-
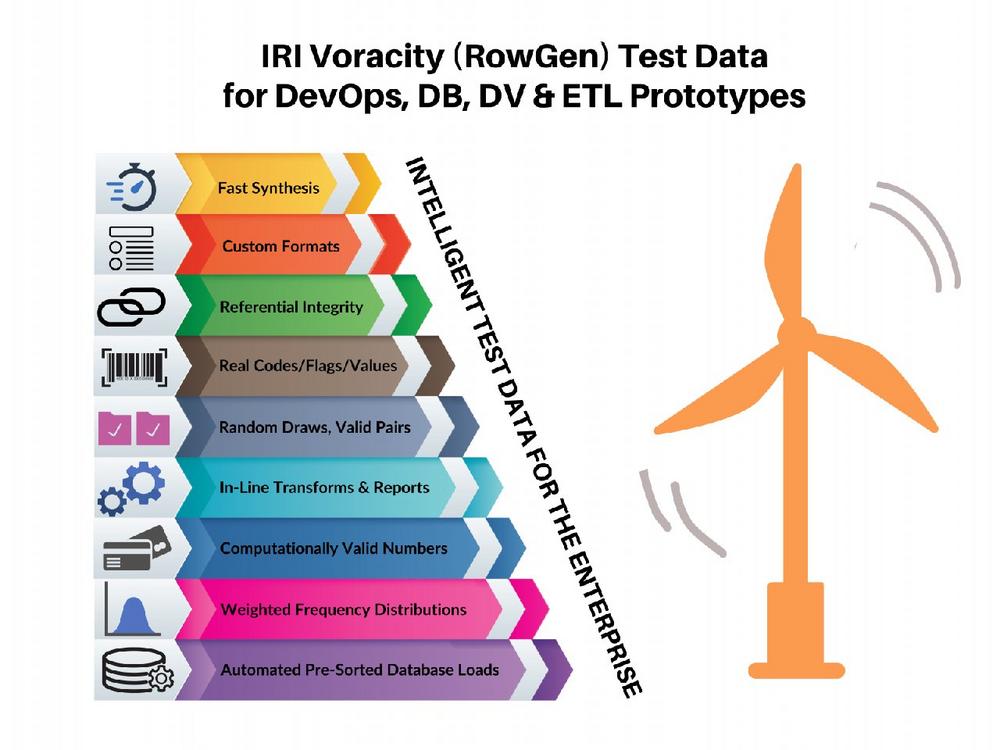
❌ Intelligente + synthetische Testdaten ❌ Erstellung von Test Data via Produktions-Metadaten für DevOps, DB, DV und ETL-Prototypen ❗
Herausforderungen: Anwendungen und Datenbanken haben ihre eigene Logik und einzigartigen Eigenschaften. Damit Testdaten in diesen Kontexten nützlich sind, müssen sie Produktionsmerkmale widerspiegeln, wie z.B: Auswahlbedingungen (Geschäftsregeln) Spaltenattribute und Transformationen Inter-Feld/Schlüssel-Beziehungen (referentielle Integrität) Wertebereiche und spaltenübergreifende Berechnungen Auch Testdaten zur Produktionsqualität müssen diese Attribute aufweisen: Typ – korrekte Spalten-/Feldwerte und Formate Breite – Werte mit aktuellen (und zukünftigen) Bereichen Häufigkeit – realistische Muster des Auftretens von Werten Tiefe – Volumina, die Skalierbarkeitsprobleme ansprechen In einer schnelllebigen DevOps- und Continuous Integration (CI)/ Continuous Deployment (CD)-Umgebung kann die Fähigkeit, konsistente und realistische Testsätze zu generieren und zu automatisieren, die in Format und Umfang sehr unterschiedlich sein können, eine große Herausforderung darstellen und Programmierer…
-
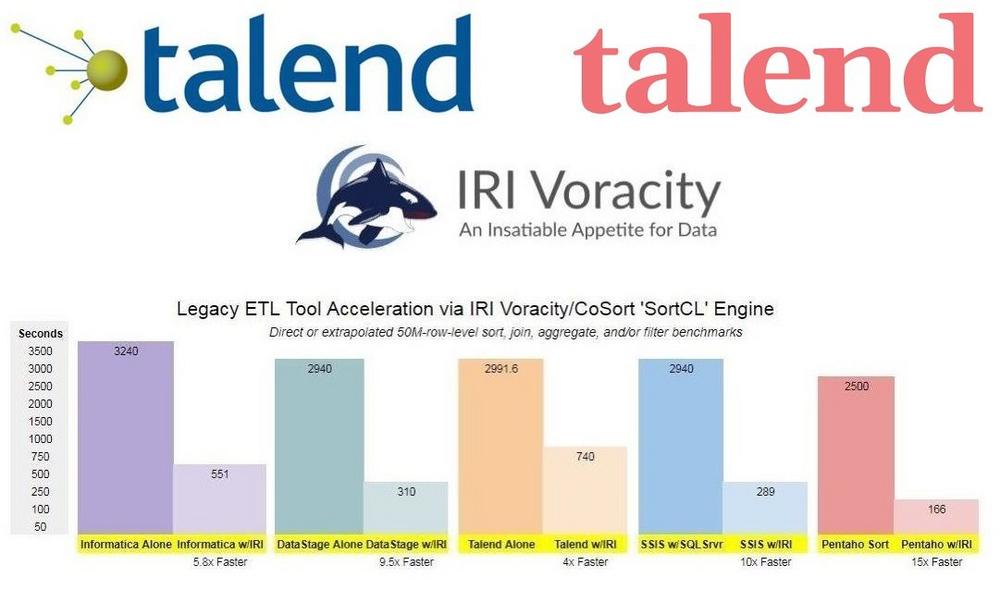
❌ Talend Data Fabric ❌ Mittels CoSort 4x schnellere Datenintegration, plus PII-Datenschutz via Datenmaskierung und synthetische Testdaten generieren ❗
Herausforderungen: Auch nach der Beratung und Abstimmung können große Datenmengen (d.h. mehr als eine Million Zeilen) nur langsam transformiert werden, insbesondere ohne ein teures Hardware- oder Versionsupgrade von Talend! Große Datenengpässe sind große Sortierungen, Joins, Aggregationen, Ladungen und manchmal auch Entladungen. Die Parallelisierung oder Optimierung in anderen Ebenen oder Tools kann unhandlich, wenn nicht sogar teuer sein und die Leistung für andere Benutzer beeinträchtigen. Aus Sicherheitssicht bietet Talend möglicherweise nicht die Funktionen zum Erkennen, Klassifizieren oder Maskieren von Daten oder zum Testen von Datenfunktionen, die Datenverwalter und Anwendungsentwickler benötigen Transformationen beschleunigen: Sort-Beschleunigung, Aggregation und Zusammenführen von Talend ETL-Strömen mit einem tSystem-Aufruf an die Programme CoSort Sort Sort Control Language (SortCL).…
-
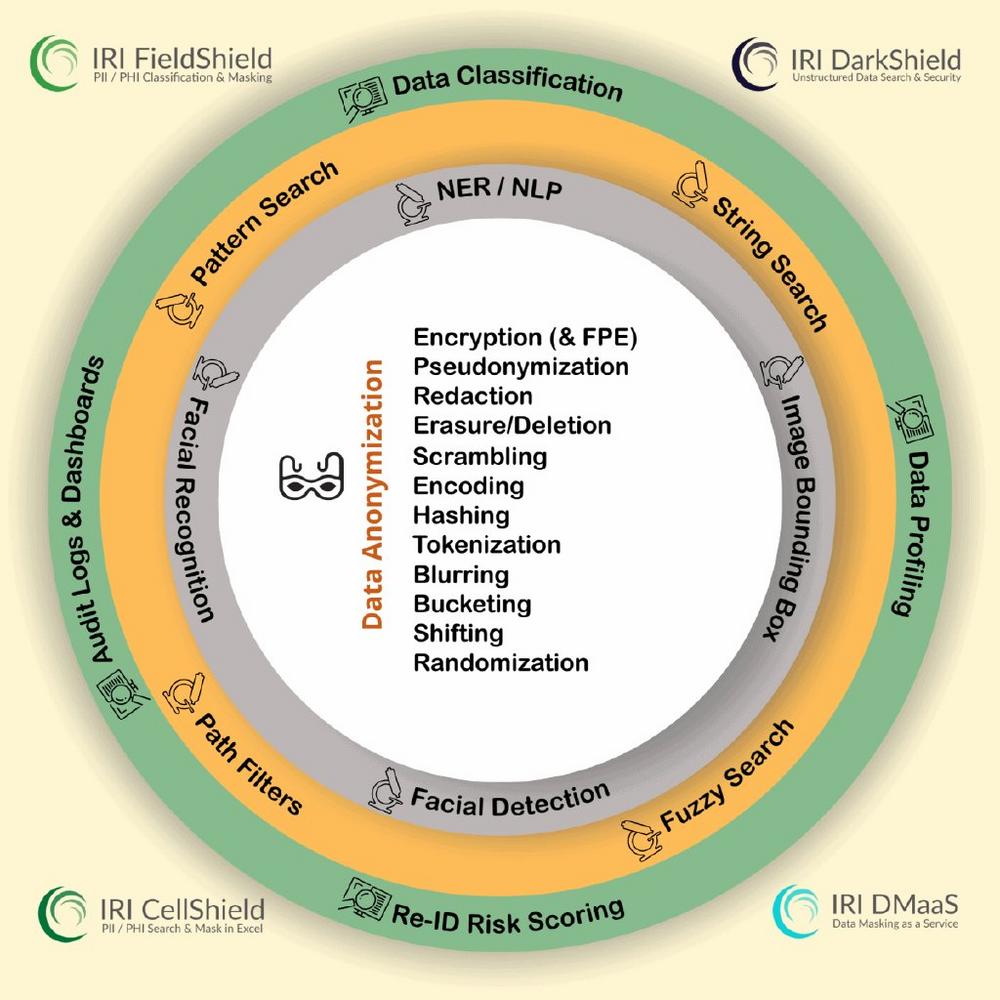
❌ Datenmaskierung ❌ Unabhängig davon, ob PII in Datenbank relational oder NoSQL, vor Ort oder in der Cloud – oder in einer EDI- oder Excel-Datei ❗
Datenmaskierung: Der Schutz von personenbezogenen Daten! Inmitten pausenloser Berichte über Datenschutzverletzungen und einem wachsenden regulatorischen Umfeld für persönliche identifizierbare Informationen (PII) weltweit, sind mehrere Technologielösungen und Compliance-Dienste entstanden, um den Schutz von PII zu thematisieren. Die logische Sicherheit durch Verschlüsselung in der einen oder anderen Form ist ein gemeinsamer Nenner des Ansatzes, aber die meisten kommerziellen Verschlüsselungsanwendungen sind begrentzt durch die Plattform, den Algorithmus und das Aussehen des Chiffriertextes, die Komplexität der Implementierung, der Laufzeitleistung und insgesamt der Kosten. Die Verschlüsselung von Datenquellen und -geräten auf Massenbasis verhindert den Zugriff auf nicht-sensible Daten, macht die Ziele ungeeignet für DevOps mit Tests und macht alle Daten durch einen einzigen Verstoß gegen…
-
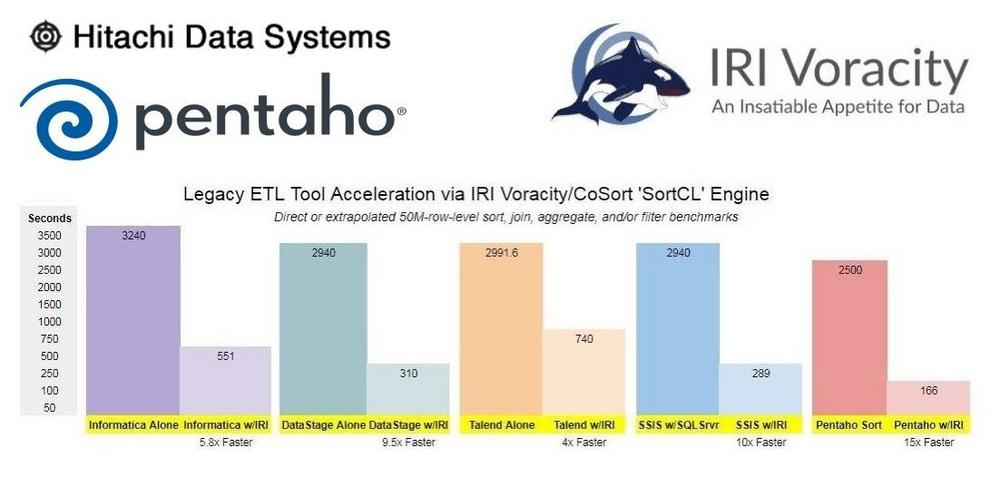
❌ Hitachi Vantara Pentaho ❌ Mithilfe von CoSort 15x schnellere Sort-Jobs, mit PII-Schutz via Datenmaskierung und synthetische Testdaten erzeugen ❗
Herausforderungen: Pentaho Data Integration (PDI) ist zwar ein leistungsfähiges Werkzeug zur Aufbereitung und Integration von Daten, weist aber auch einige Mängel auf! 1. Langsame Transformierungen: Native Sorts usw. laufen möglicherweise nicht schnell genug und nicht bei großer Menge. 2. Eingeschränkte De-ID-Funktionen: Daten, die durch Kettle fließen, können nicht maskiert oder verschlüsselt werden. 3. Begrenzte Testdaten: Kein Prototyp von ETL-Aufträgen ohne Verwendung von Produktionsdaten möglich. Lösungen: PDI-Workflows unterstützen Systembefehle, so dass Daten ohne Unterbrechung extern verarbeitet werden können. IRI Voracity oder seine Komponentensoftware kann Pentaho-Anwendern helfen! 1. Transformationen beschleunigen: Verwenden Sie den Shell-Schritt von PDI, um einen IRI CoSort-Auftrag (z.B. SortCL-Skript) aufzurufen, um die Sortier-, Joint- und Aggregationszeiten drastisch zu reduzieren. Ausführen mehrerer Aufträge in…
-
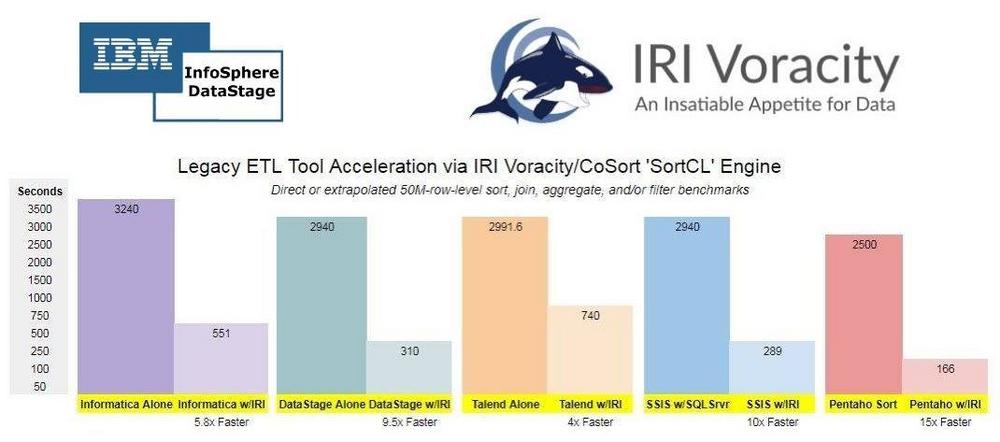
❌ IBM DataStage ❌ Unkompliziert 10x schnellere Datenintegration für legacy ETL-Tool InfoSphere DataStage ❗
Herausforderungen: Auch nach der Beratung und dem Tuning können große Datenmengen (d.h. mehr als eine Million Zeilen) nur langsam transformiert werden, insbesondere ohne ein teures Hardware- oder Versions-Upgrade von DataStage. Große Datenengpässe sind große Sortierungen, Joins, Aggregationen, Ladungen und manchmal auch Entladungen. Die Parallelisierung oder Optimierung in anderen Ebenen oder Tools kann unhandlich, wenn nicht sogar teuer sein und die Leistung für andere Benutzer beeinträchtigen. Aus Sicherheitssicht können die Datenmaskierungslösungen von IBM für einige teuer oder umständlich sein oder nicht alle Funktionen der PII-Erkennung oder des Datenschutzes für andere bereitstellen. Lösungen: DataStage-Transformationen beschleunigen: Beschleunigen Sie das Sortieren, Aggregieren und Zusammenführen in einem einzigen Durchgang mit der CoSort Sort Control Language…
-
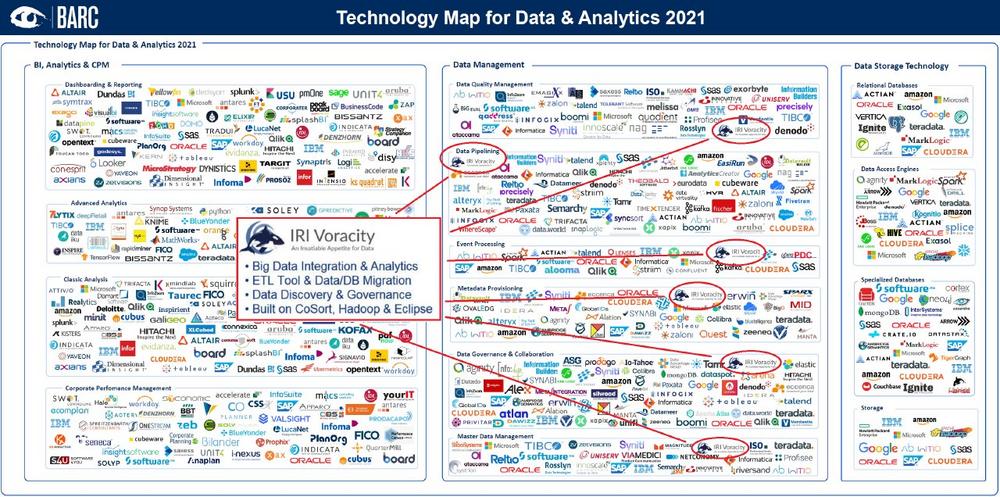
❌ Map für Data, BI & Analytics ❌ Endlich den Markt überblicken: BARC präsentiert transparente + strukturierte Übersicht über Software-Lösungen ❗
Endlich den Markt überblicken: Transparenz im dynamischen Markt für Data & Analytics! BARC präsentiert eine transparente und strukturierte Map-Übersicht über Lösungen in den Bereichen Data, BI & Analytics. „Den Durchblick auf dem wachsenden Softwaremarkt zu behalten, ist nicht einfach. Daher haben wir es uns zur Aufgabe gemacht, Anwenderinnen und Anwendern die Technology Map for Data & Analytics an die Hand zu geben“, sagt Patrick Keller, Senior Analyst Data & Analytics zur Neuerscheinung. Technology Map kostenfrei: Die Map mit über 700 einzelnen Lösungen ist zum einen als statische Version im BARC Guide Data, BI & Analytics sowie als interaktiver Browser auf bi-scout.com verfügbar. Sie zeigt auf einen Blick relevante Anbieter und…
-
❌ Oracle Enterprise Linux ❌ Oracle zertifiziert Leistungs- und Sicherheitsfunktionen von IRI Voracity – die Plattform für Big Data Management ❗
Das Team der Oracle Linux und „Virtualization Alliance“ heißt IRI, The CoSort Company, und seine Datenverwaltungsplattform Voracity im ISV-Ökosystem willkommen. IRI hat Voracity auf Oracle Linux 7 und 8 zertifiziert und unterstützt diese Plattform. Damit steht Oracle-DBAs, großen Datenarchitekten und Datenschutzteams ein reichhaltiger Satz an Leistungs- und Sicherheitsfunktionen zur Verfügung. IRI Voracity kombiniert Datenermittlung, Integration, Migration, Verwaltung und Analyse in einem verwalteten Metadaten-Framework, das auf Eclipse aufbaut. Es nutzt die bewährte Leistung von IRI CoSort oder Hadoop MR2, Spark, Spark Stream, Storm und Tez. IRI Voracity läuft auf der Oracle Cloud-Infrastruktur und ermöglicht moderne PaaS- und SaaS-Optionen für KMU- und Unternehmenskunden, die eine schnellere, kostengünstigere und hochsichere Cloud-Ausführung von ETL-Aufträgen…
-
❌ EMM Metadaten Management ❌ Metadaten dienen als genetische Zusammensetzung der Daten-DNA ❗
EMM: Erfassen des Geschäftswerts mit Enterprise Metadata Management! In dem Maße, wie die Daten selbst zur Währung geworden sind, haben sich auch die Metadaten, die sie beschreiben – und was mit ihnen geschieht – zu einem Kernbestandteil des modernen Geschäftslebens entwickelt. Metadaten verweben sich durch alle Informationen hindurch; wie die DNA dienen sie als genetische Zusammensetzung der Daten. Auch wenn Metadaten also nicht die offensichtlichsten Daten sind, die geschaffen werden, so sind sie doch von enormem Wert für die Erschließung und Nutzung des Wertes von Unternehmensinformationen. Zu diesem Zweck kann ein organisierter Prozess der Verwaltung von Unternehmensmetadaten (EMM) Vorteile bieten, die über die strukturierte Welt der Information hinausgehen. Er kann…
-
❌ Data Governance ❌ Ein übergreifender Prozess vom Policy-Management, zum Data Stewardship und zur Datenqualität ❗
Data Governance: Der Begriff hat keine verbindliche Definition, aber in der Praxis ist es entweder der übergreifende Prozess, durch den Datenbestände verwaltet werden, um Vertrauenswürdigkeit und Verantwortlichkeit zu gewährleisten, oder die höchste Ebene dieses Prozesses, diejenige, auf der Entscheidungen getroffen und Richtlinien erstellt werden. Dies gilt unabhängig davon, ob sich die Daten in Produktion befinden, getestet oder archiviert wurden. Der Prozess als Ganzes kann in drei "Stufen" betrachtet werden: Richtlinienmanagement, Datenverwaltung und Datenqualität. Warum ist es wichtig? Es gibt drei Gründe, warum Data Governance wichtig ist. Erstens ist es mehr und mehr auf das Geschäft ausgerichtet und ein Top-Down-Ansatz zur Verwaltung und Kuratierung von Daten. Es geht zunehmend darum, die…
-
❌ Datenmaskierung von Transkript ❌ Gleichzeitig Daten scannen + (konsistent) maskieren, auch NoSQL wie Elasticsearch ❗
Entdecken, Bereitstellen und Löschen von PIIs: Finden Sie sensible Daten in unstrukturierten Quellen mit Hilfe mehrerer Suchtechniken. Verwenden Sie die Suchergebnisse, um die PII gleichzeitig oder getrennt bereitzustellen, zu entfernen oder zu korrigieren, um die Bestimmungen des GDPR zur Übertragbarkeit, Löschung oder Berichtigung von Daten einzuhalten. Lokaler & Cloud-Schutz: Egal, ob die PII auf Ihrem Desktop, in S3 oder an einem beliebigen Ort in Ihrem Netzwerk liegen, DarkShield schützt sie. DarkShield findet und maskiert sensible Informationen in mehreren unstrukturierten DB- und Dateiformaten in mehreren Silos gleichzeitig. Audit-bereite Berichte generieren: Abfrage und Anzeige der DarkShield-Such- und Korrekturergebnisse in der integrierten, interaktiven Instrumententafel. Oder verwenden Sie IRI CoSort, BIRT oder Ihre RDB…