-
❌ Data Masking von Apache Parquet ❌ Personenbezogene PII oder andere sensible Daten in Parquet-Dateien finden und sicher maskieren ❗
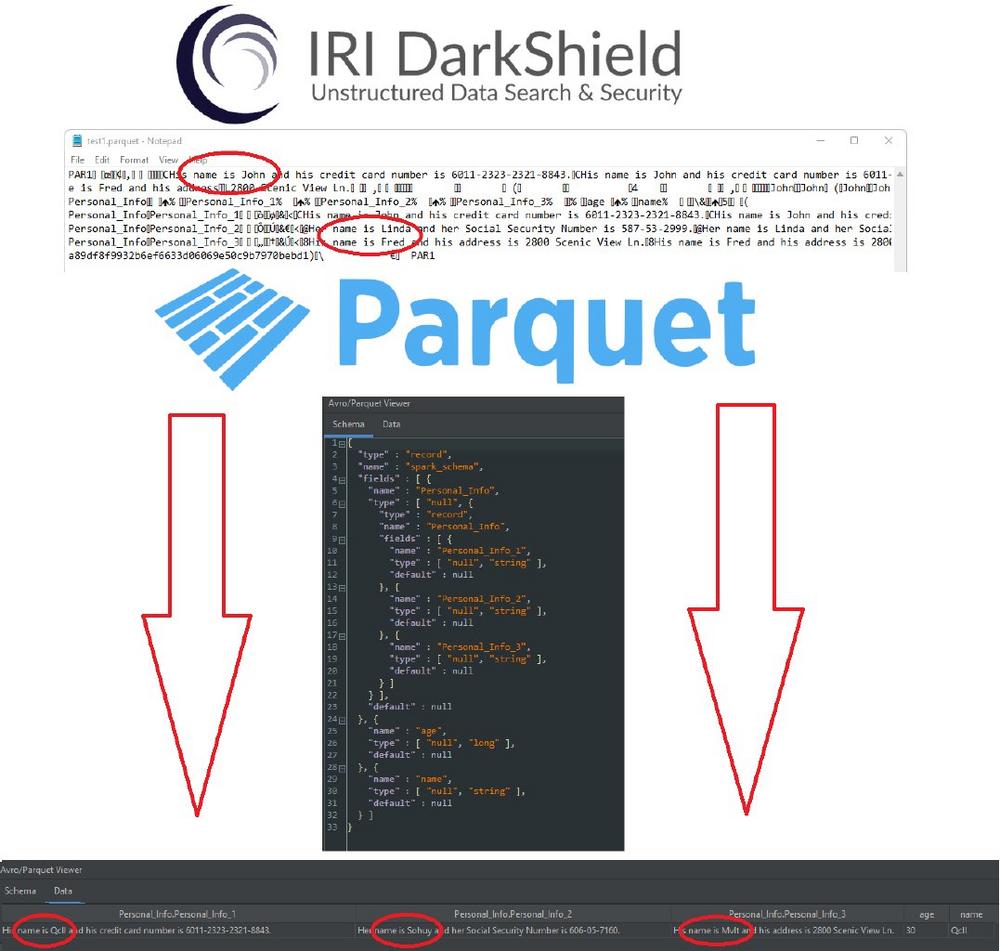
Parquet-Dateiformat: Sensible Informationen suchen und schützen! Apache Parquet ist ein spaltenförmiges, komprimiertes Dateiformat, das auf Leistung optimiert ist. Parquet-Dateien sind häufig bei Cloud-Speicheranbietern zu finden, da die Optimierungen des Dateiformats die Kosten in Cloud-Umgebungen im Vergleich zu CSV-Dateien senken. Parquet ist ein komplexes Binärformat, das zwar für schnelle analytische Abfragen und geringen Speicherplatzbedarf ausgelegt ist, aber nicht leicht lesbar ist, was den Schutz sensibler Daten erschweren kann. Die DarkShield Files API bietet jedoch die Möglichkeit, Parquet-Dateien nach sensiblen Daten zu durchsuchen und zu maskieren. Das Parquet-Dateiformat lässt viele Datentypen und verschachtelte Datenstrukturen zu; die DarkShield Files API ist in der Lage, gängige primitive Typen wie Strings, Integer, Bytes usw. sowie…
-
❌ Datenintegration und Datenmanagement ❌ DBTA listet wichtigste Funktionen für Data Management und sicherer Datenmaskierung für moderne Unternehmen ❗
Datenintegration und Datamanagement für moderne Unternehmen: Erkenntnisse und Ratschläge! In der DBTA-Ausgabe 2018 zum Thema Datenintegration und -governance haben wir einen MDM-bezogenen Anwendungsfall in Malaysia (das MyGDX-Portal) vorgestellt, bei dem die Datentransformations- und Datenqualitätsfunktionen des CoSort "SortCL"-Programms genutzt werden, das die Datenmanagement-Plattform von IRI Voracity betreibt. Was wir heute häufiger sehen, ist die Kombination dieser Aktivitäten mit Datenmaskierung. Dies spiegelt die Anforderungen an die Sicherheit von personenbezogenen Daten, die Einhaltung von Datenschutzgesetzen und die Verwaltung von Testdaten in Big Data"-Warehousing- und BI/Analysekontexten wider. Voracity ist das übergreifende Softwareprodukt von IRI, das den Höhepunkt von mehr als 40 Jahren Erfahrung in der Datenmanipulation und -bewegung darstellt, beginnend mit CoSort. Die Entwicklung…
-
❌ XLS & XLSX ❌ Microsoft Excel Datenintegration, mit Datenmaskierung, Neuzuordnung und Datenbereinigung, für Reporting oder Testdaten erstellen ❗
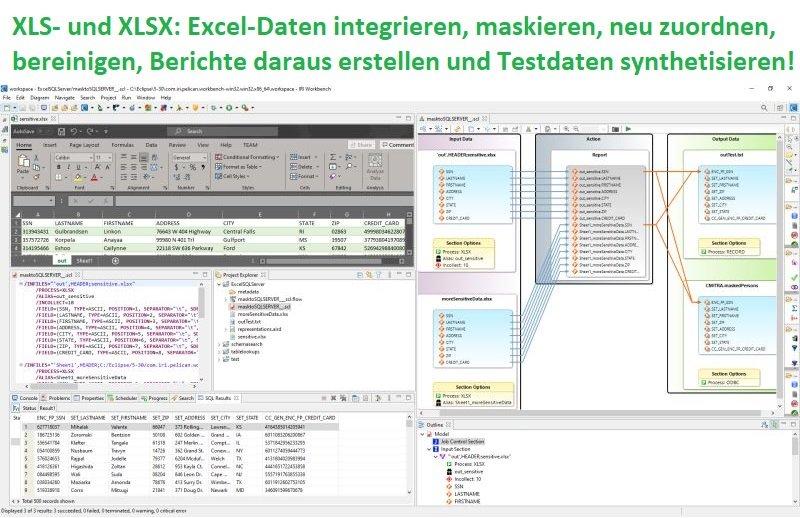
Verarbeitung von Tabellenkalkulationsdaten: Zusätzlich zu allen anderen strukturierten Datenquellen, die die IRI-Software bereits unterstützt, ist es jetzt möglich, Daten aus XLS- und XLSX-Dateien im SortCL-Programm zu lesen und zu verarbeiten! IRI CoSort, für schnelles Sortieren, Umwandeln und Berichten IRI NextForm, für Mapping, Migration und Replikation IRI RowGen, für die zufällige Auswahl oder Generierung von realistischen Testdaten IRI FieldShield, für die Maskierung sensibler Daten IRI Voracity, für alle oben genannten Funktionen sowie für ETL, Datenbereinigung und -aufbereitung für Analysezwecke und zum Zurückschreiben der resultierenden Daten in diese oder andere Ziele, einschließlich eines oder mehrerer Blätter. Dieser Artikel gibt einen Überblick über die Operationen und die Syntax des SortCL-Programms, das mit IRI…
-
❌ DB-Cloning mit Datenmaskierung ❌ Oracle Datenbank via Commvault klonen + direkt mit Plug-In sensible Daten maskieren ❗
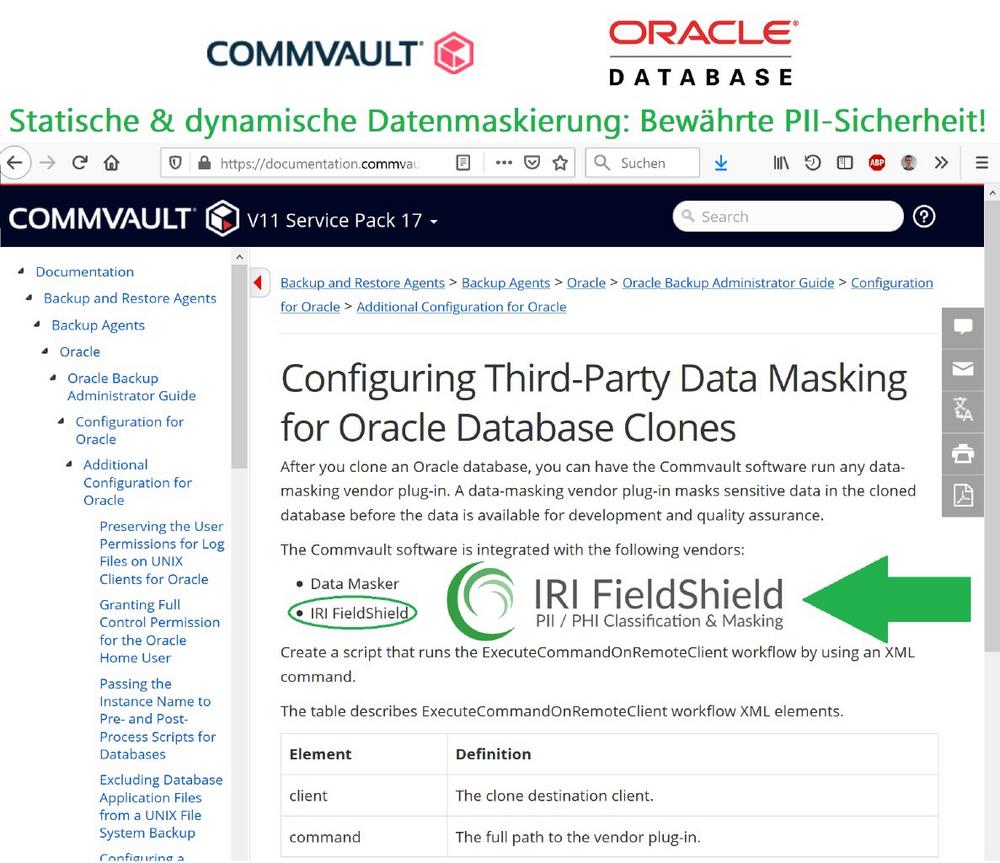
Sicheres Database-Cloning mit umfangreicher Datenmaskierung! Das Sicherheitsprodukt IRI FieldShield maskiert sensible Daten in der geklonten Datenbank, bevor dann die Daten für die Entwicklung und Qualitätssicherung zur Verfügung stehen! Nachdem Sie eine Oracle-Datenbank geklont haben, können Sie die Commvault-Software mit unserer Datenmaskierung via Plug-In ausführen lassen. Die Commvault-Software ist bei unserem IRI FieldShield integriert. Die Anleitung finden Sie direkt bei Commvault V11 Service Pack 17 unter: "Configuring Third-Party Data Masking for Oracle Database Clones" Was ist FieldShield? IRI FieldShield® ist eine leistungsstarke und kostengünstige Software zur Datenerkennung und –maskierung von PII in strukturierten und semistrukturierten Quellen, groß und klein. Die FieldShield-Dienstprogramme in Eclipse dienen zur Profilierung und De-Identifizierung von Daten im…
-
❌ Data Preparation ❌ Datenaufbereitung für Business Intelligence, wie Data Franchising, Data Blending, Data Wrangling, oder Data Munging ❗
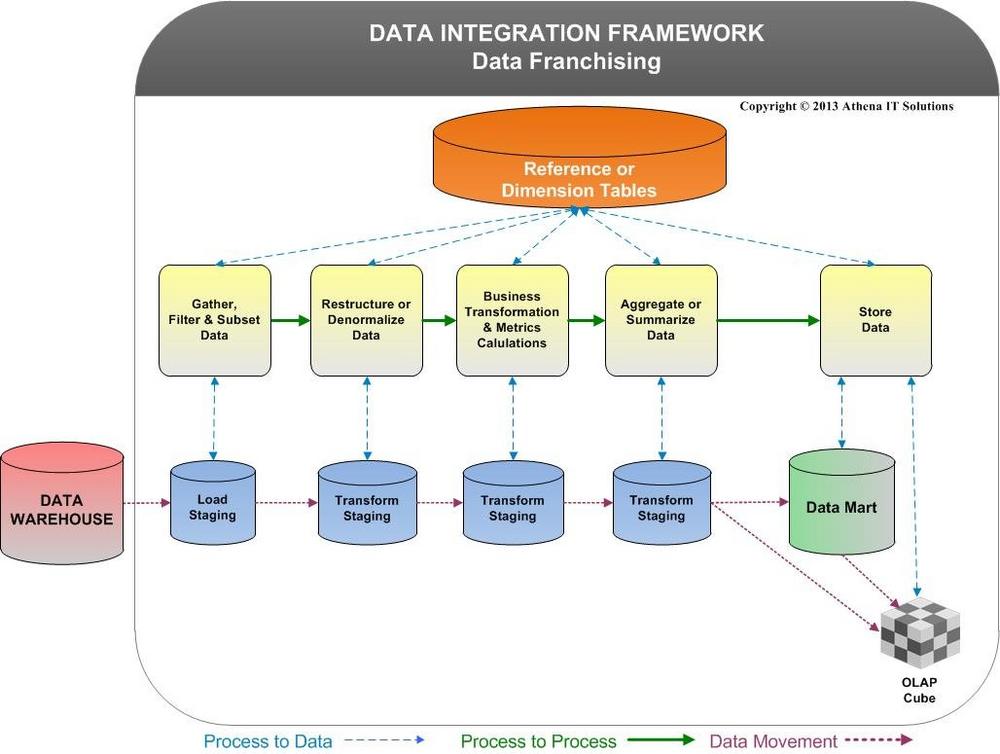
Was ist Data Franchising? Data Franchising ist ein 2003 von Richard Sherman von Athena Solutions geprägter Begriff, der sich auf die Aufbereitung oder Verpackung großer Datensätze in saubere, nutzbare Teile für die Entscheidungsfindung bezieht, insbesondere durch Business Intelligence (BI) und Analysesoftware. Zu den neueren Begriffen für die Aufbereitung von Daten für diese Zwecke gehören Data Blending, Data Munging und Data Wrangling. Um die Benutzerfreundlichkeit und Leistung von BI- und Analysetools zu verbessern, bereitet das IRI-Datenmanipulationsprogramm (SortCL) – das die Standard-Engine im IRI CoSort-Produkt und in der IRI Voracity-Plattform ist – CSV- und XML-"Feed"-Dateien oder ODBC-Tabellen schnell auf. Der Hauptvorteil dieser externen Datenaufbereitung liegt in der Effizienz; der Aufwand für die…
-
❌ Test Data für DevOps ❌ Erstellung von synthetischen, sicheren und intelligenten Testdaten in einer CI/CD-Pipeline für DevOps❗
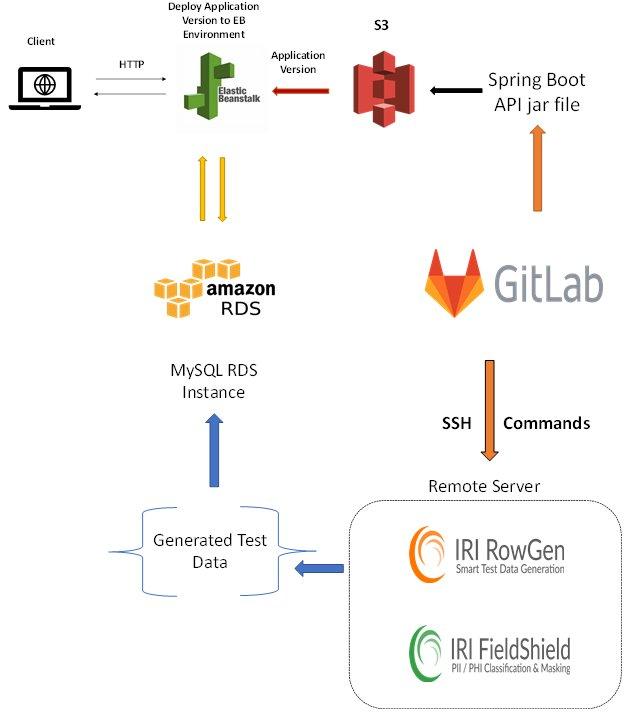
Erstellung von Testdaten in einer CI/CD-Pipeline: Die Grundlage der DevOps-Automatisierung besteht darin, zu automatisieren, wo und wann man kann. Die Möglichkeit, IRI-Jobskriptausführungen, die Testdaten maskieren oder synthetisieren, in der CI/CD-Pipeline zu verarbeiten, unterstützt dieses Bestreben. Dieser Artikel veranschaulicht ein End-to-End-Beispiel für eine erfolgreiche Integration! In diesem Artikel wurde gezeigt, wie die Ausführung von IRI-Aufträgen zur Erzeugung von Testdaten innerhalb einer GitLab CI/CD-Pipeline automatisiert werden kann. Mit SSH können alle IRI-Auftragsskripte, die über die Befehlszeile ausgeführt werden können, von der Pipeline aus ausgeführt werden. IRI RowGen-Aufträge synthetisieren Testdaten, während echte Daten von unsicheren Umgebungen ferngehalten werden. Alternativ dazu finden und maskieren IRI FieldShield-Auftragsskripte sensible Daten auf Feldebene, so dass viele echte…
-
❌ IBM DataStage ❌ Unkompliziert 10x schnellere Datenmanipulation für ETL-Tool InfoSphere DataStage ❗
Herausforderungen: Auch nach der Beratung und dem Tuning können große Datenmengen (d.h. mehr als eine Million Zeilen) nur langsam transformiert werden, insbesondere ohne ein teures Hardware- oder Versions-Upgrade von DataStage. Große Datenengpässe sind große Sortierungen, Joins, Aggregationen, Ladungen und manchmal auch Entladungen. Die Parallelisierung oder Optimierung in anderen Ebenen oder Tools kann unhandlich, wenn nicht sogar teuer sein und die Leistung für andere Benutzer beeinträchtigen. Aus Sicherheitssicht können die Datenmaskierungslösungen von IBM für einige teuer oder umständlich sein oder nicht alle Funktionen der PII-Erkennung oder des Datenschutzes für andere bereitstellen. DataStage-Transformationen beschleunigen: Beschleunigen Sie das Sortieren, Aggregieren und Zusammenführen in einem einzigen Durchgang mit der CoSort Sort Control Language (SortCL)…
-
❌ PII-Schutz in Dark Data ❌ RPC API für die Suche und Maskierung von personenbezogenen Daten in unstrukturierten Dateien ❗
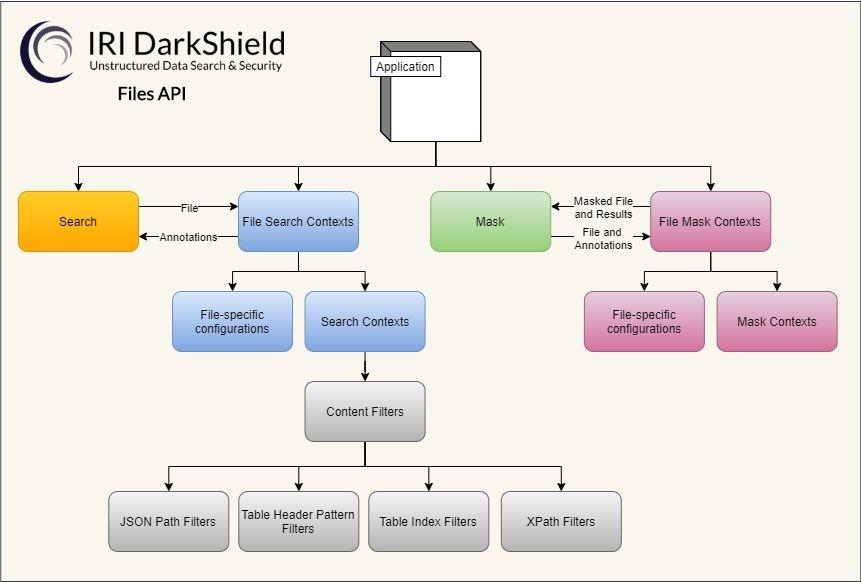
IRI DarkShield Version 4 verfügt über ein Remote Procedure Call (RPC) Application Programming Interface (API) für die Suche und Maskierung von unstrukturierten Dateien. Mit der API kann DarkShield einfach als Middleware in eine Pipeline außerhalb von IRI Workbench eingebettet werden. Derzeit werden folgende Formate unterstützt: Einfacher Text, CSV/TSV, JSON, XML, PDFs (mit eingebetteten Bildern) und Bilder (png, .jpg/x/2, .tif/f, .gif, .bmp). Die Unterstützung für Microsoft-Dokumente (Word, Excel und Powerpoint) wird ebenfalls in kommenden kleineren Updates der API veröffentlicht. Die API ist als Plugin auf der IRI Web Services Platform (Codename Plankton) aufgebaut, so dass der Benutzer auswählen kann, welche Dienste er benötigt, während er die gleichen Hosting-, Konfigurations- und Protokollierungsfunktionen…
-
❌ Snowflake Datenbank ❌ Datenintegration, Datenbereinigung und Datenmaskierung + direkte Bereitstellung in Zieltabellen für Datenanalyse ❗
Snowflake ETL und PII-Maskierung: Schnelles, kostengünstiges Datenmapping & Verwaltung! Möglicherweise sind Sie mit diesen zeitaufwendigen Problemen bei der Arbeit mit Snowflake konfrontiert: Datensuche, -profilierung und/oder -klassifizierung Integration oder Daten-Wrangling für DW/BI-Ops Datenbewegung/Migration zu/von Tabellen Transformieren oder Laden großer Tabellen Datenerfassung oder -replikation ändern Clustering oder Abfrage der Performance Generierung intelligenter und sicherer Testdaten Maskierung sensibler Daten Auch spezifische Leistungsdiagnosen und -abstimmungen brauchen Zeit und können andere Benutzer betreffen. Schließlich können gespeicherte SQL-Prozeduren auch ineffizient programmiert werden und erfordern eine Optimierung und dauern dann immer noch zu lange! Daten in Ordnung halten: IRI CoSort für die Vorsotierung von Flat-Files für Bulk-Ladungen und Inserts. Das entfernt den Overhead dieser Arbeit von Snowflake,…
-
❌ Vom Data Lake, Data Mart zum Data Warehouse ❌ Moderner und gemischter Ansatz zwischen Datenintegration und Datenvirtualisierung ❗
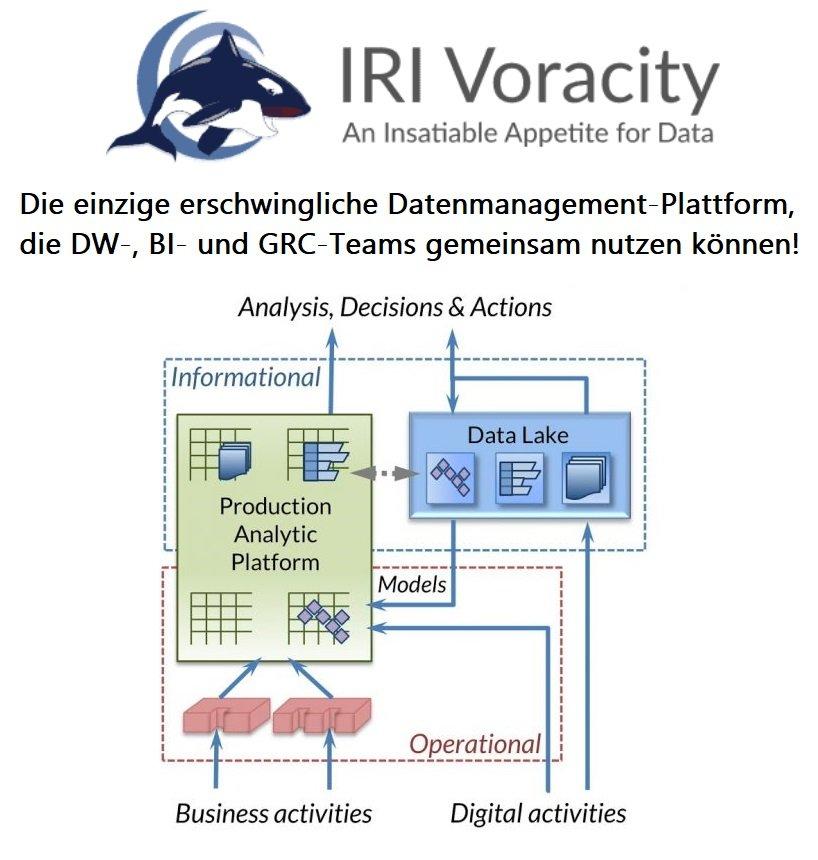
Prozess mit Informationen auf Augenhöhe: Dies ist der erste einer vierteiligen Serie von Blogartikeln, die die inhärenten Kompromisse zwischen Datenverarbeitung und Informationsspeicherung und -präsentation innerhalb traditioneller ETL-Paradigmen untersucht – vom ODS bis zum Data Lake. Er erklärt die Notwendigkeit eines moderneren, gemischten Ansatzes zwischen Datenintegration und Virtualisierung, genannt Production Analytic Platform, und die Vorteile der Implementierung mit der IRI Voracity-Technologie. Die Artikel wurden von Dr. Barry Devlin von 9sight Consulting geschrieben, einer führenden Autorität im Bereich Data Warehousing seit 1988 und Autor von "Business unIntelligence: Insight and Innovation beyond Analytics and Big Data". Ein Podcast und ein Video, die diese Konzepte unterstützen, finden Sie hier. In dieser kurzen Serie von…