-
❌ CDI und CDP ❌ Riesige Datenmengen via Data Wrangling bewältigen, um einkaufsbezogene Referenzdaten zu erhalten ❗
Lösungen zur Umsatzoptimierung: Schnellere Datentransformation bedeutet schnellere Entscheidungen! Unsere Kunden önnen die IRI Voracity ETL-Plattform oder die jahrzehntelang bewährte IRI CoSort Engine nutzen, um große Mengen an kaufrelevanten Referenzdaten zu iintegrieren, aufzubereiten und zu verarbeiten: Verkaufs- und Buchungssätze Verbraucher- und demographische Umfragen Finanzdaten, einschließlich Preisindizes, Immobilienmärkte und Versicherungsrisiken Marketing- und Verschreibungsdatenbanken Katalog- und Prämienprogramm-Abonnements Weblogs (Clickstream-Analysen) Identifizieren, bereinigen und helfen, über das Kaufverhalten zu berichten. Führen Sie die Integration von Kundendaten und die Erfassung von Änderungsdaten in hochvolumigen Data Warehouses und E-Commerce-Daten-Webhouses, operativen Data Stores, Data Lakes und Flat Files durch. Verwenden Sie Ihr bevorzugtes BI- oder Analysetool oder nutzen Sie kompatible Analyse- und maschinelle Lernwerkzeuge wie KNIME, um das…
-
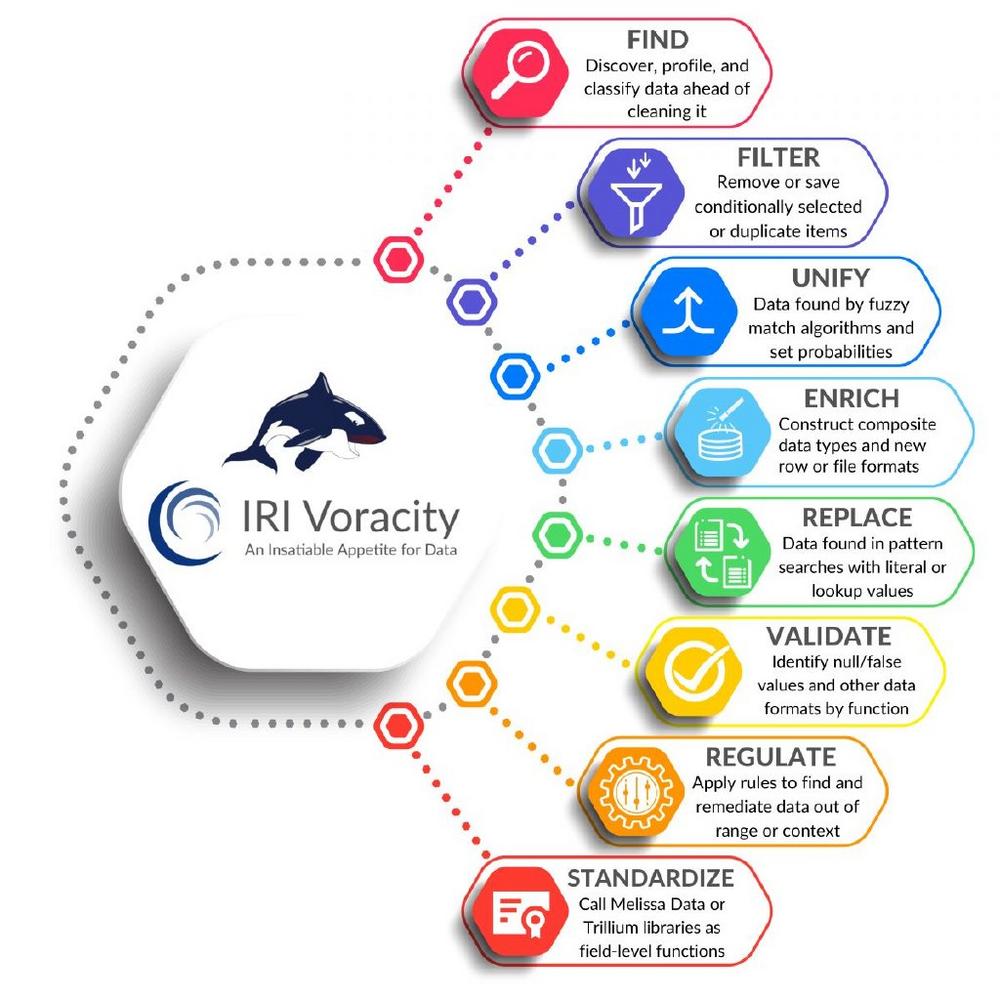
❌ Datenqualität ❌ Schnelles Data Profiling mit Datenbereinigung in strukturierten Tabellen oder Dateien für korrekte Daten ❗
Herausforderungen: Die Datenbereinigung kann kompliziert, zeitaufwändig und teuer sein. Die Funktionen, die Sie in 3GL, Shell-Skripten oder SQL-Prozeduren schreiben, können komplex und schwer zu pflegen sein. Sie erfüllen möglicherweise nicht alle Ihre Geschäftsregeln oder erledigen die gesamte Arbeit. Benutzerdefinierte Funktionen können auch in separaten Batch-Schritten oder in einer speziellen "Script-Transformationskomponente" ausgeführt werden, die Sie mit dem Datenfluss Ihres Tools verbinden und in kleineren Teilen ausführen müssen. Das ist ein Problem bei wachsenden Datenmengen. Datenqualitätswerkzeuge hingegen können auch viel von dieser Arbeit leisten. Leider sind sie bei hohem Volumen nicht besonders effizient und können schwer zu konfigurieren oder zu modifizieren sein. Sie können auch ein funktionaler Überfluss sein und viel kosten.…
-
❌ Daten für/von Snowflake ❌ Daten zu oder von Snowflake und einer anderen On-Premise Datenbank oder Cloud-Quelle zuordnen, mit Datenmaskierung ❗
Snowflake ETL und PII-Maskierung: Schnelles, kostengünstiges Datenmapping & Verwaltung! Möglicherweise sind Sie mit diesen zeitaufwendigen Problemen bei der Arbeit mit Snowflake konfrontiert: Datensuche, -profilierung und/oder -klassifizierung Integration oder Daten-Wrangling für DW/BI-Ops Datenbewegung/Migration zu/von Tabellen Transformieren oder Laden großer Tabellen Datenerfassung oder -replikation ändern Clustering oder Abfrage der Performance Generierung intelligenter und sicherer Testdaten Maskierung sensibler Daten Auch spezifische Leistungsdiagnosen und -abstimmungen brauchen Zeit und können andere Benutzer betreffen. Schließlich können gespeicherte SQL-Prozeduren auch ineffizient programmiert werden und erfordern eine Optimierung und dauern dann immer noch zu lange! Daten in Ordnung halten: IRI CoSort für die Vorsotierung von Flat-Files für Bulk-Ladungen und Inserts. Das entfernt den Overhead dieser Arbeit von Snowflake,…
-
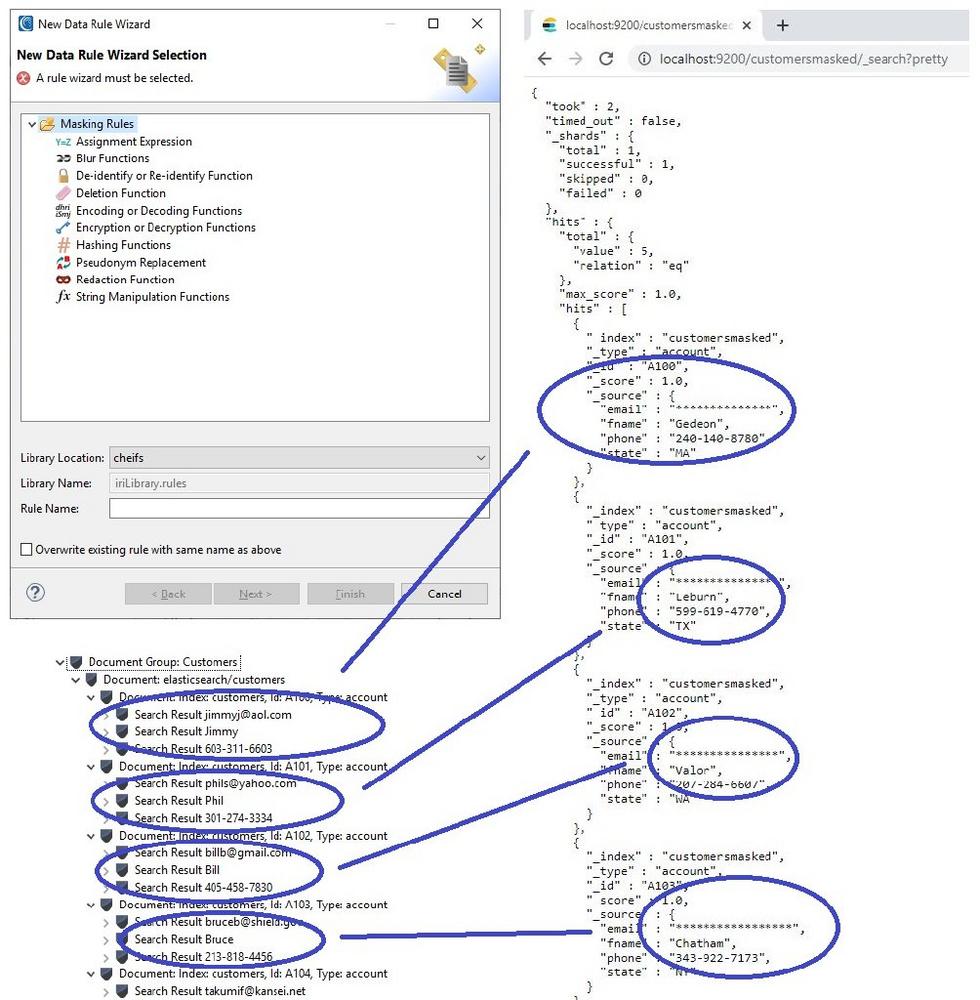
❌ Datensicherheit in Elasticsearch ❌ Genaues Auffinden und konsequenter Datenschutz in Elastic – DSGVO und GDPR konform ❗
PII in Elasticsearch finden und maskieren: Elasticsearch ist eine Java-basierte Suchmaschine, die über eine HTTP-Schnittstelle verfügt und ihre Daten in schemafreien JSON-Dokumenten speichert. Leider werden die Online-Datenbanken von Elasticsearch nach wie vor durch eine Flut von kostspieligen und schmerzhaften Verletzungen von personenbezogenen Daten (PII) geplagt. Würden jedoch alle PII oder andere sensible Informationen in diesen DBs maskiert, wären erfolgreiche Hacks und Entwicklungskopien unter Umständen unproblematisch. Die preisgekrönte datenzentrische ("Startpunkt") Sicherheitssoftware von IRI hat sich in einer Vielzahl von Umgebungen zur Aufhebung von Verstößen, Einhaltung des Datenschutzes und DevOps (Testdaten) wiederholt bewährt. Verwenden Sie zweckmäßige IRI-Datenschutzprodukte oder die umfassende IRI Voracity-Plattform, um sensible Daten zu finden und zu maskieren – egal…
-
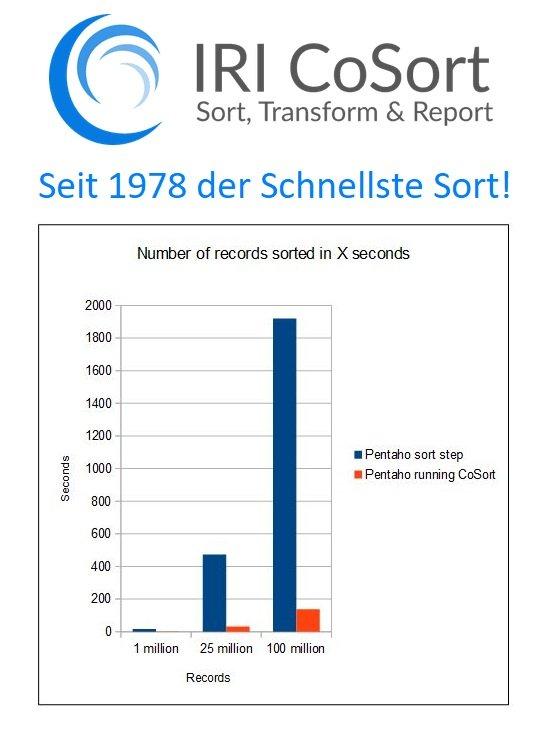
❌ Pentaho Data Integration ❌ Extreme Beschleunigung in PDI (ehemals Kettle) von ETL plus sicheren Datenschutz für GDPR ❗
Herausforderungen: Pentaho Data Integration ist zwar ein leistungsfähiges Werkzeug zur Aufbereitung und Integration von Daten, weist aber einige (Sicherheits-)Mängel auf! 1. Langsame Transformierungen: Native Sorts usw. laufen möglicherweise nicht schnell genug und nicht bei großer Menge. 2. Eingeschränkte De-ID-Funktionen: Daten, die durch Kettle fließen, können nicht maskiert oder verschlüsselt werden. 3. Begrenzte Testdaten: Kein Prototyp von ETL-Aufträgen ohne Verwendung von Produktionsdaten möglich. Dieser Artikel ist der erste in einer 3-teiligen Serie über die Verwendung von IRI-Produkten zur Erweiterung der Funktionalität und Verbesserung der Performance in Pentaho-Systemen. Wir zeigen zunächst, wie Sie die Sortierleistung verbessern können und stellen dann Möglichkeiten vor, Produktionsdaten zu maskieren und Testdaten in der Pentaho Data Integration-Umgebung…
-
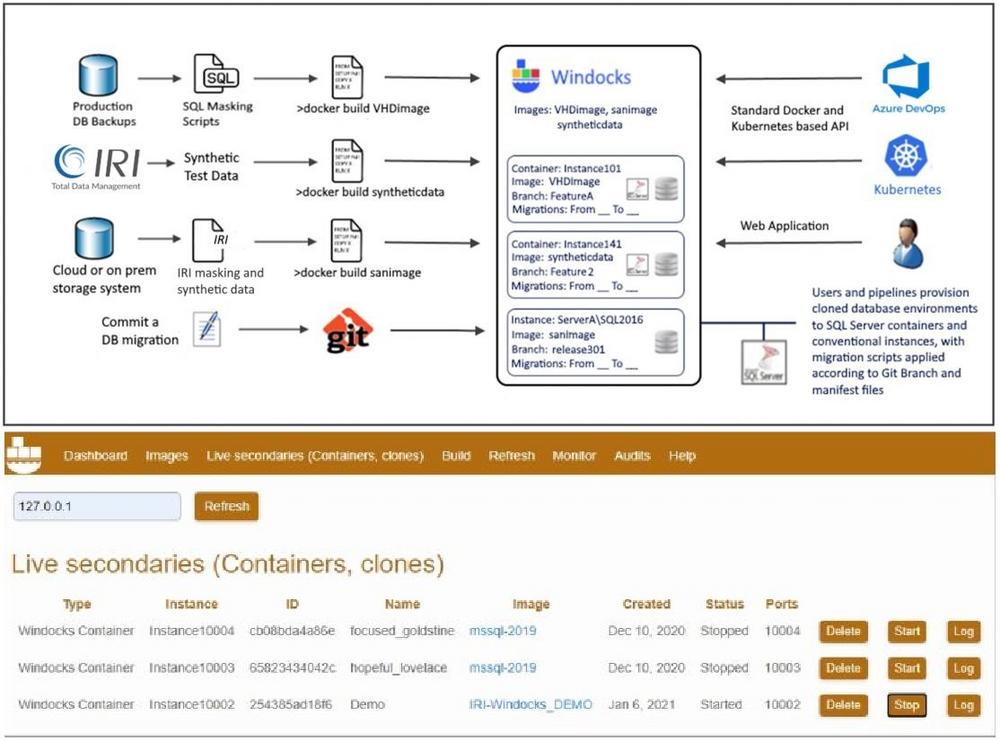
❌ TDM mit Windocks-Container ❌ Sichere, konforme und realistische Testdatenbankumgebungen = GDPR-konforme Testdaten ❗
Bereitstellung von Container-basierten virtualisierten Testdatenbanken: Integrierte PII-Maskierung, Subsetting und synthetische Daten für On-Demand-Lieferung! Innovative Routines International (IRI), Inc., ein führender Anbieter von Big Data Management und datenzentrierter Sicherheit, und Windocks, ein führender Anbieter von Datenbank-Containern und -Virtualisierung, haben ein gemeinsam entwickeltes, Container-basiertes Testdaten-Repository angekündigt. Das integrierte "Test Data Repo" liefert in Sekundenschnelle IRI-maskierte, subsettierte oder synthetisierte Datenbank-Images für Softwaretests, QA und andere Unternehmensanforderungen und reduziert gleichzeitig die Kosten für die Entwicklungs-/Testinfrastruktur um durchschnittlich 50 bis 70 %. Container werden in DevOps-Prozessen bevorzugt eingesetzt! Die IRI-Windocks-Lösung nutzt die Geschwindigkeit und Sicherheit von Containern für das Testdatenmanagement. Das IRI-Windocks Testdaten-Repo bietet sichere testfertige Datenbank-Klone auf Abruf, für Container, konventionelle Instanzen und Workstations,…
-
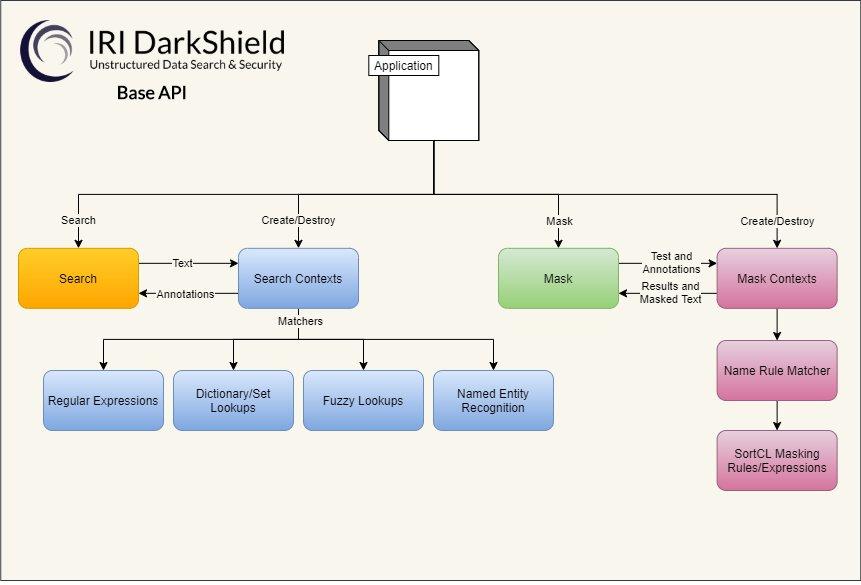
❌ RPC API für Datenschutz ❌ Sichere Datenmaskierung von unstrukturierten Streams (aka Datenströme) und Dateien ❗
PII in Dark Data: RPC API für die Suche und Maskierung von unstrukturiertem Text! IRI DarkShield Version 4 verfügt über ein Remote Procedure Call (RPC) Application Programming Interface (API) für die Suche und Maskierung von unstrukturiertem Text. Die API ermöglicht die Verwendung von DarkShields Suchmatchern und Maskierungsregeln außerhalb des Kontexts von Dateien. Diese "Basis-API" ist auch die zugrundeliegende Technologie, die von der DarkShield Files API verwendet wird, um Such- und Maskierungsoperationen speziell in Freiformtext, CSV/TSV, JSON/XML, PDF und Bilddateien durchzuführen. Die DarkShield-API ist als Plugin auf der IRI Web Services Plattform (Codename Plankton) aufgebaut, so dass der Benutzer selbst entscheiden kann, welche Dienste er benötigt, während er die gleichen Hosting-,…
-
❌ Microsoft SharePoint ❌ Zugriff auf Daten in SharePoint-Verzeichnissen/Directories für Datenmanagement und Datenschutz ❗
SharePoint verbinden und Daten nutzen: Unter Verwendung des Dateisystems über OneDrive! In diesem Artikel wird erklärt, wie man sich mit SharePoint-Sites verbindet und Daten von SharePoint-Sites – unter Verwendung des Dateisystems über OneDrive – für Operationen in IRI Workbench-unterstützter Datenmanagement-Software verwendet. Diese Software umfasst die IRI Voracity-Plattform und ihre Komponentenprodukte: CoSort, NextForm, RowGen, FieldShield, DarkShield und CellShield EE. Die IRI-Softwareprodukte für Datenmanagement und -schutz arbeiten mit einer Vielzahl von Datenquellen und -formaten. Der Zugriff auf Daten in SharePoint-Verzeichnissen war jedoch bisher unmöglich, da diese Dateien online gehostet werden. Genauer gesagt gab es keine Möglichkeit auf sie zuzugreifen, ohne sie in das Dateisystem herunterzuladen, es sei denn, die Dateidaten wurden gestreamt.…
-
❌ Testdatenmanagement ❌ Eine praktikable und überprüfte TDM-Strategie ist der beste Weg, damit genügend realistische Testdaten zur Verfügung stehen ❗
. Testdaten-Management: Für Qualität, Sicherheit und Nutzen! Wie Ihnen jeder, der mit den Herausforderungen von "healthcare.gov" vertraut ist, bestätigen kann, erfordert die Entwicklung komplexer Anwendungen einen angemessenen Zeitraum für formale Tests und umfassende Testdaten. Je besser und umfangreicher Ihre Testdaten sind, desto zuverlässiger können Ihre neuen Lösungen und Abläufe sein. Ziel des Testdatenmanagements (TDM) ist es, die Erzeugung von Testdaten zu systematisieren und deren Qualität, Sicherheit und Nutzen zu verbessern. TDM ist zu einem IT-Imperativ geworden. Laut dem InfoSys-Whitepaper "Test Data Management, Enabling Reliable Testing through Realistic Test Data: "Testteams müssen nicht nur exakte Testmethodiken befolgen, sondern auch die Genauigkeit der Testdaten sicherstellen. Sie müssen auch sicherstellen, dass die Tests…
-
❌ Splunk Datenverarbeitung ❌ Big Data vor der Indizierung verarbeiten und maskieren für höhere Leistung und End-to-End Datenschutz ❗
Splunk-App für Data Wrangling & Datenmaskierung: Die beste Möglichkeit für die Datenerkennung, -integration, -migration, -verwaltung und -analyse von Splunk Enterprise oder Splunk Enterprise Security! Der Vorteil ist ein nahtloser, gleichzeitiger operativer Daten-zu-Informationsfluss von der schnellen Vorbereitung und dem Schutz großer und kleiner Datenquellen durch Voracity bis hin zu den leistungsstarken Visualisierungen und dem adaptiven Response-Framework von Splunk. In einem einzigen Durchgang durch mehrere Eingaben können Voracity-Jobs Daten für Analysen transformieren, filtern, bereinigen, neu formatieren und in ein Stadium (Wrangling) bringen und die darin enthaltenen PII für Compliance- und Datenverletzungen zu de-identifizieren! Die Anwendung nimmt Daten, die von IRI-Jobs erzeugt werden die in den 4GL (*.cl)-Job-Skripten von "SortCL"-kompatiblen Produkten in Voracity…