-
❌ IBM DataStage ❌ Nahtlos 10x schnellere Datenintegration für ETL-Tool IBM InfoSphere DataStage ❗
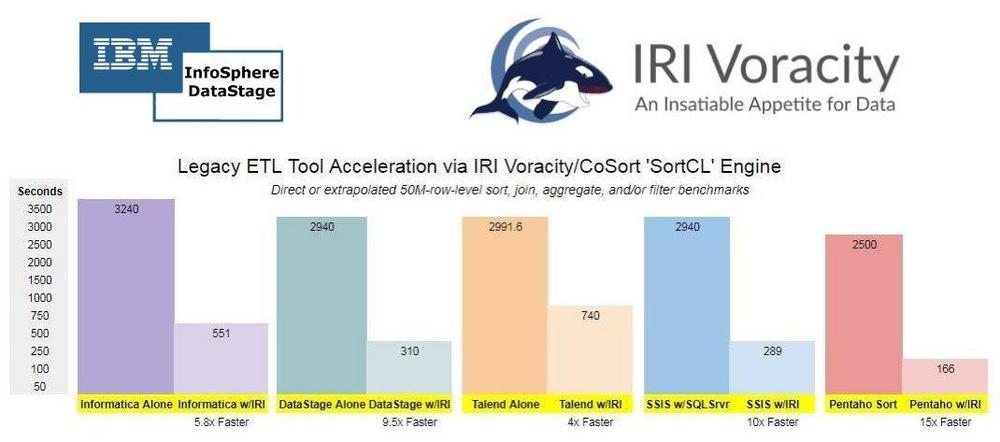
Herausforderungen: Auch nachdem Tuning können große Datenmengen (d.h. mehr als eine Million Zeilen) nur langsam transformiert werden, insbesondere ohne ein teures Hardware- oder Versions-Upgrade von DataStage. Große Datenengpässe sind große Sortierungen, Joins, Aggregationen, Ladungen und manchmal auch Entladungen. Die Parallelisierung oder Optimierung in anderen Ebenen oder Tools kann unhandlich, wenn nicht sogar teuer sein und die Leistung für andere Benutzer beeinträchtigen. Aus Sicherheitssicht können die Datenmaskierungslösungen von IBM für einige teuer oder umständlich sein oder nicht alle Funktionen der PII-Erkennung oder des Datenschutzes für andere bereitstellen. DataStage-Transformationen beschleunigen: Beschleunigen Sie das Sortieren, Aggregieren und Zusammenführen in einem einzigen Durchgang mit der CoSort Sort Control Language (SortCL) in einer sequentiellen Dateistufe…
-
❌ Pentaho Data Integration ❌ 16-fache ETL-Beschleunigung von PDI (vorher Kettle) und End-to-End Datenmanagement ❗
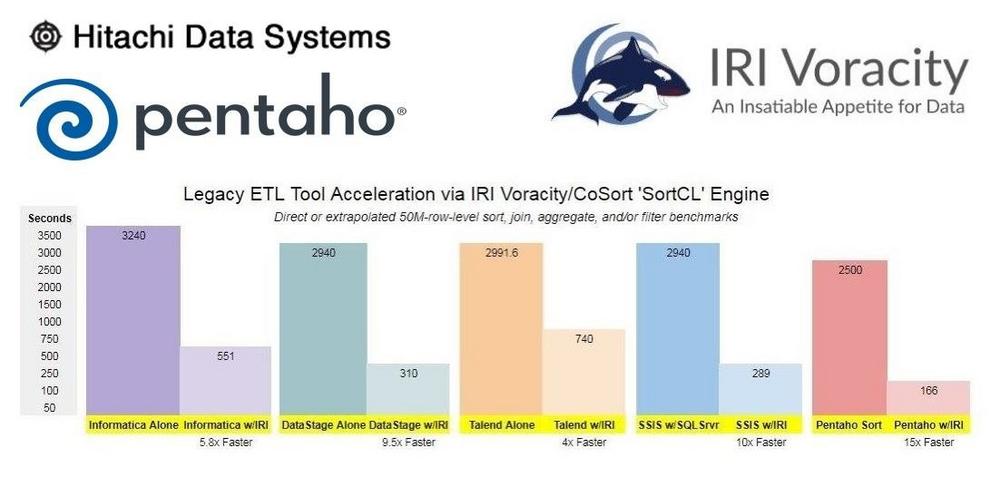
Pentaho Data Integration (PDI) von Hitachi Vantara ist zwar ein leistungsfähiges Werkzeug zur Aufbereitung und Integration von Daten, weist aber einige (Sicherheits-)Mängel auf! 1. Langsame Transformierungen: Native Sorts usw. laufen möglicherweise nicht schnell genug und nicht bei großer Menge. 2. Eingeschränkte De-ID-Funktionen: Daten, die durch Kettle fließen, können nicht maskiert oder verschlüsselt werden. 3. Begrenzte Testdaten: Kein Prototyp von ETL-Aufträgen ohne Verwendung von Produktionsdaten möglich. Dieser Artikel ist der erste in einer 3-teiligen Serie über die Verwendung von IRI-Produkten zur Erweiterung der Funktionalität und Verbesserung der Performance in Pentaho-Systemen. Wir zeigen zunächst, wie Sie die Sortierleistung verbessern können und stellen dann Möglichkeiten vor, Produktionsdaten zu maskieren und Testdaten in der…
-
❌ Informatica ❌ Nahtlos 6-fache ETL-Beschleunigung mit Pushdown-Optimierung und DSGVO-konformen Datenschutz gewährleisten❗
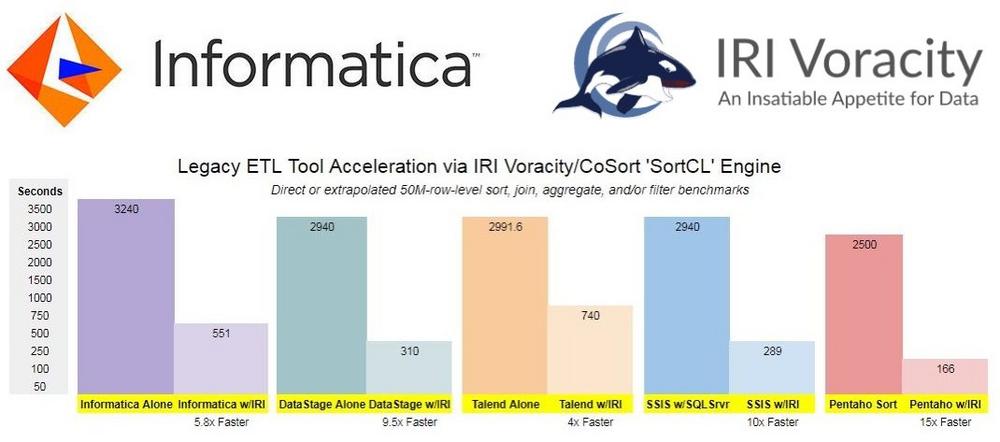
Informatica beschleunigen oder ersetzen: ETL-Jobs einfach beschleunigen oder neu gestalten! PowerCenter-Transformationen sehr großer Datenmengen erfordern eine Partitionierung und können auch nach Rücksprache und Abstimmung langsamer laufen als gewünscht. Engpässe können bei großen Sortier-, Join-, Aggregations-, Lade- oder Entladevorgängen auftreten. Die ersten Optionen von Informatica zur "Pushdown-Optimierung" verlagern die Last in eine bereits ausgelastete Datenbank (Oracle) oder eine sehr teure/komplexe Plattform (Teradata). Eine weitere ernste Notwendigkeit ist der Schutz sensibler Produktionsdaten, die durch das Informatica Data Warehouse, den Data Mart oder den Testbetrieb transportiert werden. Möglicherweise müssen Sie rollenbasierte Datensicherungen anwenden oder große Mengen realistischer, referenzfreier Testdaten für Prototypanwendungen erzeugen und bestimmte Ziele ausfüllen. Pushdown-Optimierung: Um Transformationen, Berichte und Schutz auf…
-
❌ Data Vault 2.0 ❌ Datenmigration von RDB-Datenbankmodell in eine Data Vault 2.0 Architektur – der hybride Ansatz ❗
End-to-End Datenmanagement: Die IRI Workbench IDE enthält einen Data Vault Generator Assistenten, der den Benutzern der IRI Voracity Plattform hilft, ein relationales Datenbankmodell in eine Data Vault 2.0 (DV) Architektur zu migrieren. Der Assistent hat drei Ausgabeoptionen, die von den Bedürfnissen des Benutzers abhängen. Alle Optionen erstellen das Entity Relationship Diagram (ERD) für die Ausgaben. Die erste Option erzeugt nur die vollständige DDL und ERD. Die zweite Option erstellt eine DDL für Tabellen, die noch nicht existieren, und erstellt außerdem Jobskripte zum Laden der Daten aus den Quelltabellen in die neuen Zieltabellen. Die dritte Option erstellt eine DDL für Tabellen, die nicht existieren, und lädt die neuen Tabellen mit zufällig…
-
❌ Beschleunigung von Splunk ❌ Schnellere Datenverarbeitung vor der Indizierung in Splunk Phantom für bessere Performance ❗
Splunk-App für schnelleres Data Wrangling und sichere Datenmaskierung: Die beste Möglichkeit für die Datenerkennung, -integration, -migration, -verwaltung und -analyse von Splunk Enterprise oder Splunk Enterprise Security! Der Vorteil ist ein nahtloser, gleichzeitiger operativer Daten-zu-Informationsfluss von der schnellen Vorbereitung und dem Schutz großer und kleiner Datenquellen durch Voracity bis hin zu den leistungsstarken Visualisierungen und dem adaptiven Response-Framework von Splunk. In einem einzigen Durchgang durch mehrere Eingaben können Voracity-Jobs Daten für Analysen transformieren, filtern, bereinigen, neu formatieren und in ein Stadium (Wrangling) bringen und die darin enthaltenen PII für Compliance- und Datenverletzungen zu de-identifizieren! Die Anwendung nimmt Daten, die von IRI-Jobs erzeugt werden die in den 4GL (*.cl)-Job-Skripten von "SortCL"-kompatiblen Produkten…
-
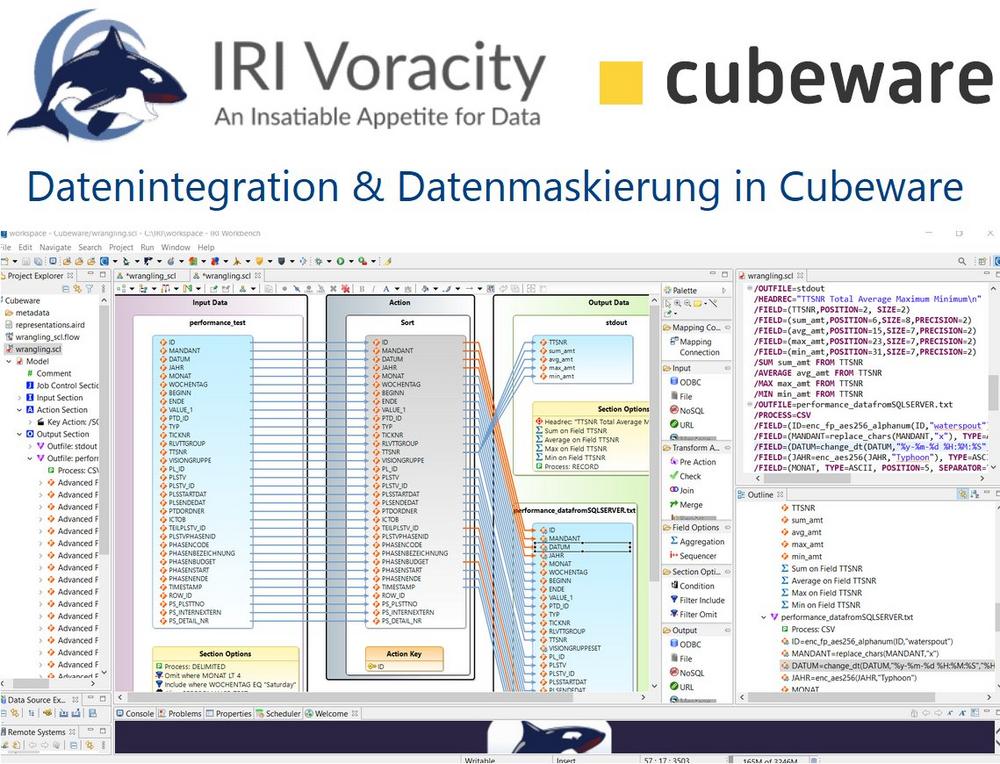
❌ Cubeware ❌ Datenintegration in Cubeware Cockpit beschleunigen und GDPR-konforme Daten für BI-Analysen nutzen ❗
Datenvisualisierung und Erkenntnisse beschleunigen: Cubeware wurde 1997 gegründet und ist ein innovativer Hersteller von BI-Software mit Sitz in Rosenheim, Deutschland. Cubeware bietet Lösungen für Datenmanagement, Visualisierung, Analyse und Planung. Eines der Cubeware Produkte ist Cockpit, der Dashboard-Designer des CSP C8. Cockpit kann Berichte für Windows, Web, Mobile und Snack (Cubeware’s agiles Instant Reporting Tool) erstellen. Es kann auch Daten aus relationalen und multidimensionalen Datenbanken integrieren. In früheren Artikeln im Business Intelligence (BI)-Abschnitt haben wir beschrieben, wie der Umgang mit Daten mit der SortCL-Engine im Datenmanipulationsprodukt IRI CoSort und der Datenverwaltungsplattform Voracity die Zeit bis zur Datenvisualisierung und damit zu verwertbaren Erkenntnissen in BI-Tools verkürzt. In diesem Artikel werden die Vorteile…
-
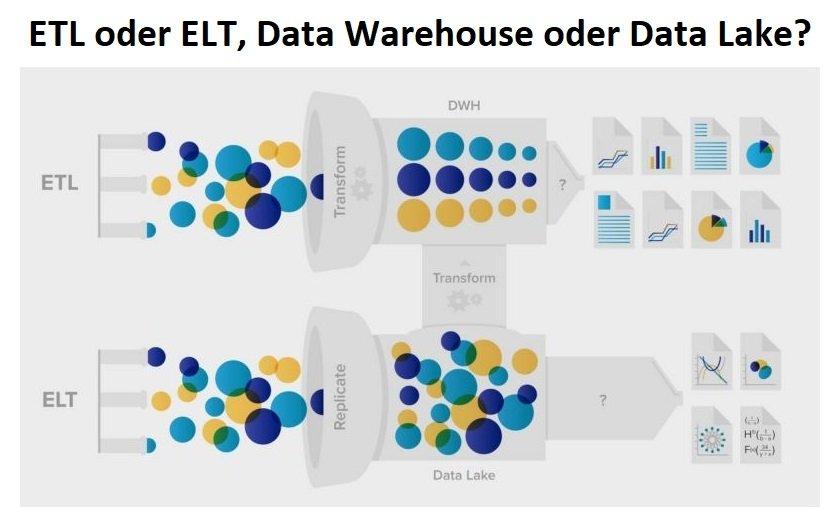
❌ ETL vs. ELT ❌ Effizientere und umfassende Datenintegration und Data Staging bzw. Datenaufbereitung ❗
Wachsendes Datenmengen beherrschen: Data-Warehouse-Architekten (DWA) haben seit ihren Anfängen die Aufgabe, ein Data-Warehouse mit unterschiedlich beschafften und formatierten Daten zu erstellen und zu befüllen. Aufgrund des drastischen Anstiegs der Datenmengen stehen dieselben DWAs vor der Herausforderung, ihre Datenintegrations– und Staging-Vorgänge effizienter zu gestalten. Die Frage, ob die Datentransformation innerhalb oder außerhalb der Zieldatenbank stattfindet, ist aufgrund der damit verbundenen Leistungs-, Komfort- und finanziellen Auswirkungen zu einer kritischen Frage geworden. ETL: Bei ETL-Vorgängen (Extrahieren, Transformieren, Laden) werden Daten aus verschiedenen Quellen extrahiert, separat transformiert und in eine DW-Datenbank und möglicherweise andere Ziele geladen. Bei ELT werden die Extrakte in eine einzige Staging-Datenbank eingespeist, die auch die Umwandlungen übernimmt. ETL ist nach…
-
❌ Data Warehouse ❌ Wachsendes DHW bewältigen ohne zusätzlicher Hardware, Spark oder Hadoop ❗
Push von Datenintegration und Datentransformation! Die meisten ETL- und ELT-Tools und Datenbankmodule können große Datenmengen nicht effizient transformieren, denn sie benötigen: eine teure Parallelverarbeitungs-Edition Entnahme von Datenbank- oder Systemressourcen von Dritten eine komplexe, schwer zu wartende Hadoop-Umgebung eine 6 oder 7-stellige Hardware-Appliance oder Server-Upgrades das Problem auf eine noch teurere Datenbank zu übertragen Es sind die großen Sortier-, Joint- und Aggregationsaufträge, die viel zu lange dauern. Auch nachfolgende Aufgaben wie das Laden, das Analysieren oder die BI-Displays leiden. Zudem werden diese E-, T- und L-Schritte typischerweise in separaten Schritten, I/O-Durchgängen, Produkten oder ständig wechselnden Cloud-Konfigurationen durchgeführt. Lösungen: IRI-Extraktions- und Transformationsprogramme wie FACT oder CoSort und die IRI Voracity Datenmanagement-Plattform können…
-
❌ VLDB ❌ Viel schnellere Datenerfassung für Datenintegration, Datenmigration und Archivierung ❗
7x schnellere Datenerfassung: IRI FACT™ ist ein Dienstprogramm zum parallelen Entladen von sehr großen Datenbanktabellen (VLDB). FACT verwendet einfache Job-Skripte (unterstützt in einer vertrauten Eclipse-GUI), um schnell portable Flat-Files zu erstellen. Die Geschwindigkeit von FACT basiert auf nativen Verbindungsprotokollen und einer proprietären Split-Abfragelogik, die Milliarden von Zeilen in Minuten entladen. IRI FACT verwendet native Datenbank-APIs und parallele Verarbeitung, um Tabellen schneller in Flat-Fiels umzuwandeln als jedes andere Entladetool oder -verfahren. FACT skaliert linear im Volumen, so dass das Entladen einer Zwei-Milliarden-Zeilentabelle nicht mehr als doppelt so lange dauern sollte wie das Entladen einer Ein-Milliarden-Zeilentabelle. Die Kombination der leistungsstarken Extraktion von FACT mit den leistungsstarken, konsolidierten Datentransformationen und vorsortierten Bulkladungen von…
-
❌ Datenverarbeitung ❌ Die bewährte, erschwingliche und schnelle Datenmanagement-Plattform für Big Data ❗
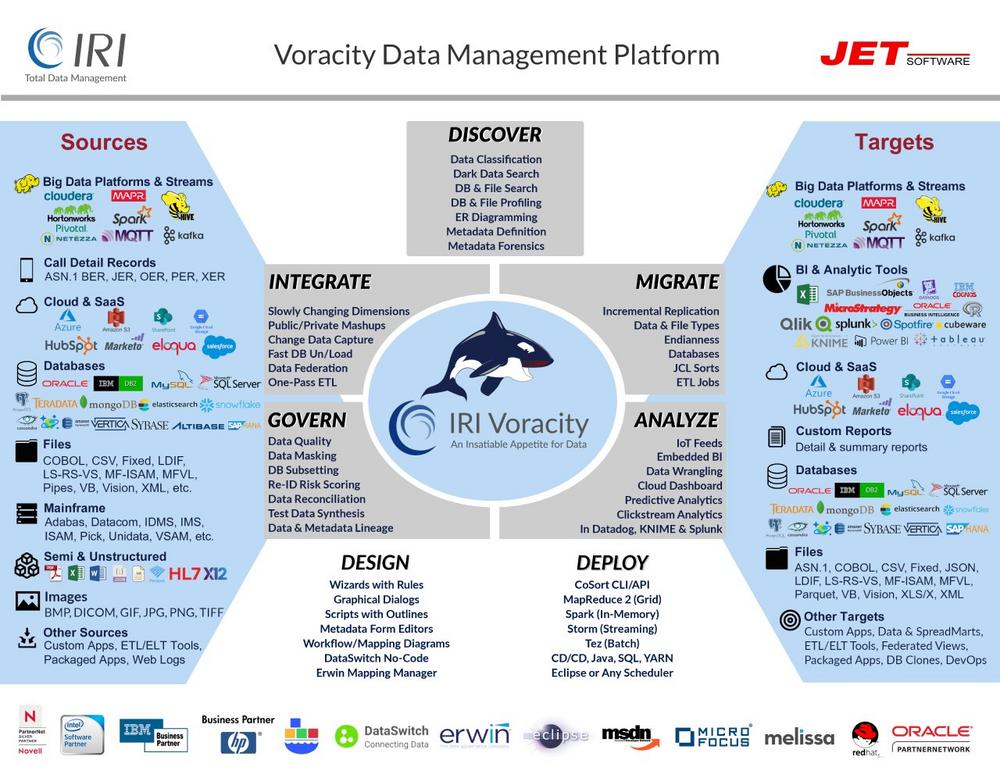
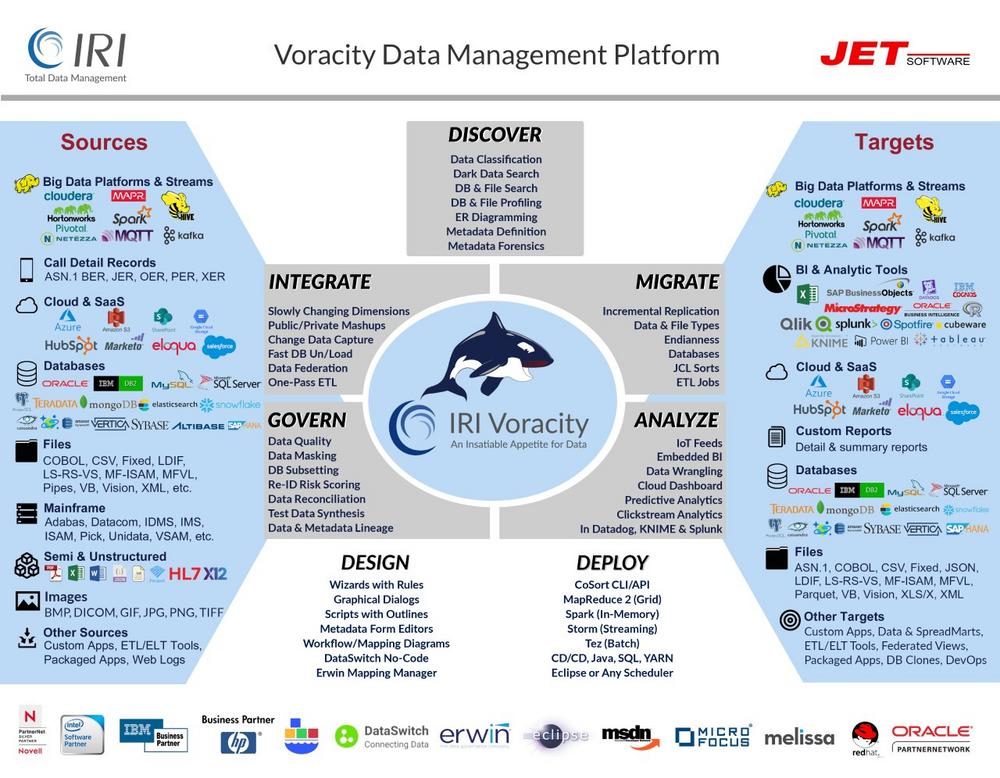
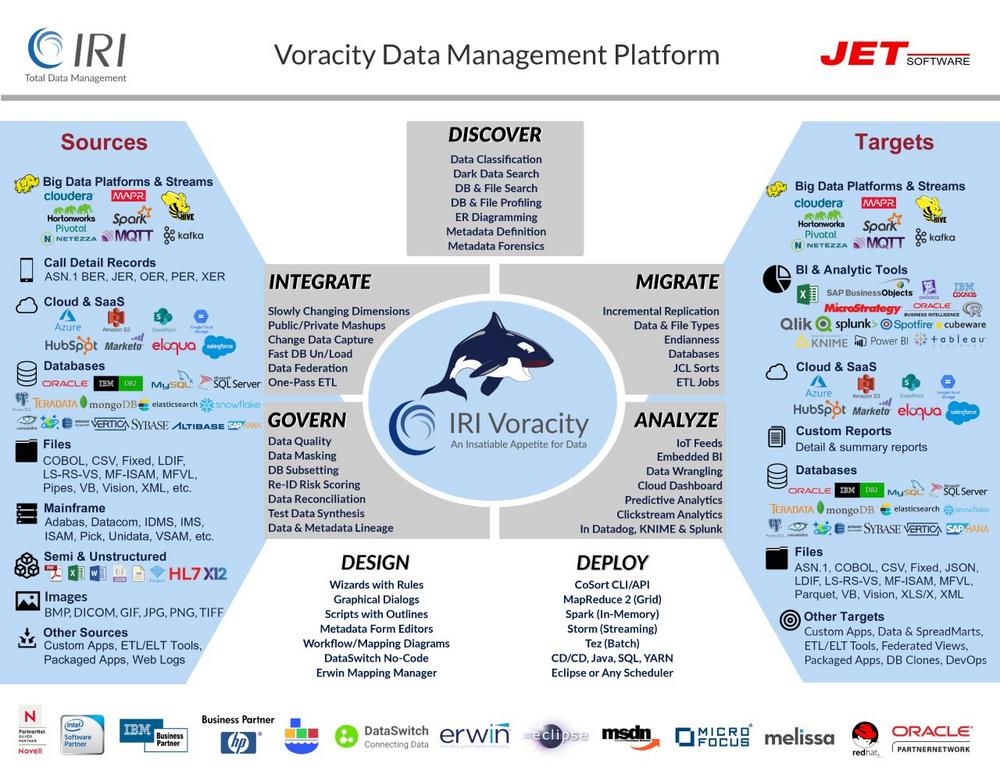
Seit 1978 weltweite Referenzen für Datenmanagement und Sicherheit! IRI Voracity® manipuliert und verwaltet eine riesige Bandbreite und Menge an Daten über eine einzige, auf Eclipse™ basierende Oberfläche. Nutzen Sie Voracity, um schnell und zuverlässig Daten lokal vor Ort oder in der Cloud zu entdecken, zu integrieren, zu migrieren, zu verwalten und zu analysieren und dabei alle "V"-Herausforderungen von Big Data zu bewältigen: VOLUME: Daten aus internen und öffentlichen Quellen wachsen exponentiell. Voracitys langjährig bewährte IRI CoSort-Engine führt und kombiniert Multi-Gigabyte-Transformationen in Sekundenschnelle und übertrifft damit die Geschwindigkeit herkömmlicher Sortier-, BI-, DB- und ETL-Tools um das 2-20fache. VIELSEITIGKEIT: Die Vielzahl an strukturierten und unstrukturierten Quellen übersteigt die Möglichkeiten der meisten Tools.…