-
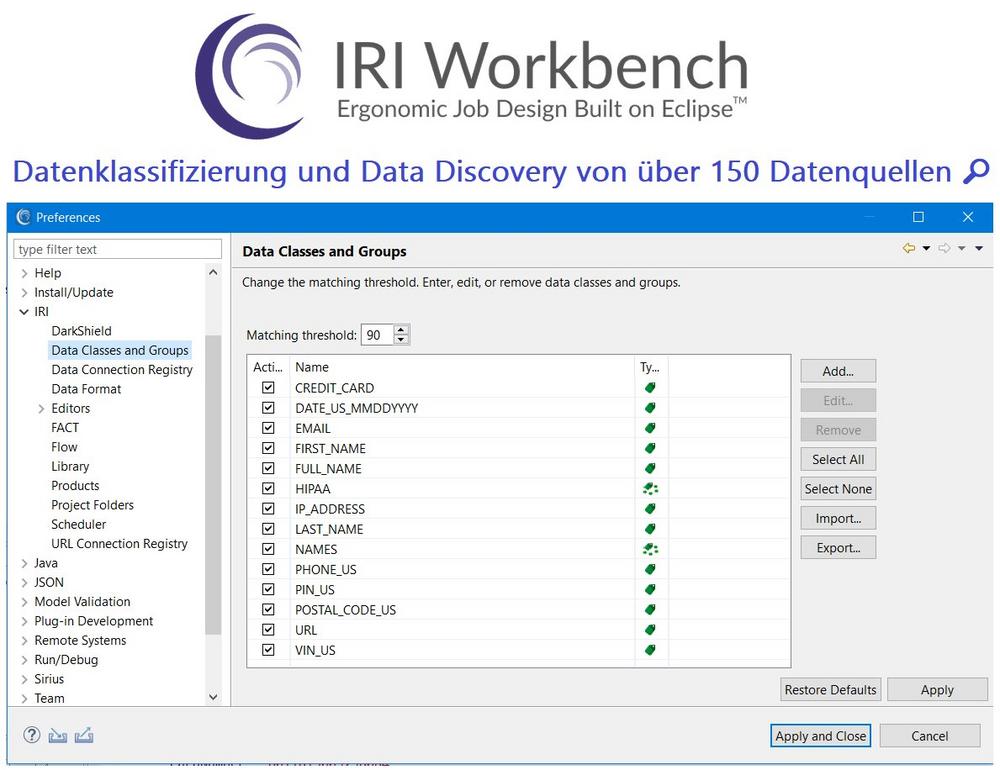
❌ Datenvalidierung ❌ Eigene Skripte für die Verwendung bei der Datenklassifizierung und Data Discovery erstellen ❗
Zugriff auf viele gängige Datenvalidierungsskripte: Auch Erstellung eines benutzerdefinierten Datenklassen-Validator! Dies ist der zweite Teil einer zweiteiligen Blog-Reihe, die sich mit der Datenklassenvalidierung in der IRI Workbench befasst. Der erste Artikel gab einen Überblick über die Validierungsskripts und ihre Verwendung in einem Datenentdeckungs- oder Klassifizierungsauftrag. Dieser zweite Artikel zeigt, wie man ein benutzerdefiniertes Validierungsskript für eine spezielle Datenklasse oder -gruppe erstellt. IRI Workbench™ ist die kostenlose grafische Benutzeroberfläche (GUI) und integrierte Entwicklungsumgebung (IDE) für alle IRI-Datenmanagement- und Schutzsoftwareprodukte und die Voracity-Plattform, die sie beinhaltet. Die unter Windows, MacOS und Linux verfügbare Workbench steuert Aufträge über bewährte IRI CoSort und Hadoop Engines und nutzt dabei alles, was Eclipse™ bietet. Wir werden…
-
❌ Datenschutz in Excel ❌ Per Add-In sensible PII in jeder XLS + XLSX-Datei automatisch schützen via Datenmaskierung, Datenanonymisierung,.. ❗
Lückenlose Sicherheit von Excel-Tabellen: IRI CellShield® ist ein Add-In für Microsoft Excel®, das die sensiblen Informationen in einer oder mehreren Tabellenkalkulationen schützt und es Ihnen ermöglicht, die Datenschutzgesetze einzuhalten und Datenverstöße zu annullieren. Es gibt zwei Editionen von CellShield: CellShield Personal Edition (PE) und CellShield Enterprise Edition (EE). IRI CellShield ist das einzige vollwertige, professionelle Datenentdeckungs-, Maskierungs- und Auditierungspaket für Excel 2010, 2013, 2016 und 2019 (plus Office 365) Arbeitsmappen in Ihrem LAN oder in der Cloud! CellShield Version 2.0 bietet viele von Benutzern angeforderte Upgrades, darunter die Möglichkeit, UTF-8-Daten, sensible Formeln und ganze Blätter gleichzeitig zu schützen. Außerdem wurde die CellShield Enterprise Edition um zusätzliche Such-, Maskierungs- und grafische…
-
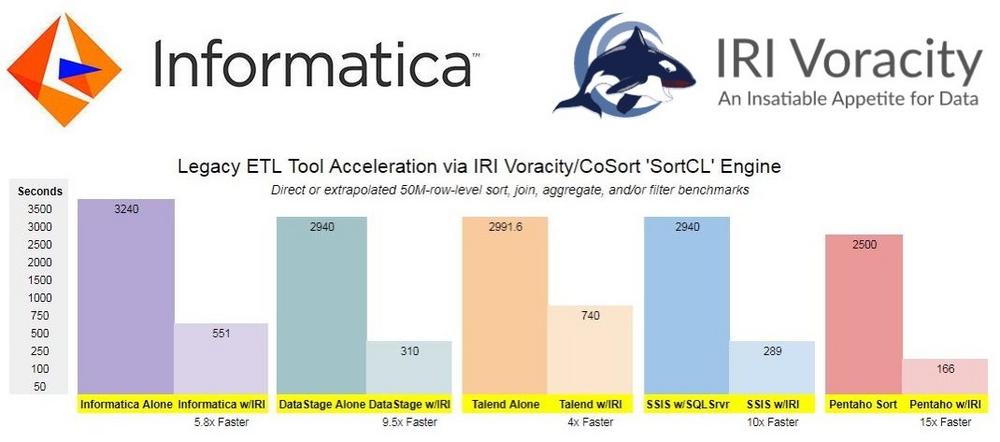
❌ Pushdown-Optimierung ❌ Unkompliziert Informatica 6x schneller mit CoSort für PDO mit Filter, Sort, Join + Aggregate ❗
Informatica Pushdown-Optimierung: Große Datenintegrationsaktivitäten können außerhalb der Datenbank in einer ETL-Umgebung (Extract, Transform, Load) oder innerhalb der Datenbank in ELT stattfinden! Ein Beispiel für eine ELT-Operation wäre die Option Pushdown-Optimierung von Informatica, bei der Benutzer Daten in einer relationalen Datenbank wie Oracle oder in Teradata transformieren. Laut Informatica ermöglicht dieser Ansatz "den IT-Systemen und ihren Betreibern, auf wechselnde Anforderungen und Spitzenverarbeitungsanforderungen zu reagieren". Unsere Kunden sind der Meinung, dass die Arbeit der großen Datentransformation nicht in Datenbanken gehört, die für Speicherung und Abruf konzipiert sind. Transformationen in der Datenbankschicht können die Datenbank und das gesamte System belasten, Ressourcen aus der Wartung der Datenspeicherung ziehen und Abfragen verlangsamen. Die Geschwindigkeit ist…
-
❌ Einheitliche Metadaten ❌ Der Schlüssel zur nahtlosen Integration, Bereinigung, Maskierung, Analyse und Bewältigung von Änderungen ❗
Metadaten- und MDM-Lösungen: Metadaten definieren das Layout und die Anordnung von Transaktions- und Stammdaten im Unternehmen! Laut Guido de Simone von Gartner ist das Enterprise Metadata Management (EMM) darauf ausgelegt, die Informationen in unserem Unternehmen zu verknüpfen, abzustimmen und zu verwalten. Da die effektive Verwaltung von Metadaten ein Schlüssel zur ordnungsgemäßen Integration, Bereinigung, Sicherung und Bewältigung von Datenänderungen ist, ist eine einfache und einheitliche Metadateninfrastruktur wünschenswert. Die Datenmanagement-Plattform IRI Voracity und ihre Produkte IRI Data Manager und die IRI Datenschutz-Suite nutzen dieselben einfachen 4GL-Metadaten für das Layout und die Manipulation der Daten. Im Gegensatz zu den Metadaten in älteren Plattformen sind die Datendefinitionsdatei (DDF), die Mapping-Aufgabe (Jobsteuerung) (.*CL), Skripte, Datenklassen-…
-
❌ Inkrementelle Datenmaskierung + Mapping ❌ Änderungen in Quelltabelle erkennen, aktualisieren + in neues Ziel verschieben ❗
Änderungen erkennen und aktualisieren: Inkrementelle Datenmaskierung und Mapping! Inkrementelle Datenreplikation, Maskierung, Integration (ETL) und andere Datenaktualisierungsoperationen sind in häufig aktualisierten Datenbankumgebungen üblich. Diese Jobs erfordern die Erkennung von Ergänzungen und Aktualisierungen von Tabellen. Solche dynamischen Operationen lassen sich in IRI-Voracity-Workflows, die in der IRI-Workbench (WB) entworfen und ausgeführt werden, leicht automatisieren. Alle Details zu diesen Operationen finden Sie hier im Blog-Artikel unseres Partners IRI Inc. Dieser Artikel enthält ein Workflow-Beispiel, das Benutzer von Voracity, FieldShield, CoSort oder der DBMS-Edition NextForm implementieren können, um regelmäßig auf Änderungen in einer Quelltabelle (in diesem Fall Oracle) zu prüfen, um zu entscheiden, wann Daten in ein neues Ziel (MySQL) verschoben werden sollen. Es wird…
-
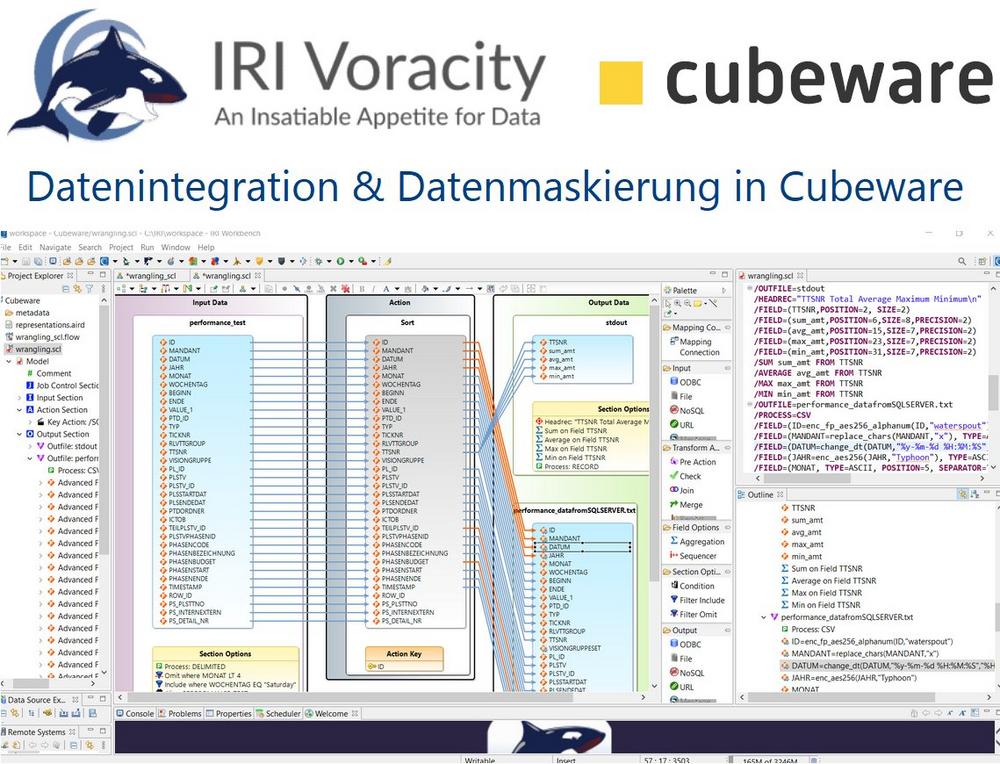
❌ Cubeware Cockpit ❌ Schnellere Datenintegration und GDPR-anonymisierte Daten für BI-Analysen in Cubeware Cockpit ❗
In früheren Artikeln im Business Intelligence (BI)-Abschnitt dieses Blogs hat IRI beschrieben, wie der Umgang mit Daten mit der SortCL-Engine im Datenmanipulationsprodukt IRI CoSort und der Datenverwaltungsplattform Voracity die Zeit bis zur Datenvisualisierung und damit zu verwertbaren Erkenntnissen in BI-Tools verkürzt. In diesem Artikel werden die Vorteile des Data Wranglings hervorgehoben, die Voracity für Analysen in der Cubeware-Plattform bietet. Voracity ist zwar sehr schnell im Umgang mit Daten und verfügt über ein breites Spektrum an Datenmanipulations- und Datenschutzfunktionen, es fehlt jedoch ein Onboard-Visualisierungs- und Dashboarding-Tool. Hier kommt Cubeware ins Spiel. Umgekehrt steigert Voracity für Anwender von Cubeware Software den Wert ihres Importer-Prozesses durch schnelle, konsolidierte Datentransformation, Bereinigung und Maskierung. Cubeware…
-
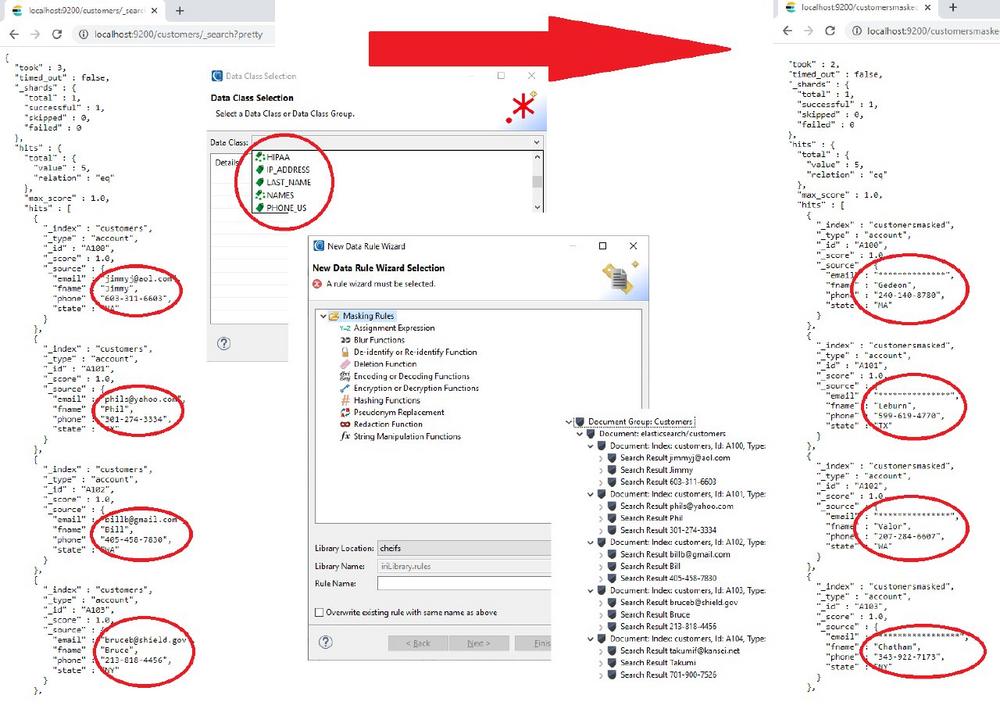
❌ Schutz von PII in NoSQL ❌ Formaterhaltende Verschlüsselung, Schwärzung und Pseudonymisierung in NoSQL Datenbank-Tabellen❗
Wie man PII in Elasticsearch findet und maskiert: Elasticsearch ist eine Java-basierte Suchmaschine, die über eine HTTP-Schnittstelle verfügt und ihre Daten in schemafreien JSON-Dokumenten speichert. Leider werden die Online-Datenbanken von Elasticsearch nach wie vor durch eine Flut von kostspieligen und schmerzhaften Verletzungen von personenbezogenen Daten (PII) geplagt. Würden jedoch alle PII oder andere sensible Informationen in diesen DBs maskiert, wären erfolgreiche Hacks und Entwicklungskopien unter Umständen unproblematisch. Der Zweck von IRI DarkShield ist es, diese Informationen in der Produktion oder im Test mit Hilfe von Anonymisierungsfunktionen, die dem Datenschutzrecht entsprechen, zu sperren. Der Such- und Maskenassistent Elasticsearch in der grafischen IDE der IRI-Workbench für IRI DarkShield verwendet die gleichen Werkzeuge…
-
❌ Datenbank-Unloading ❌ Beschleunigung der Datenerfassung für Data Warehouse ETL, Datenbankmigration/Replikation, Archivierung + Offline-Reorgs ❗
Datenerfassung beschleunigen: Unloads 7x schneller mit paralleler Abfragetechnologie! IRI FACT verwendet native Datenbank-APIs und parallele Verarbeitung, um Tabellen schneller in Flat-Fiels umzuwandeln als jedes andere Entladetool oder -verfahren. FACT skaliert linear im Volumen, so dass das Entladen einer Zwei-Milliarden-Zeilentabelle nicht mehr als doppelt so lange dauern sollte wie das Entladen einer Ein-Milliarden-Zeilentabelle. Die Kombination der leistungsstarken Extraktion von FACT mit den leistungsstarken, konsolidierten Datentransformationen und vorsortierten Bulkladungen von IRI CoSort ist der schnellste und kostengünstigste Weg, um Big Data ETL– und Offline-Reorgs durchzuführen. IRI FACT ist der schnellste Weg, um gleichzeitig: Entladen von sehr großen Datenbank-(VLDB)-Transaktions-(Fakten)-Tabellen formatierte Flat-Files aus einer Tabelle erzeugen Erstellen der Steuerdatei-Metadaten für Datenbank-Massenladeprogramme Erstellen von IRI…
-
❌ Realistische Testdaten ❌ Testdatenmanagement (TDM) für synthetische Erzeugung von sicheren und realistischen Testdaten❗
. Testdatenverwaltung: Ein Leitfaden für Testdatenmanagement! Wie jeder, der mit den Herausforderungen des Gesundheitswesens vertraut ist, kann Ihnen sagen, dass die Entwicklung komplexer Anwendungen einen angemessenen Zeitraum formaler Tests und umfassende Testdaten erfordert. Je besser und umfangreicher Ihre Testdaten sind, desto zuverlässiger können Ihre neuen Lösungen und Abläufe sein. Ziel des Testdatenmanagements (TDM) ist es, die Generierung von Testdaten zu systematisieren – und die Qualität, Sicherheit und Nützlichkeit von Testdaten zu verbessern. TDM ist zu einer IT-Imperativität geworden. Laut dem InfoSys-Whitepaper "Testdatenmanagement, Ermöglichung zuverlässiger Tests durch realistische Testdaten:" Testteams müssen nicht nur exakte Testmethoden befolgen, sondern auch die Genauigkeit der Testdaten sicherstellen. Sie müssen auch sicherstellen, dass die Tests die…
-
❌ Big Data 50 ❌ Wieder in Folge von DBTA gelistet – 50 Unternehmen als Innovationstreiber für Big Data im Jahr 2020 ❗
Was unsere 42 Jahre Erfahrungen mit Big Data für Sie bedeuten: Seit 1978 hat sich Innovative Routines International (IRI) auf die Manipulation und Verwaltung von "Big Data" spezialisiert. Lange bevor der Begriff unter die Rubrik Hadoop fiel, verwendeten ihn unsere Kunden zur Beschreibung ihrer sehr großen Datei- und Datenbankquellen, die in CoSort transformiert und darüber berichtet wurden … und immer noch werden! Obwohl die heutigen CoSort-basierten Aktivitäten weitaus umfangreicher sind, laufen sie immer noch bekanntermaßen schnell im Volumen. Sie werden als Front-End in Eclipse ausgeführt und sind jetzt in einer erschwinglichen All-in-One-Datenmanagement-Plattform namens Voracity für mehrere Quellen verfügbar: Data Discovery: Klassifizierung, Diagrammerstellung, Profilerstellung und Suche von strukturierten, semistrukturierten und unstrukturierten…