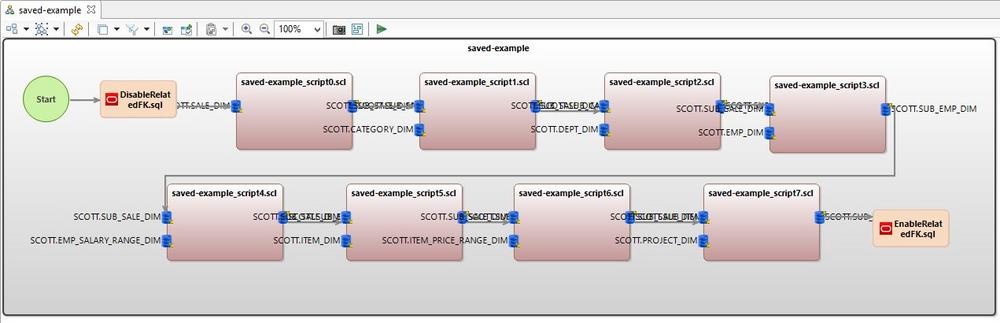
Was wird hier demonstriert? Dies ist die dritte Ergänzung zur DevOps-Pipeline-Serie, hier finden Sie die Links zu den DevOps-Artikeln zu GitLab und AWS CodePipeline. In diesem Artikel zeigen wir, wie man die IRI Voracity TDM-Plattformsoftware innerhalb einer Azure DevOps-Pipeline verwendet, um realistische Testdaten in verschiedenen Quellen für CI/CD-Zwecke zu erzeugen und zu verwenden. Konkret führen wir IRI RowGen-Skripte aus, um Testdaten in einer Excel-Tabelle zu synthetisieren, und die DarkShield-Files-API, um PII aus einer CosmosDB NoSQL-Datenbank zu maskieren. Wir bieten vier Methoden zur Erzeugung sicherer, intelligenter Testdaten in referenziell korrekten Datenbank-, Flat-File-, halbstrukturierten Datei-, formatierten Berichts- und sogar unstrukturierten Dateizielen: Maskierung von Produktionsdaten in IRI FieldShield, CellShield EE oder DarkShield RDBMS-Tabellen-Subsetting…
-
❌ Data Lake für Datenverarbeitung ❌ Unterschiedliche semi/un/strukturierte Rohdaten im Datenspeicher bündeln und in wenigen Schritten verarbeiten ❗
Big Data Verarbeitung: Laut der Open Knowledge Foundation ist die Datenpaketierung "eine einfache Möglichkeit, Sammlungen von Daten und deren Beschreibungen an einem Ort zu platzieren, so dass sie leicht ausgetauscht und verwendet werden können" und dass ein Datenpaket "in einem Format vorliegt, das sehr einfach, webfreundlich und erweiterbar ist". Für IRI und viele Menschen in der Welt der Datenverarbeitung und Datenwissenschaft ist die Datenverarbeitung eine Manifestation von Datenintegrations-, Staging- oder Wranglingoperationen, die über die Datentransformation und -filterung hinaus auch Aufgaben wie Konsolidierung, Bereinigung und Anonymisierung beinhalten können. IRI-Software verarbeitet seit Jahrzehnten große Datenmengen in brauchbare und sinnvoll formatierte Ergebnismengen, schnell, zuverlässig und kostengünstig. Berücksichtigen Sie die traditionelle Stärke von CoSort…
-
❌ Database Subsetting ❌ Automatisch erstellte Untermengen verwandter Tabellen für referenziell korrekte Testdaten für DB-Prototypen und DevOps ❗
Datenbank Subsetting: Sobald eine Datenbank eine bestimmte Größe überschreitet, wird es teuer – und aus der Sicherheitsperspektive riskant -, Kopien in voller Größe für Entwicklung, Tests und Schulungen bereitzustellen. Die meisten Teams benötigen kleinere Kopien der größeren Datenbank, und oft müssen die darin enthaltenen personenbezogenen Daten maskiert werden. Datenbank-Subsetting ist der Prozess der Erstellung einer kleineren, referenziell korrekten Kopie einer größeren Datenbank aus echten Tabellenauszügen. Teilmengen können zusammen mit oder anstelle der Maskierung von Daten oder der Synthese von Testdaten verwendet werden, um die mit vollständigen Mengen verbundenen Kosten und Risiken zu verringern. Die manuelle Erstellung aussagekräftiger Teilmengen ist komplex und mühsam, wenn man bedenkt, dass man kleinere Datenbanken mit…
-
❌ Schutz von PHI in EDI-Formaten ❌ Datenschutz via Datenmaskierung von sensiblen PHI in HL7- und X12-Formaten ❗
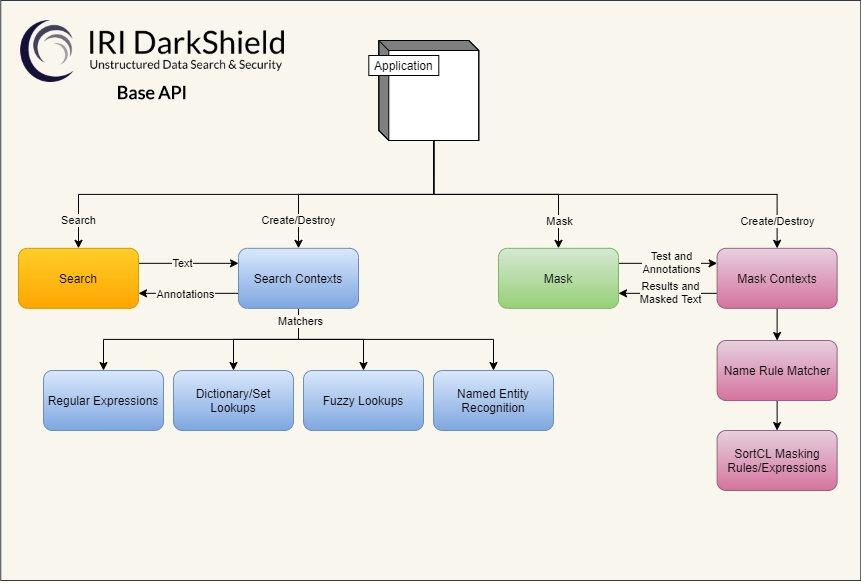
Auffinden und Maskieren von PHI in HL7- und X12-Dateien: Der Ruf von IRI in der Gesundheitsbranche hat sich seit der Veröffentlichung von IRI FieldShield im Jahr 2010 über seine traditionellen Wurzeln in der Verarbeitung von Leistungsansprüchen hinaus ausgeweitet. Mit FieldShield lassen sich geschützte Gesundheitsinformationen (Protected Health Information, PHI) in Flat-Files und relationalen Datenbanken gemäß den Sicherheitsvorschriften des HIPAA Safe Harbour und der Expert Determination Method finden und de-identifizieren. IRI hat das DarkShield-Produkt zur Datenmaskierung vor etwa 5 Jahren eingeführt, um diese Anforderungen in halb- und unstrukturierten Datenquellen, einschließlich XML-, Excel- und PDF-Dateien, sowie NoSQL-DBs wie Mongo und Bildformaten wie JPEG und DICOM zu erfüllen. Dieser Artikel befasst sich mit der…
-
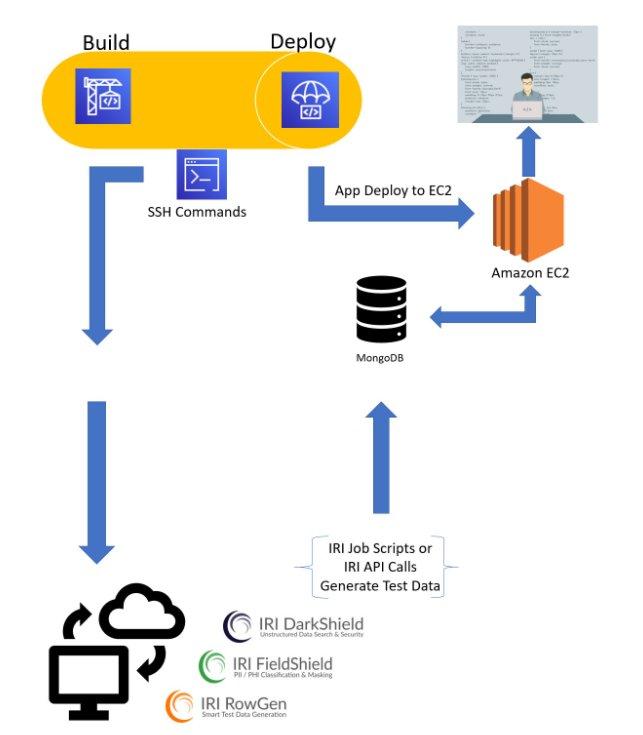
❌ Testdaten in AWS CodePipeline ❌ Erzeugung von synthetischen Testdaten innerhalb der AWS CodePipeline automatisieren ❗
Maskierte Testdaten in einer AWS CodePipeline: In diesem Artikel wird gezeigt, wie die Ausführung von IRI DarkShield-Datenmaskierungsaufträgen aus SSH-Befehlen automatisiert werden kann, die innerhalb der AWS CodePipeline ausgeführt werden, um zweckmäßige Testdaten im DevOps-Prozess zu erzeugen. In unserer letzten Demonstration mit der GitLab-Pipeline haben wir strukturierte IRI FieldShield-Datenmaskierungs- und IRI RowGen-Datensynthese-Auftragsskripte ausgeführt, um Testdaten zu erzeugen und sie nach der Bereitstellung in API-Tests zu verwenden. In dieser Demonstration ruft die AWS CodePipeline die DarkShield-Files-API auf einem Remote-Server auf, um eine weitere Methode zur Erstellung von zweckmäßigen Testdaten in MongoDB zu zeigen. Natürlich ist die GitLab-Methode mit FieldShield und RowGen auch in AWS und Azure DevOps praktikabel. Zusammenfassung des Verfahrens: In…
-
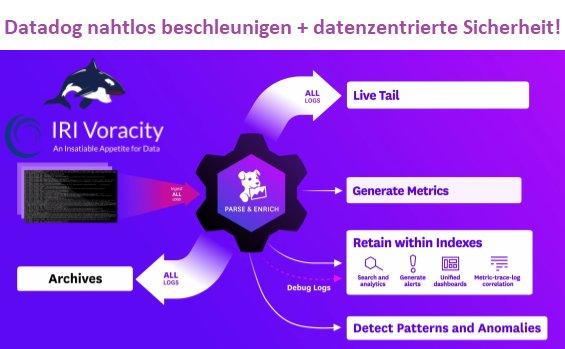
❌ Datenaufbereitung für Datadog ❌ Externes Data Wrangling für Beschleunigung und Einspeisung mit Datensicherheit in Datadog ❗
Was ist Datadog? Datadog ist eine Web-Anwendung zur Überwachung von Datenfeeds, zur Analyse von Trends, zur Erstellung analytischer Dashboard-Anzeigen und zum Senden von Warnmeldungen. Dieser Artikel ist der erste in einer 4-teiligen Serie über die Fütterung der Datadog Cloud-Analyseplattform mit verschiedenen Arten von Daten aus IRI Voracity-Operationen. Er konzentriert sich auf den Wert von Datadog und Voracity zusammen. Die folgenden Artikel befassen sich mit der Aufbereitung von Daten in Voracity und ihrer Einspeisung in Datadog, der Verwendung von Voracity-verarbeiteten Daten in Datadog-Visualisierungen und der Verwendung von IRI DarkShield-Suchergebnissen in Datadog zur Verbesserung der Datensicherheit: Dieser Artikel beschreibt die Einspeisung verschiedener Daten aus IRI Voracity in die Datadog Cloud-Analyseplattform. Er konzentriert…
-
❌ Datenschutz in der Cloud ❌ Datenmaskierung von PII in Dateispeicher wie S3, Azure BLOB und Google Cloud Platform (GCP) ❗
Die Beliebtheit von Cloud-Speichern: In dem Maße, wie immer mehr Datenverarbeitung in die Cloud verlagert wird, nimmt auch die Speicherung zu. Das ist nur logisch, denn Cloud-Systeme benötigen die Nähe zu den Daten, um leistungsfähig zu sein, so wie auch die Daten auf den Rechnern vor Ort für eine schnellere Verarbeitung auf oder in der Nähe gespeichert sein sollten. Die Datenspeicherung in der Cloud ist auch deshalb so beliebt, weil die Anschaffung und Wartung von Speichergeräten vor Ort Kopfzerbrechen bereitet. Cloud-Anbieter ermöglichen es Unternehmen jeder Größe, Daten außerhalb des Unternehmens zu speichern, unabhängig davon, ob diese Daten mit anderen Cloud-Diensten oder -Anwendungen verbunden sind oder nicht. Verschlüsselung von Cloud-Speicher: Die…
-
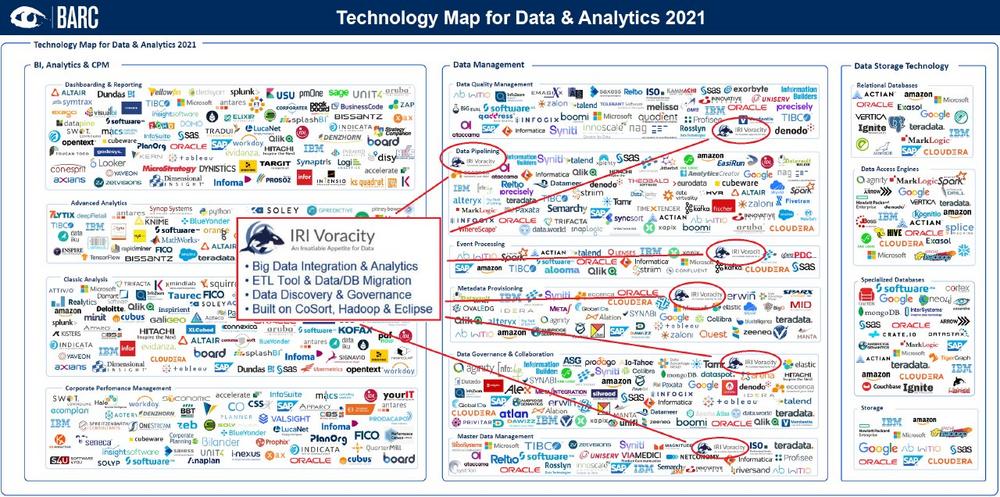
❌ CDI und eCommerce ❌ Datenintegration, mit Datenaufbereitung und Datenverarbeitung von großen Mengen an kaufrelevanten Referenzdaten ❗
Unsere Kunden in diesem Segment können die IRI Voracity ETL-Plattform oder die jahrzehntelang bewährte IRI CoSort Engine nutzen, um große Mengen an kaufrelevanten Referenzdaten zu integrieren, aufzubereiten und zu verarbeiten: Verkaufs- und Buchungssätze Verbraucher- und demographische Umfragen Finanzdaten, einschließlich Preisindizes, Immobilienmärkte und Versicherungsrisiken Marketing- und Verschreibungsdatenbanken Katalog- und Prämienprogramm-Abonnements Weblogs (Clickstream-Analysen) Identifizieren, bereinigen und helfen, über das Kaufverhalten zu berichten. Führen Sie die Integration von Kundendaten und die Erfassung von Änderungsdaten in hochvolumigen Data Warehouses und E-Commerce-Daten-Webhouses, operativen Data Stores, Data Lakes und Flat Files durch. Verwenden Sie Ihr bevorzugtes BI- oder Analysetool oder nutzen Sie kompatible Analyse- und maschinelle Lernwerkzeuge wie KNIME, um das Verhalten vorherzusagen. Wenn Sie sich…
-
❌ Datenintegrität ❌ PII-Klassifizierung vor der Erkennung und Zuweisung von Datenmaskierung-Regeln zu diesen Klassen ❗
Datenklassifizierung: Benutzer von PII-Maskierungswerkzeugen wie FieldShield für strukturierte Flat-Files, DarkShield für semi/unstrukturtierte Datenquellen und CellShield für gezielte Datenmaskierung in Microsoft Excel®-Tabellen können ihre Daten katalogisieren und durchsuchen – und Datentransformations- und Schutzfunktionen als Regeln anwenden – unter Verwendung der integrierten Datenklassifizierungsinfrastruktur in ihrer gemeinsamen Front-End-IDE, IRI Workbench, die auf Eclipse™ aufbaut. Die Multi-Source-Datenerkennungsfunktionen (Suchfunktionen) in IRI Workbench können die von Ihnen definierten Datenklassen nutzen oder Ihnen dabei helfen, Ihren Daten auf der Grundlage Ihrer Suchergebnisse, Geschäftsregeln und/oder Domänenontologien Datenklassen oder Datenklassengruppen zuzuordnen. Sie können Ihre Datenklassenbibliothek in wiederverwendbaren Feldregeln (z. B. Datenmaskierung) verwenden. Und Sie können diese Regeln auch bei der automatischen Klassifizierung von Daten zuweisen. Diese Funktionen bieten Datenarchitekten…
-
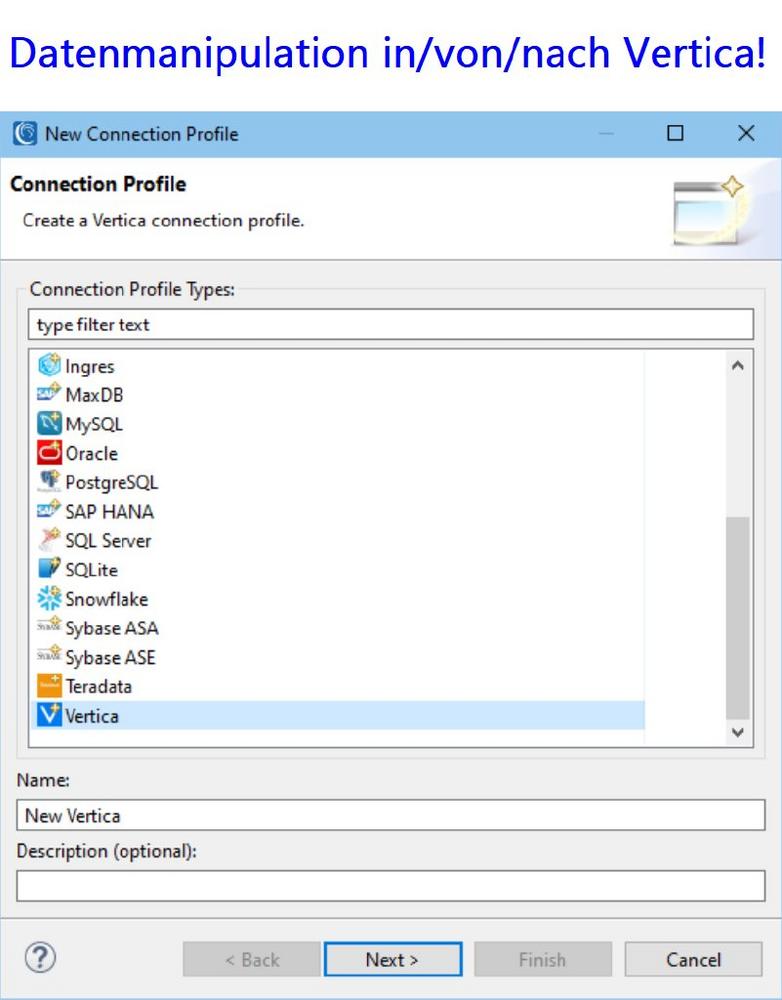
❌ Vertica Datenbank ❌ Große Datenverschiebung und Datenmanipulation mit Datenschutz von/in/nach Vertica Database ❗
End-to-End Datenmanagement: Wie andere Artikel in unserem Blog über die Verbindung und Konfiguration von relationalen Datenbanken mit der IRI Voracity Datenmanagement-Plattform beschreibt dieser Artikel detailliert, wie man Vertica-Quellen erreicht. Die IRI Voracity Datenmanagement-Plattform besteht aus ihren Ökosystemprodukten: CoSort für schnellste Big Data Manipulationseit 1978 NextForm zur Datenmigration und -formatierung FieldShield zur Datenmaskierung von PII in semi/strukturierten Quellen DarkShield zur Datenmaskierung von PII in semi/unstrukturierten Quellen RowGen zur synthetischen Testdatengenerierung Dieser Artikel beschreibt detailliert, wie man Vertica-Quellen erreicht. Er beschreibt die ODBC- und JDBC-Verbindungen und Konfigurationen, die erforderlich sind, um Vertica mit der SortCL-Engine und dem IRI Workbench Job Design Client zu registrieren, die den meisten IRI-Softwareprodukten, die strukturierte Datenquellen verarbeiten,…